Computer-generated hologram (CGH) is to mathematically model optical phenomenon with digital computer. Because it requires huge amount of computational power, a fast and high performance technique is needed. In this paper, we proposed two parallelizations for CGH calculation. The first is to parallelize CGH algorithm in a GPU (general processing unit) and the second is to parallelize multiple GPUs. The proposed algorithm was implemented in GTX780 Ti GPU. It calculates a 1,024×1,024 hologram with 10K object points for about 24ms.
CGH를 이용하여 하나의 홀로그램을 생성하기 위해서는 많은 연산량이 필요하다[1]. 고속의 홀로그램 생성을 위한 연구는 크게 두 가지로 분류된다. 그중 하나로는 FPGA를 이용한 하드웨어로의 구현[2-6]한 것이고, 다른 한 가지는 GPU를 이용한 병렬 프로그램을 이용한 하는 것이다[7-12].
FPGA를 이용한 방법으로는 CGH를 연산하기 위한 전용 연산 시스템인 HORN-6가 연구되었다[3]. 100% 파이프라인 구조를 기반으로 하는 CGH 프로세서에 대한 연구도 진행되었다[4]. 이 연구에서는 프레넬 변환을 수행하기 위한 CGH 셀의 하드웨어 구조를 제안한 후에 이를 확장하여 CGH 커널을 구성하였고, 이를 다시 확장하여 CGH 프로세서를 구현하였다. [4]의 하드웨어는[2]보다 최대 87.32%의 높은 성능을 갖는다. [5]의 논문에서 제안된 FPGA 기반의 하드웨어는 1,920×1,080 크기의 HD급의 홀로그램을 실시간으로 생성할 수 있다. [6]의 논문에서는 메모리 접근을 줄일 수 있는 하드웨어 구조 및 동작 방식을 제안하여 [5]에서 제안된 하드웨어에 비해서 메모리 접근 횟수를 약 2,000배 감소시켰다.
GPU를 이용한 방법으로 싱가폴대[9]는 CGH 수식을 복소 형태로 변환한 후에 연산을 분리하는 알고리즘을 제안하였다. 분리된 항을 각각 룩업 테이블(look-up table, LUT)로 만든 후에 연산을 고속화시키고, GPU로 구현하였다. 1K개의 광원으로 구성된 객체에 대해 1,024×768크기의 홀로그램을 0.3초당 한 장씩 생성할 수 있었다. 중국 Zhongshan 대학의 Wang[10]은 GPU를 이용하여 3D 메쉬 모델 기반의 CGH를 생성하였다. 또한 일본 Chiba대의 Shimobaba[11]는 AMD의 GPU를 기반의 GPU 프로그래밍 기법을 활용하여 CGH 생성을 고속화하였고, HD크기의 홀로그램을 0.31초당 한 장씩 생성할 수 있었다. 광운대는 광원 및 홀로그램의 블록화를 통해서 GPU를 최적으로 이용할 수 있는 연구와 GPU 내부의 다양한 메모리의 사용에 따른 CGH의 효율성을 분석하여 성능을 향상시키고자 시도하였다[12]. 최근에는 OpenMP 기반의 CPU 병렬화 기법을 이용하여 다수의 GPU를 병렬적으로 동작시켜서 CGH의 성능을 향상시키는 연구들이 수행되어 오고 있다. 한양대[13]에서는 OpenMP를 활용한 두 개의 GPU를 이용하여 병렬 동작의 최적화 방법을 제안하여 CPU대비 9,700배의 성능 개선을 할 수 있었다. 광운대[14]에서는 외부 확장 장치를 이용하여 4개의 고성능 GPU를 병렬화하여 컬러 홀로그램을 고속으로 생성하는 시스템을 제안하고 구현하였다. 본 논문에서는 고속의 CGH연산을 GPU를 이용할 때 적용시킬 수 있는 성능의 개선 방법과 GPU의 자원에 할당에 따른 최적의 연산방법에 대해 논의한다.
