The DVC (Distributed Video Coding) provides a theoretical basis for the implementation of light video encoder. Conventionally, lots of studies have been focused on the codec scheme of Stanford University that has a feedback channel to control the bit rate finely. However, the codec scheme can not evaluate the qualities of the frames reconstructed by the received parity bits at the decoder side. This paper presents an efficient method of estimating distortion by correcting the virtual channel noises in side information and then facilitating the measurements of the visual qualities. Through several simulations, it is shown that the proposed method is very efficient in estimating the visual qualities of the reconstructed WZ frames.
기존의 동영상 압축 부호화기는 움직임 추정 예측 부호화를 통하여 매우 높은 부호화 효율을 가지며, 이와 같은 응용분야에 MPEG-1/2/4, H.264 등이 널리 사용되고 있다[1]. 그러나 정보통신의 발달과 더불어 도래되는 하향링크(downlink) 응용 서비스 즉, 무선 저전력 감시카메라, 센서 네트워크 등의 응용 서비스에서는 기존의 높은 복잡도를 갖는 부호화기보다는 저전력 환경을 필요로 한다. 이러한 저전력 환경에 적용하기 위해서는 복잡도가 낮아야 하고 매우 낮은 연산량을 갖는 초경량의 하드웨어로 구축되는 것이 요구된다.
한편, 이러한 초경량 비디오 부호화에 대한 근간이 되는 분산 비디오 부호화(DVC: Distributed Video Coding)기법은 복잡도를 부호화기와 복호화기 사이에 적절히 분산시킬 수 있다는 개념에서 연구되어 오고 있다[2]. 분산 비디오 부호화 기법에서의 저복잡도를 구현할 수 있는 배경은 움직임 추정과 같은 연산량이 많은 부분을 기존의 동영상 압축 부호화 기법들과 달리 복호화기에서 구현할 수 있다는 개념에서 이루어진다. 즉, 움직임추정에 의해 시간축 방향으로 존재하는 정보의 중복성을 찾는 과정을 부호화기에서 수행하는 것이 아니라 복호화기에서 시간축 정보의 중복성을 줄이는 연산을 수행하는 것이다. 이때 현재 부호화기에서 보내려는 프레임을 위너-지브(WZ: Wyner-Ziv) 프레임이라 하고, 복호화기에서 WZ프레임과 매우 유사한 신호 성분을 생성하는데, 이 정보를 보조정보(Side Information)라고 한다[3]. 보조정보는 WZ 프레임과 매우 유사한 신호이지만, 동일하지 않은데, 이것을 가상 채널에 의한 잡음으로 간주한다. 대부분의 경우가 가상채널 잡음은 존재하게 되고, 가상 채널에서 발생된 잡음의 위치와 양을 정확하게 파악하는 것은 현실적으로 불가능하다. 그래서 수신측에서 가상채널 잡음으로 인해 발생되는 왜곡을 복구 가능하도록 하기 위해 WZ 프레임을 채널 부호화하여 발생되는 패리티 정보를 수신측의 적정한 요구량에 맞추어 전송하고, 수신측에서는 보조정보에 포함된 왜곡 신호를 효과적으로 복구하는데 사용한다. 이때 이 잡음의 양이 적으면 적을수록 전송되는 패리티 비트 요구량은 감소하고, 그렇지 않은 경우에는 증가하게 된다. 기존에는 이와 같이 수신측에서 채널복호화를 수행한 후에 복호화된 결과에 따라 비트량을 조절하는 방식을 주로 사용하여 왔다[4].
이러한 기존의 피드백 제어에 의해 패리티 비트량을 결정하는 방법은 스탠포드대학교의 연구 결과를 기초로 하여 발전되어 온 것으로서 반복적인 피드백으로 인해 매우 정확한 비트량 제어가 가능하다[5]. 그러나 완전히 복호가 되지 않은 경우에 추가적으로 패리티 비트량을 요구하게 되는데, 추가로 전송받은 패리티 비트를 이용하여 에러정정을 한 후 그 결과에 따라 패리티 비트의 추가 전송 여부를 다시 결정하게 된다. 이러한 반복적인 연산을 수행하는 피드백 채널의 특성상 패리티 비트 재전송 및 에러 정정 하는 부분이 분산 비디오 복호화 전체 복잡도의 매우 많은 부분을 차지하고 있으나 실제 전송 비트량에 따라 화질이 어느 정도 개선되는지 알 수가 없다. 본 논문에서는 화소영역 위너-지브(PDWZ: Pixel-Domain Wyner-Ziv) 비디오 코덱을 이용하고, 각 비트플레인을 전송함으로써 보정되는 가상 채널 잡음의 양에 따라 개선되는 왜곡의 모델을 구하고, 이를 통하여 왜곡과 전송되는 비트량의 관계식을 이용하여 왜곡-비트량을 제어할 수 있는 새로운 방법을 제안한다.