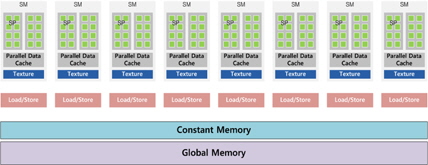
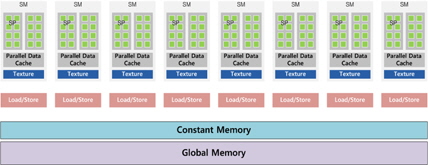
고성능 제어기와 적은 ALU(Arithmetic and Logic Unit)을 가지는 CPU의 구조와는 달리 GPGPU는 그림 1과 같이 작은 컨트롤 유닛과 다수의 ALU를 포함하고 있어 연산 능력에서 병렬화에 유리한 구조를 가진다. 그림 1과 같이 하나의 GPU내에는 하나의 전역메모리와 여러 개의 SM(streaming multiprocessor) 및 적재/저장 유닛 등을 가지고 있다. 하나의 SM은 여러 개의 SP(streaming processor)와 공유메모리 등으로 이루어져 있고, SP는 하나 혹은 다수의 쓰레드를 동작을 수행할 수 있다. GPU내의 전역메모리는 저장할 수 있는 데이터량은 크지만 여러 SM이 동시에 접근하기 어렵고 대기지연 시간도 비교적 길기 때문에 비교적 낮은 성능을 갖는다. 하지만 캐시 형태로 되어 있는 상수메모리(Constant Memory)나 SM 내부의 공유메모리는 저장할 수 있는 데이터량은 적지만 전역메모리에 비해서 접근 속도가 빠르다. 따라서 많이 호출되어 사용되는 변수들은 상수 메모리나 공유 메모리를 사용하는 것이 유리하다[15].
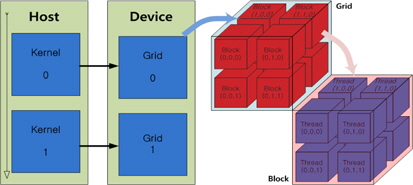
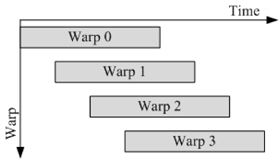
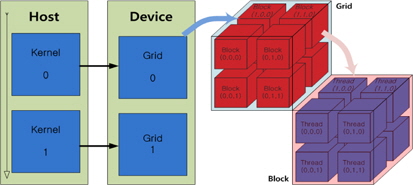
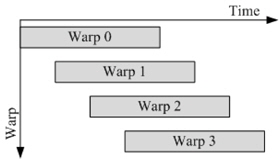
본 논문에서 사용한 병렬 프로그래밍 언어인 CUDA는 쓰레드와 블록, 및 그리드 단위로 GPU내의 연산 단위를 구분한다. 그림 2와 같이 하나의 블록은 3차원의 쓰레드로 구성할 수 있고, 하나의 그리드는 3차원의 블록으로 구성할 수 있다. 각 쓰레드는 GPU내의 SP에 맵핑되며 연산하는 최소 단위로 하나의 블록 내의 최대 쓰레드의 개수는 GPU의 성능에 따라 결정된다. 또한 블록 내에 구성된 쓰레드는 인덱스를 가지고, 그림 3과 같이 워프(warp) 단위로 실행된다. 따라서 모든 쓰레드를 효율적으로 동작시키기 위해서는 블록 당 쓰레드의 개수를 워프의 배수로 하는 것이 유리하다[15].
각 블록은 블록내의 쓰레드에 따라서 하나 혹은 그이상의 블록이 하나의 SM으로 맵핑되어 동작한다. 블록내의 모든 쓰레드 내에 할당된 레지스터의 개수가 SM내의 총 레지스터의 개수이하로 될 경우 최대의 블록으로 할당할 수 있다. 또한 블록도 쓰레드와 같이 인덱스를 가지게 되며 모든 SM에 할당된 블록의 개수가 그리드당 총 블록의 수보다 적을 경우 모든 할당된 블록의 동작이 끝난 뒤 남은 블록들이 동작이 이루어진다.
홀로그램은 광학계를 이용하여도 취득할 수 있지만 광학계 자체를 수학적으로 모델링한 연산에 의해서 구할 수도 있다. 이러한 수학적인 연산을 통해 얻어진 홀로그램을 컴퓨터 생성 홀로그램(computer-generated hologram, CGH)이라고 한다[12,14].
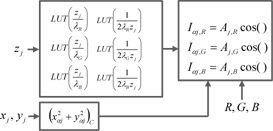
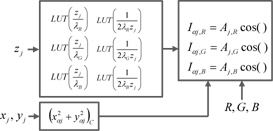
CGH는 식 (1)과 같이 정의되는데 홀로그램의 위상으로부터 홀로그램의 강도(
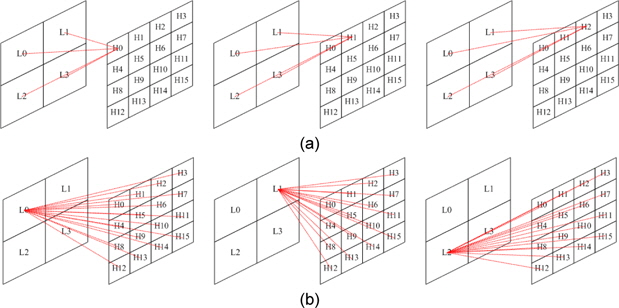
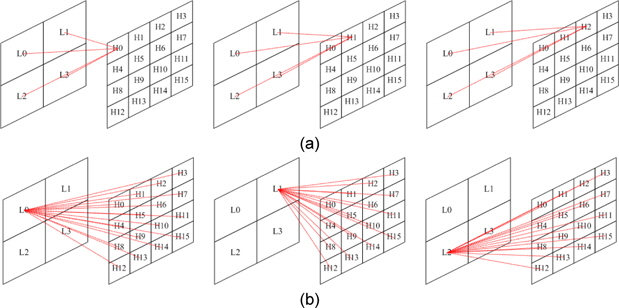
식 (2)와 같이 CGH 수식은 방대한 반복 연산이 이루어진다. 따라서 GPU를 이용하여 병렬 연산을 수행할 경우 속도를 향상 시킬 수 있다. 그림 5에 식 (2)를 이용하여 CGH 연산 방식에 대하여 나타내었다. 그림 5(a)는 하나의 홀로그램 화소를 모든 유효 광원에 대하여 병렬로 연산하는 방법으로 연산 결과를 누적 덧셈이 필요하다. 따라서 연산 결과를 다시 메모리에 저장해야 하기 때문에 메모리 접근 횟수가 늘어나게 되어 속도가 저하된다. 또한 많은 메모리 접근으로 인하여 메모리 병목 현상이 생기게 된다. 그림 5(b)는 유효광원을 모든 홀로그램 화소에 대하여 병렬로 연산하는 방식으로 GPU의 하나의 레지스터에 모든 입력광원에 대하여 연산이 끝날 때까지 누적할 수 있기 때문에 메모리 접근이 줄게 된다. 따라서 모든 GPU의 쓰레드는 홀로그램 화소에 대하여 맵핑되어 연산을 하는 것이 유리하다.
식 (2)에서 입력되는 광원이
식 (2)에서 홀로그램의 화소를 계산하기 위해서는 광원과 홀로그램 화소간의 위치에 관한 항과 광원의 세기의 곱을 누적덧셈을 통하여 구한다. 하지만 화소의 세기가 ‘0’일 경우 위치에 관한 연산에 독립적으로 누적값이 ‘0’이므로 이는 유효하지 않은 광원이 된다. 따라서 유효 광원만 분리하여 GPU에 데이터를 전송하고 연산함으로써 연산 속도를 향상 시킬 수 있다[12].