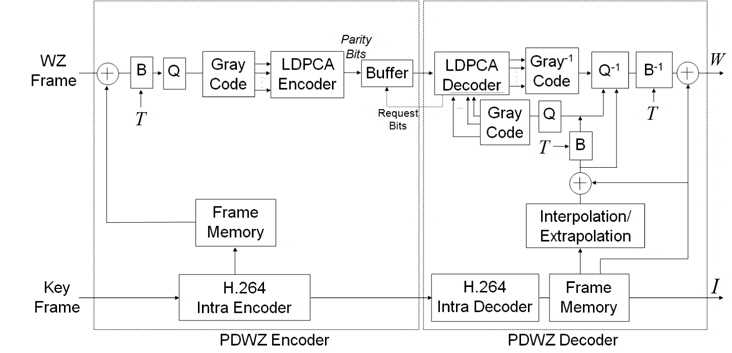
그림 1은 화소영역에서 구현된 화면 간 잔차 신호를 이용한 위너-지브 비디오 코덱의 구조도를 나타내고 있다[6,7]. 기존의 코덱과 동일하게 비디오 시퀀스는 키 프레임과 위너-지브 프레임들로 분리되어 부호화된다. 키프레임은 복잡도가 낮은 화면내 부호화 기법으로 부호화되어 전송되고 동시에 복원된 형태를 프레임 메모리에 저장한다. 위너-지브(WZ) 프레임은 프레임 메모리에 저장된 키 프레임의 복원된 형태를 참조하여 화면 간 차이 신호를 구하여 채널 부호화하여 전송된다. 이때 복호화기의 복잡도를 증가시키지 않도록 하기 위해 단순히 WZ 프레임과 이전 복원된 키 프레임 사이의 화소 간 밝기 차이로 구해진다. 밝기 값이 n비트로 표현되면, 밝기 차이 값(r)의 범위는 -2n+1에서 부터 2n+1까지의 값을 가지게 된다. 이 값들의 분포는 라플라시안 분포를 갖게 되며, 중요 상위 비트(MSB: Most Significant Bit)가 가상채널잡음이 자주 발생하지 않도록 하기 위해 양수의 값(P)으로 치환한다.
여기서 T는 라플라시안 통계 분포에 기초하여 결정되는 양자화 깊이 값에 의해 결정되는 이동 값이고, %는 모듈로 연산자이다. 즉, 본 논문에서는 [6]에서 T에대한 최적의 값으로서 3x2n-m으로 선택하며, m은 비트 버림(bit truncation)에 의한 비트플레인의 개수를 의미한다. (1)에서 P의 값은 (n+1)비트로 표현되며 (n+1)비트 중에서 하위 m개의 비트는 비트 버림으로 전송을 하지 않고, 상위 (n+1-m)개의 비트만 전송한다. 전송을 위해 (n+1-m)개의 상위 비트는 그레이 코드로 변환되어 전송한다. 이것은 이웃하는 상위 비트간에 유사성을 고려하여 가상 채널 잡음의 양을 최소화하기 위해 도입된 것으로서 패리티 비트 생성하게 된다. 생성된 패리티 비트는 수신측의 요구에 따라 전송한다.
복호화기에서는 화면 내 부호화모드로 부호화된 키프레임을 복호화하여 프레임 메모리에 저장한다. 이들의 키 프레임 정보를 이용하여 움직임 보상 보간에 의해 보조정보(SI: Side Information)가 생성된다. 생성된 보조정보는 송신측의 WZ 프레임과 동일하지 않은데 송신측에서 (n+1-m)비트 개수만큼의 비트 플레인으로 전송되는 프레임을 위해 부호화기와 반대의 과정으로 복원된다. 즉, (1)의 과정이 보조정보에 대해 적용되고, 그레이코드로 변환된다. 상위 비트 플레인에 대한 그레이코드가 순차적으로 수신되면, 가상채널잡음에 대해 보정이 이루어지고, 보정된 코드는 다시 그레이코드에서 이진코드로 변환된다. 전송되지 않은 m비트에 대한 정보와의 왜곡을 최소화하기 위해 보조정보와 비교하여 선택하도록 한다[6]. 이렇게 해서 복원된 (n+1)비트의 값는 다음의 관계식을 이용하여 잔차 신호를 얻는다.