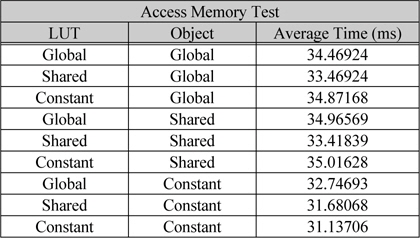
홀로그램 한 프레임에 대하여 연산할 때 광원에 대한 데이터는 많은 접근을 한다. 따라서 전역 메모리 보다는 캐시 형태로 되어있는 상수 메모리(constant memory) 또는 공유메모리(shared memory)를 통한 데이터 전송을 통하여 속도를 향상 시킬 수 있다. 접근 속도가 가장 빠른 것은 공유 메모리에 대한 접근이지만 광원에 대한 데이터는 각 쓰레드에서 한번만 접근하기 때문에 전역 메모리에서 한번 적재시켜 반복적으로 사용되는 공유메모리의 사용은 오히려 전역 메모리에서 한번 적재시켜 연산하는 방법에 비하여 느려진다. 따라서 호스트에서 상수 메모리로 데이터를 전송하고 상수 메모리에서 한번만 적재하여 연산하는 방법을 사용하는 것이 속도 향상을 시킬 수 있다. 하지만 상수 메모리 또한 저장할 수 있는 데이터 량이 제한되어 있기 때문에 메모리 크기와 GPU의 개수에 따라 유효 광원을 타일링하여 전송 해야한다. 그림 5에서 입력 광원에서 유효광원을 타일링하는 방법에 대하여 나타내었다. 그림 5(a)는 유효 광원과 GPU의 개수에 따른 타일링 방법으로 광원의 세기가 ‘0’이 아닌 광원의 데이터를 GPU의 ID에 따라 나누어 준다. 그림 5(b)는 상수 메모리의 크기 또는 연산 속도에 따라 해당 ID의 광원 버퍼를 타일링하는 방법이다. 표 1 GPU의 메모리 종류에 따라 1K의 유효 광원에 따른 1024×]024의 홀로그램을 생성할 때의 시간을 측정한 결과이다. 초기 파라미터 LUT의 계산 시간과 데이터 전송시간을 제외한 20프레임의 홀로그램을 생성하였을 때 평균 시간에 해당한다. LUT와 광원의 메모리를 모두 상수 메모리에 저장을 하고 연산하는 방법이 31.137ms로 가장 효율 적으로 연산하는 결과를 보였다[12].
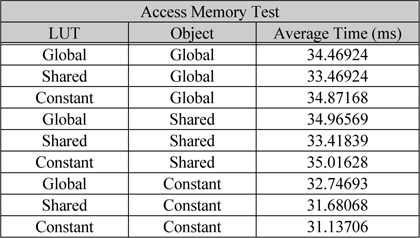
메모리 종류에 따른 평균 연산 시간
앞 절에서 홀로그램의 화소에 대하여 쓰레드를 맵핑하는 것이 유리하다는 것을 보였다. 하나의 쓰레드에서는 최소 상수 메모리에서 읽어온 데이터를 저장할 4개(
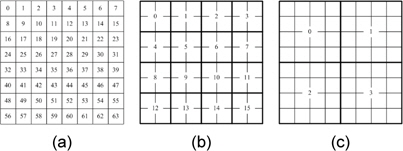
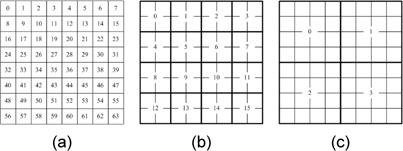
그림 6에 쓰레드당 맵핑되는 홀로그램 화소를 나타내었다. 그림 6(a)는 각 쓰레드에 하나의 홀로그램 화소 하나씩 맵핑되고 (b)는 각 쓰레드에서 2×2블록을 연산하는 방법이고 (c)는 4x4 블록을 연산한다. (b)의 방법에서 쓰레드당 사용하는 레지스터는 20개이고 (c)의 방법은 48개의 레지스터를 사용한다.
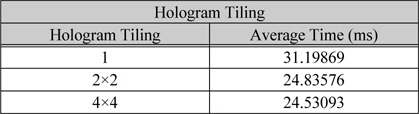
표 2는 쓰레드당 홀로그램 화소를 타일링하여 맵핑하였을 때 연산 시간에 대한 결과이다. 1K광원에 대하여 1,024×1,024 홀로그램을 생성하며 상수 메모리를 사용하고 블록당 512개의 쓰레드를 할당하였다. 블록당 최대 레지스터는 32,768이고 블록의 크기를 512개 이므로 쓰레드당 최대 64개의 레지스터를 할당 할 수 있다. 따라서 쓰레드당 4×4블록을 연산을 할 경우 48개의 레지스터를 사용한다. 또한 SM당 3개의 블록이고 총 16개의 SM이 존재하기 때문에 한 번에 연산할 수 있는 총 화소의 개수는 393,216개의 화소를 연산할 수 있다. 따라서 1,024×1,024의 홀로그램을 생성하기 위해서는 총 2.67번의 연산을 수행해야한다. 만약 한 번에 연산할 수 있는 총 화소의 개수가 홀로그램의 총 화소의 개수보다 적을 경우 최대 효율을 내기 어렵다. 따라서 최소의 화소의 개수 보다는 커야 한다[12].
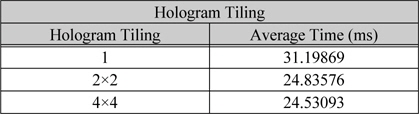
홀로그램 타일링에 따른 평균 연산 시간
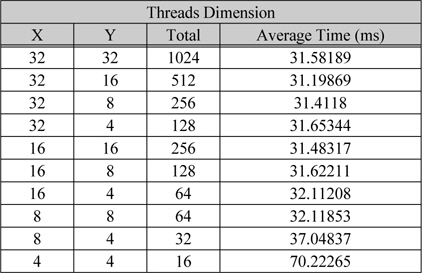
표 3은 블록당 쓰레드의 개수에 따라 1K광원으로 1,024×1,024홀로그램을 상수 메모리를 이용하여 생성한 결과에 대한 연산 시간이다. GTX 780Ti은 SM당 2048개의 SP를 가지고 있기 때문에 하나의 블록당 1024개의 쓰레드로 구성을 할 경우 SM당 2개의 블록을 구성을 할 수 있고 SP 낭비를 최소화 할수 있어 효율이 좋다. 표 3에 쓰레드의 개수에 따른 생성 시간의 평균을 나타내었다. 메모리 접근 밴드 폭은 96.48 GB/s이고 쓰레드를 1024개로 하였을 경우 5,046 GFlops의 부동 소수점 연산 능력을 가진다. 광원과 LUT는 상수메모리를 사용하기 때문에 실제 CGMA의 비는 모든 커널이 종료될 때 까지 누적된 홀로그램의 세기를 저장하기위한 두번의 메모리 접근이 있다. 따라서 1K의 유효 광원을 연산 할 때 1javascript:;0:1의 CGMA가 가능하다.
[표 3.] 블록당 쓰레드 개수에 따른 평균 연산 시간
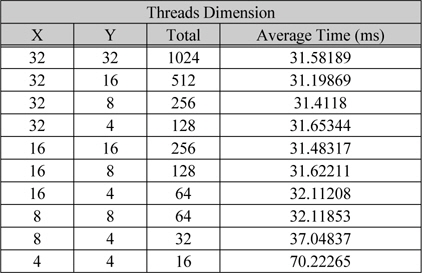
블록당 쓰레드 개수에 따른 평균 연산 시간
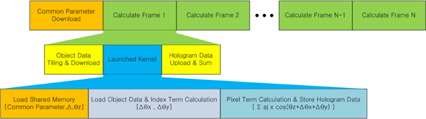
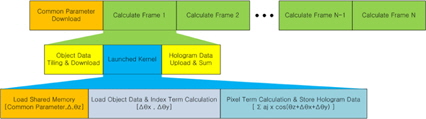
GPU 특성과 입력 포인트 클라우드를 고려하여 GPU연산 방법에 대한 가이드라인을 제시한다. 먼저 가동할 수 있는 GPU의 특성을 파악하고, 최적의 블록과 쓰레드 할당 방법을 얻는다. 또한 적절한 입력 광원의 타일링 방법을 실험적으로 찾는다. 이때 가장 중요한 것은 GPU를 활성화시키고 동작시키는 전체적인 작업 순서를 결정하는 것이다. 그림 7에 제안하는 GPU 운용 방식에 대한 동작 순서를 나타냈다.