여기서 는 (1)에 대한 복원된 값이며, 이 값에 프레임 메모리에 있는 키 프레임을 더함으로써 복원이 완료된다.
그림 1에 나타낸 잔차 신호를 이용한 화소영역 위너-지브 비디오 코덱에서 발생되는 잔차 신호의 통계적인 분포특성은 라플라시안 분포를 나타난다. 분포적인 특성으로 보면, 0을 중심으로 대칭적이고, 0 근처에 매우 높은 집중도를 갖는다. 특히, 그림 1에 나타낸 잔차 신호에 대한 분산비디오 코덱에서는 가상채널잡음에 따라 MSB(최상위) 비트는 부호비트로서 매우 중요한 정보를 갖게 되며, 이 비트의 오류는 치명적인 화질 저하를 야기할 수 있다. 반면에 LSB로 이동할수록 화질 저하 효과는 낮게 나타난다.
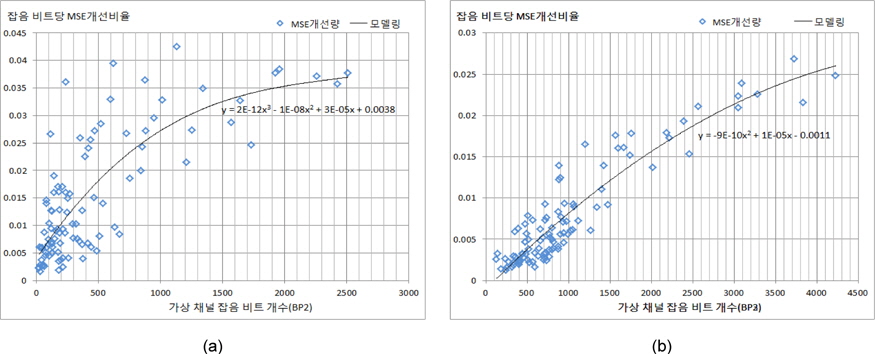
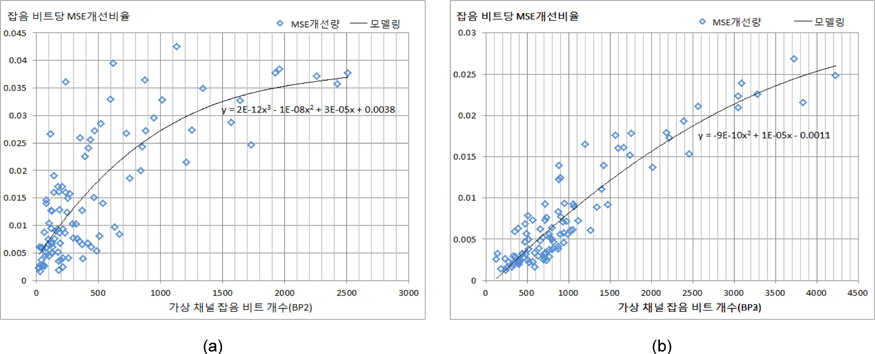
본 논문에서는 각 비트 플레인별 나타나는 가상 채널 잡음에 따른 화질에 미치는 영향을 조사하기 위해 Container시퀀스 (QCIF, 201프레임)에 대해 모의실험을 수행하였다. 8비트로 표현되는 화소 기준으로 잔차신호는 9비트로 표현되며, 이때 MSB 비트와 (MSB-1)비트에서 발생된 잡음은 화질에 매우 큰 영향을 미친다. 이와 같은 효과로 인해 대부분의 분산비디오 부호화기법에서는 MSB비트와 (MSB-1)비트는 반드시 전송하는 것으로 가정하여 왜곡 모델링에서 제외한다. 모의실험에 의해 MSB 비트 플레인에서는 비트당 MSE개선 효과가 2에 달하고, (MSB-1) 비트플레인에서는 최대 0.5까지 개선되고, 평균적으로 비트당 개선되는 MSE크 기는 0.6과 0.06으로서 약 10배 정도의 차이가 있다. 가장 흔히 사용되는 응용 분야에서는 최소한의 화질을 제공하기 위해서는 MSB 비트와 (MSB-1) 비트에서 발생되는 채널잡음은 화질에 절대적인 영향을 주게 되므로, 본 논문에서는 비트율 제어 대상에서 제외한다. 따라서 (MSB-2) 비트 플레인 이하에서 각 비트 플레인에서 발생되는 가상 채널 잡음 비트의 개수에 따른 잡음 비트당 MSE(Mean Square Error) 개선 정도를 조사하였고, 그 결과를 그림 2와 그림 3에 각각 나타내었다. 이 결과에서 알 수 있듯이 LDPCA로 부호화되어 전송되는 패리티 비트는 가상 채널 잡음이 다량으로 발생되는 경우에 그 비트들을 잡음으로부터 보정함으로써 MSE 개선효과가 크게 나타나는 것을 알 수 있다. 또한 (MSB-2)비트 플레인과 (MSB-3) 비트 플레인에서 MSE개선 효과가 평균적으로 0.01과 0.008로써 상위 비트 플레인인(MSB-2)의 효과가 크게 됨을 확인할 수 있다. 그러나, (MSB-2) 비트 플레인에서는 잡음의 양이 증가할수록 다소 개선 정도가 증가하지만 다른 비트 플레인에 비해 산만하게 흩어져 있음을 보인다. (MSB-3) 비트 플레인에서는 (MSB-2) 비트 플레인에 비해 잡음 비트당 MSE 개선 정도가 집중되어 모델링될 수 있음을 보인다.
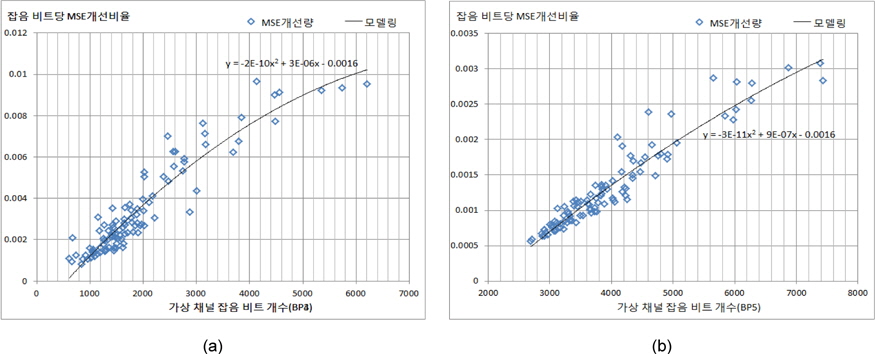
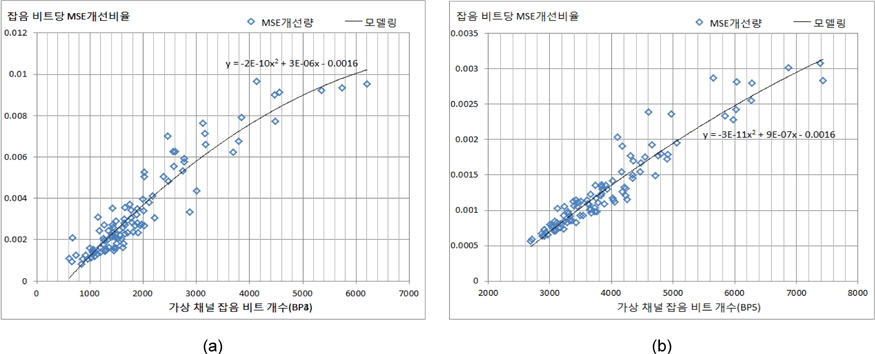
그림 3에서는 (MSB-4) 비트플레인과 (MSB-5) 비트 플레인에서의 가상 채널 잡음의 개수에 따라 패리티 비트에 의해 보정되는 MSE개선 크기를 각각 나타내고 있으며, 평균적으로 0.003과 0.001의 MSE 개선효과를 얻게 된다. 최상위 비트플레인에서 점진적으로 멀어질수록 가상채널잡음 1비트에 따른 MSB 개선효과는 감쇄하게 된다. 이러한 특성을 고려한 비트율-왜곡 모델링이 수행될 필요가 있다.
그림 2와 그림 3에서 나타나는 각 비트 플레인에서 관찰된 특성을 다차원 다항식 모델링을 수행한 결과는 다음과 같이 요약된다.