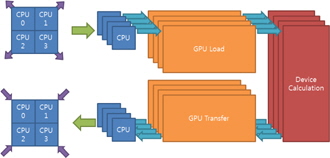
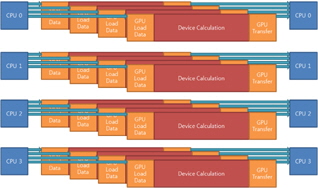
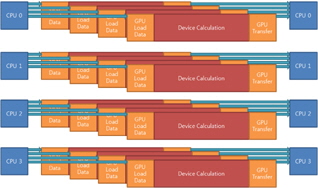
입력 광원에 따른 하나의 쓰레드에서 다중 GPU로 연산할 때 효율적인 연산을 위한 가이드라인을 제시하여 시스템의 구성 성분에 따른 최적화된 병렬화 성능을 도출해야 한다. 알고리즘의 병렬화는 현재 시스템이 어떻게 구성되어 있는지에 따라 많이 좌우되기 때문에 어떤 정답이 하나만 존재하는 것이 아니고 시스템 환경과 입력 데이터의 조건에 따른 환경변수에 맞추어 병렬 컴퓨팅의 성능을 결정한다. 그림 8에는 한양대[13]에서 수행된 GPU 병렬화 방식을 나타냈고, 그림 9에서는 광운대[14]에서 사용된 병렬화 방식을 나타냈다. 이 두 가지 방식은 어 병렬화된 알고리즘의 동작과 다양한 데이터 대역폭에 따라서 성능이 변할 수 있다. CPU와 GPU 사이에 큰 데이터 대역폭이 요구된다면 그림 8의 방법이 적당하다. 그렇지 않다면 불필요한 CPU 쓰레드의 점유로 인해서 CPU를 필요로 하는 동작의 성능을 저하시켜 전체 성능이 낮아진다. GPU는 단독으로 모든 동작을 감당할 수 없고 CPU의 도움을 필요로 할 뿐만 아니라 GPU에 의한 병렬 동작 이외에 CPU를 이용한 다른 동작들이 동시에 수행되고 있기 때문이다. CPU와 GPU 사이의 데이터 전송시간이 GPU에 의한 병렬화 동작 시간에 비해서 작다면 많은 CPU 쓰레드를 데이터를 전송하는데 사용할 필요가 없다.
CGH를 이용하여 컬러 홀로그램을 생성한다면 식 (2)는 R, G, 및 B 성분에 대해서 세 번 수행해야 한다. R, G, 및 B 성분을 위한 홀로그램은 각각 다른 파장의 광원을 사용하기 때문에 동일한 연산으로 수행될 수 없다. 식 (2)에서 λ에 다른 값이 사용되어
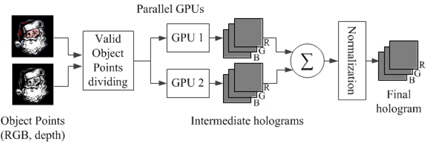
식 (2)의 CGH는 속도를 위하여 2개의 GPU를 이용하여 구현하였다[1. 깊이와 RGB로 구성된 광원 정보 중에서 유효한 광원만 2개의 GPU에 나누어 입력한다. 입력된 광원을 이용하여 각 GPU는 중간 홀로그램을 연산한다. 그 결과는 CPU에서 합쳐진 후에 정규화 과정을 거쳐서 최종적인 홀로그램으로 생성된다. 다중 GPU를 이용하여 병렬적으로 CGH를 수행하는 과정을 그림 11에 나타냈다.
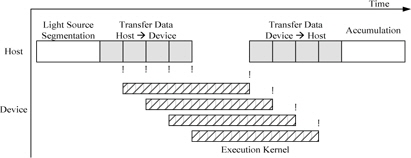
구현한 GPU 병렬 동작은 CUDA API내의 비동기 동작 함수를 통하여 호스트에서 GPU내의 메모리로 전송하는 동작을 제외한 GPU 커널을 독립적으로 연산이 가능하도록 구현하였다.
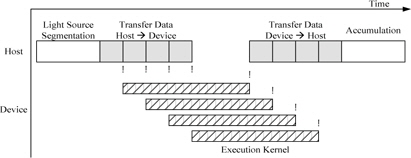
그림 12에는 호스트 프로그램과 GPU 커널간의 스케쥴링을 나타내었다. 호스트에서 유효한 광원의 데이터를 GPU의 개수만큼 나누어서 GPU의 메모리로 각각 전송한 뒤 이벤트를 발생시킨다. 각 GPU에서는 호스트에서 이벤트를 확인하여 커널을 수행하고 커널이 모두 끝나면 호스트로의 이벤트를 발생 시킨다. 호스트에서는 각 GPU로부터 이벤트를 확인하여 데이터를 호스트의 메모리로 홀로그램 결과를 로드 시킨다. 모든 GPU로부터 데이터를 로드 시킨 뒤 결과를 누적하여 홀로그램을 생성한다. 그림 12의 "!"는 이벤트 발생을 나타낸다.