여기서, y는 가상채널잡음의 한 비트당 개선되는 MSE크기를 나타내고, x는 주어진 비트 플레인에서 발생된 가상채널잡음 비트 개수를 나타낸다.
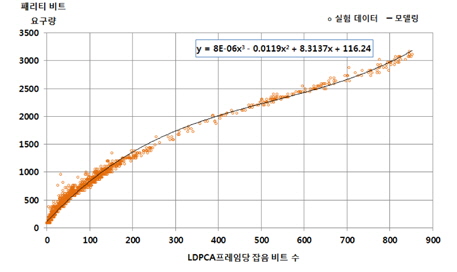
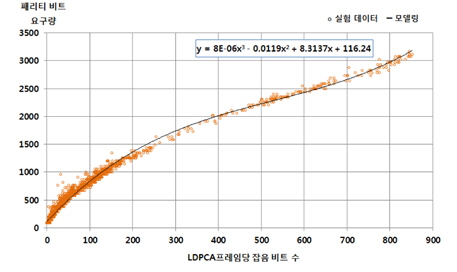
가상채널 잡음의 양이 증가할수록 패리티 요구량은 증가한다. 피드백 제어 방식에 의해 요구되는 패리티비트 요구량은 가상채널 잡음의 양에 비례한다. 모의실험에 따른 그림 2와 그림 3에서 관찰된 가상 채널 잡음 비트의 개수에 따른 패리티 비트 요구량은 그림 4와 같다. 모의실험에 의한 실험데이터는 매우 규칙적으로 밀집된 현상을 갖게 되며, 모델링이 용이한 형태로 나타나고 있다. 이에 따른 모델링 식은 3차 다항식으로 다음과 같이 표현된다.
여기서 x는 LDPCA 프레임에 발생된 잡음 비트 개수를 나타내고, 패리티 비트 요구량은 y로 표현된다.
가상채널 잡음을 패리티 비트로 보정함으로써 왜곡(MSE)이 개선되는 정도를 조사하기 위해 Foreman시퀀스와 Salesman시퀀스(QCIF, 100프레임)을 각각 사용하였다. II장에서 설명한 그림 1의 동작 방식을 그대로 구현하였고, 각 비트 플레인이 수신하면, 보정된 가상 채널 잡음 비트 개수를 측정하여 식(3) - (6)에 의한 방식으로 개선된 왜곡량을 예측하고, 실제 영상과 비교함으로써 측정하였다.
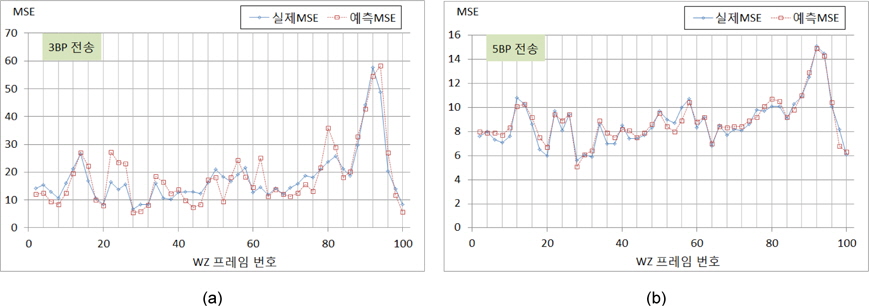
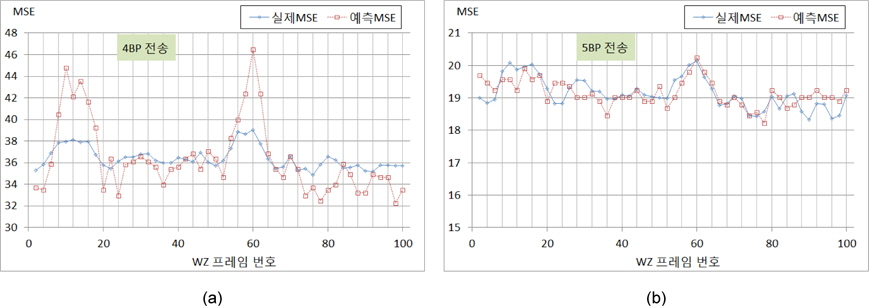
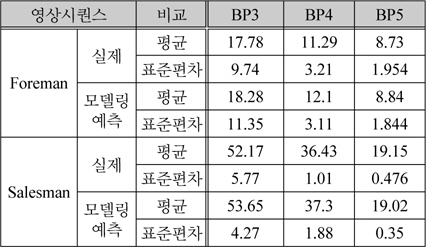
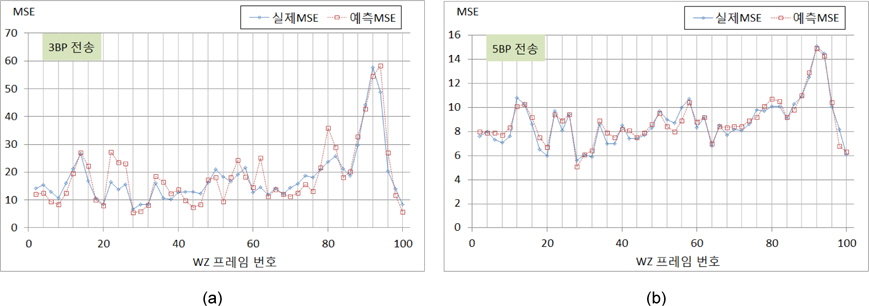