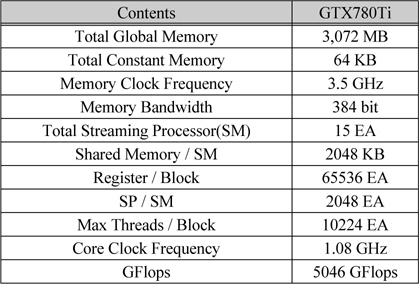
구현한 고속 홀로그램 생성 프로그램은 nVidia사의 CUDA를 이용하여 프로그램 하였고 사용된 GPGPU는 GTX 780Ti 4 대를 이용하여 실험 하였다. GTX 780Ti의 특성은 표 4에 나타냈다. 총 DRAM(전역 메모리)의 크기는 3,072MB이고 상수 메모리는 64KB, 블록당 공유 메모리는 48KB이고 SM당 65,536개의 32비트의 레지스터를 사용할 수 있다. 또한 블록당 최대 쓰레드의 크기는 1,024개이고 SM당 사용할 수 있는 최대 쓰레드 (SM당 SP의 개수)는 2,048개이고 총 SM의 개수는 15개로 이루어져 있고 코어는 1.08GHz로 동작 한다. 또한 DRAM은 3.5GHz의 속도로 동작하고 384bit로 데이터를 주고받는다. 이러한 GPU를 이용하여 CGH를 생성하는데 약 10K의 입체 정보를 이용하여 1,024×1,024의 컬러 홀로그램을 약 106ms에 생성하였다.
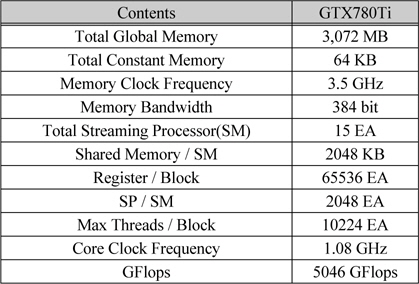
nVidia GTX780Ti의 특성
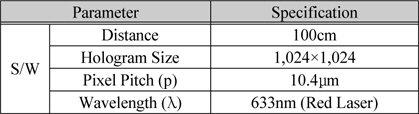
보정 및 중간 시점 생성의 단계에서 사용되는 알고리즘은 C/C++ 및 OpenCV로 구현하였고, CGH와 S/W방식의 복원은 CUDA 언어로 구현하였다. 이러한 S/W엔진들을 라이브러리화한 후에 LabView에서 함수로 이식하여 통합하였다. 홀로그램 영상을 복원하기 위해서는 광학장치를 이용하였고, 또한 테스트를 위해서 S/W 방식으로 복원하였다. 이를 위해 표 5와 같은 파라미터들을 이용하여 실험하였다.
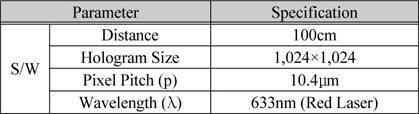
실험을 위한 파라미터
S/W적인 복원 방법은 홀로그램을 2차원 영상으로 취급하여 확인하고 화질을 테스트하기 위한 것이다. 2차원으로 복원하는 것이라 특정 거리에서만 복원이 되기 때문에 이 경우는 복원될 거리를 지정해준 다음, 그 거리의 평면에 맺히는 2차원 영상을 복원하게 된다. 이를 위해 식 (4)에 정의된 Fresnel 변환을 이용하였다.
여기서
본 논문에서는 GPU의 자원할당에 따른 GPU의 동작에 대하여 소개하고 홀로그램 생성을 위한 최적화 기법에 대하여 가이드라인을 제시하였다. GPU의 커널이 실행 될 때 필요한 레지스터 및 실행 쓰레드 및 블록의 개수에 따른 GPU의 동작을 소개하고 최적화된 자원 할당 방법 대하여 제안하고 또한 고속의 홀로그램 생성을 위한 타일링 기법과 사용하는 메모리 및 데이터 포맷에 대하여 최적화 하는 방법에 대하여 제안하였다. 실험을 통하여 구동 GPU의 특성을 파악하여 최대 쓰레드를 개수를 결정 하고 상수 메모리를 사용하여 CGMA의 비를 높이고 타일링을 통하여 최적의 GPU 동작 점을 확인하였다. 본 논문에서 제시하는 가이드라인을 통하여 구동 GPU의 타겟에 따른 홀로그램 생성의 최적화 할 수 있다.