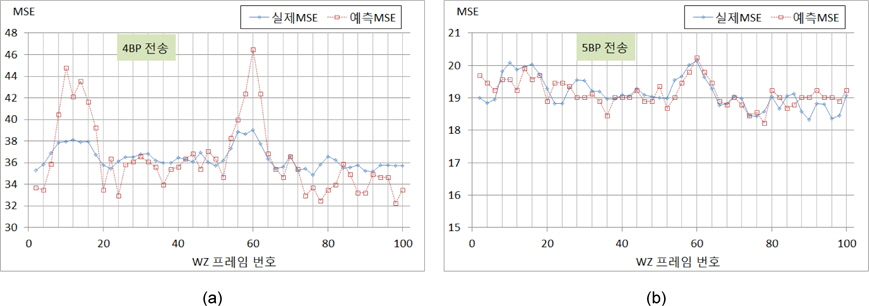
Foreman시퀀스에 대해 QP값을 25로 고정시키고, 홀수 번째 프레임을 H.264 화면내 부호화 기법으로 부호화하여 전송하고 [3]에서 제시된 방식으로 보조정보를 생성하여 위너-지브 프레임을 복원하였다. 그림 5 (a)와 (b)는 MSB 비트 플레인부터 3개 그리고 5개를 각각 전송하였을 때 개선되어 얻어진 실제 MSE값과 예측 MSE를 나타내고 있다. 모의실험 결과에 따라 제안한 방식은 매우 효과적임을 보이고 있으며, 3BP를 전송할 때는 다소 편차가 많이 발생하지만, 5BP를 전송함으로써 편차도 많이 개선됨을 확인할 수 있다. 그림 6은 Salesman시퀀스에 대해 QP값을 38로 고정시키고 홀수 번째 프레임을 화면내 부호화기법으로 부호화하여 전송한 경우에 대한 실험을 나타내고 있다. 이 실험 결과에서도 알수 있듯이 제안한 다항식 근사화에 의한 방식으로 전체적으로 실제 MSE를 잘 예측할 수 있음을 알 수 있다. 그러나 4개의 비트 플레인을 전송하는 경우에 변동성이 있는 경우에 오차가 크게 나타나고 있지만, 5개의 비트 플레인을 전송하는 경우에는 왜곡의 크기를 다소 정확하게 예측할 수 있음을 보인다. 그림 4와 그림 5의 모의실험 결과에 대한 MSE예측 성능 결과를 표 1에 나타내고 있다. 여기서, 전송된 비트플레인은 각각 3개(BP3), 4개(BP5), 그리고 5개(BP5)로 각각 수행하였고, 제안한 방식은 실제 발생된 왜곡을 낮은 편차를 갖고서 예측될수 있음을 보인다. 사용된 양자화 계단 크기와 더불어 화면 복잡도에 의존적인 결과를 보이고 있음을 보이지만 상대적으로 Salesman시퀀스에 대한 정확도가 우수함을 확인할 수 있다.
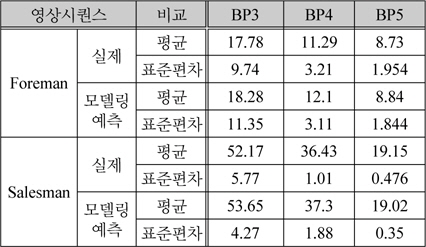
왜곡(MSE) 예측 성능 비교
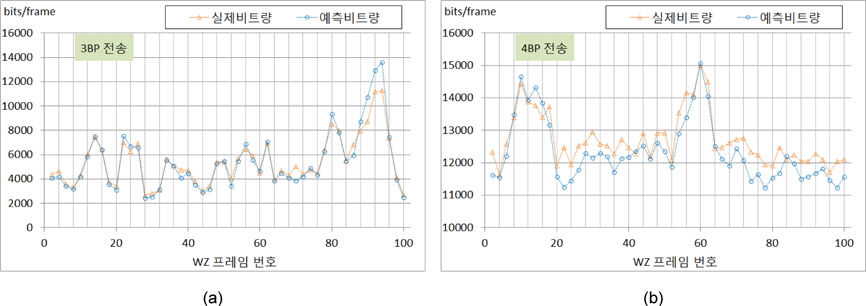
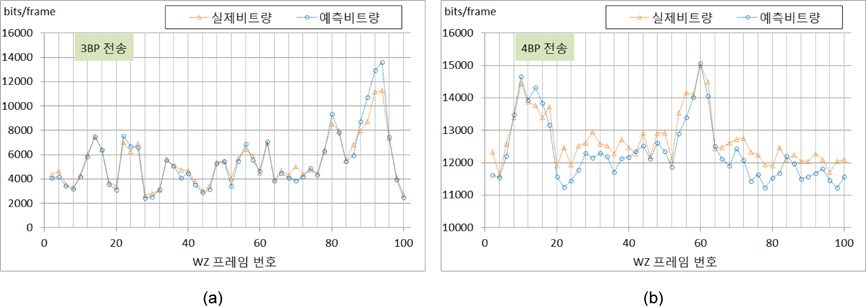
한편, 그림 7은 Foreman시퀀스와 Salesman시퀀스에 대해 그림 4에 나타낸 비트 요구량에 대한 다항식 모델을 사용하여 예측한 실험 결과를 보여주고 있다. Foreman시퀀스와 같이 3개의 비트 플레인을 전송하는 경우에는 잡음 비트량이 작고, 또한 전송 비트량이 적게 발생함에 따라 프레임당 발생되는 비트 요구량을 거의 정확하게 예측함을 알 수 있다. 반면에, 4개의 비트 플레인을 전송하고 QP=38로 사용한 Salesman시퀀스의 경우에는 잡음의 양이 매우 증가하고 이로인해 전송되는 비트량의 증가함과 동시에 프레임당 예측량의 편차가 크게 나타남을 보인다. 그러나 본 논문에서 사용한 식(7)에 의한 다항식 모델링이 효과적인 결과를 얻을수 있음을 보인다.
기존에 연구되어온 분산비디오 부호화 기법은 대부분 패리티 비트 요구량을 피드백 제어로 수행하고 있다. 이 방식은 비트량을 정확하게 제어하는데 효과적이지만 왜곡량에 대해서는 예측 방법을 제시하지 못하고 있는 한계점이 있다. 본 논문에서는 이러한 기존 연구의 한계를 극복하기 위해 화소영역 분산비디오 부호화기법에서 각 비트 플레인이 수신됨에따라 보정되는 가상채널 잡음 비트의 개수에 따라 왜곡을 예측할 수있는 기법을 제안하였다. 또한, 가상 채널 잡음 비트 수에 따른 프레임별 비트량을 예측하는 방법을 제안하였다. 본 논문에서 제안한 가상 채널 잡음 비트 개수에 따른 왜곡 개선량과 패리티 비트 요구량은 각각 다차원 다항식으로 모델링되었으며, 모의실험을 통하여 제안한 방식이 매우 효과적으로 적용될 수 있음을 검증하였다.
본 논문에서 제안한 방식은 화소영역으로 고안되었으나 변환영역으로 확장할 수 있을 것으로 기대된다. 또한 전송채널이 가변적인 경우에 비트율-왜곡의 최적화에 효과적으로 적용될 수 있으며, 전송되는 비디오시퀀스의 특징에 따라 성능 최적화에 대한 기법이 계속적으로 연구될 필요가 있다.

![화면 간 차이신호를 이용한 화소영역 위너-지브 비디오 코덱의 블록구조도[6]](http://oak.go.kr/repository/journal/14046/HOJBC0_2014_v18n4_891_f001.jpg)