The approach of Topic Modeling (“TM”) has been applied in various domains, such as tech forecasting, text mining, and informetrics (Griffiths & Steyvers, 2004; Kang et al., 2013; Lu & Zhai, 2008; Park & Song, 2013; Song et al., 2013; Tang et al., 2012; Titov & Mc-Donald, 2008; Yu, 2013). The foundation and applicability of TM can be described as being fundamental and concrete due to the fact that is based on the Probability Model, which is linked to the Language Model. Development of an advanced method, at the same time, has been an ongoing process in order to enhance the performance of TM and various tools, and its applications have been developed and distributed.
The approach to interpreting the result of TM, however, has been recognized as an area needing growth in resolving the difficulty in characterizing and interpreting topics. Evidential cases of this difficulty have been found in some studies and these studies demonstrate additional efforts, such as inserting topics or eliminating keywords, to reduce the difficulty of interpretation (Hall et al., 2008; Talley et al., 2011). For example, non-informative keywords were eliminated and more informative phrases were added for easier interpretation after executing LDA-based TM analysis on NIH-supported research output in the study of Hall et al. (2008). Similar to the study of Hall et al. (2008), some number of topics were inserted additionally after finding 36 valid topics by applying TM in the research of Talley et al. (2012).
One of the possible reasons for this difficulty could be the de-contextualization of the relation among the top-k keyword in a topic when the output of TM is provided. The most common way of providing the output of TM is a list of top-k keywords of each topic (Chang et al., 2009). The sorted keywords in order of probability, however, would not be enough to deliver the character of a certain topic, which could be inferred from the overall combination of the loaded keywords in the topic (Chuang et al., 2012; Ramage et al., 2009b). And this implies that characterizing the latent topic could be needed in additional works for inferring meaningful contexts from the keyword list.
Another possible reason could be a multi-assigned keyword; that is, a keyword which is assigned to more than two topics at the same time with high probability. This means that the multi-assigned keywords are, probably, frequently occurring keywords in a certain dataset and this could make interpretation vague and lead to several similar names among the topics. Therefore, it could be hard to achieve the distinctiveness of interpretation.
Sophisticated methods of TM and visualization have been suggested to make interpretation easier (Chaney & Blei, 2012; Chuang et al., 2012). Labeled LDA (Ramage et al., 2009a) and Partially Labeled LDA (Ramage et al., 2011) were developed for enhancing the performance of TM. Several visualization approach and network analysis methods including citation linking have been also applied for the better performance of TM (Mei et al., 2008; Nallapati et al., 2008).
Along with the previous research, this study, therefore, aims to explore an approach to enhance the ease of interpretation by combining social network analysis with topic modeling. In order to contextualize the keywords in a topic and to reduce the number of multi-assigned keywords, co-word analysis, and the concept of a “synchronization network” is applied in refining the result of TM without distracting the topical cohesion in a topic.
Synchronization in a complex network is defined as phase transition when the entire network of nodes begins to emit and receive a signal at the same frequency, and this phenomenon has been detected and researched in various domains (Arenas et al. 2008; Kuramoto & Nishikawa , 1987; Niebur et al., 1991; Pikovsky et al., 2001; Strogatz, 2000; Strogatz, 2001; Strogatz, 2003; Strogatz & Mirollo, 1988). Synchronization can be understood as a dynamic of networks focusing on the change of the property of a node affected by the property of the group of its connected nodes. Various applications of synchronization, such as analysis of genetic networks, systemic analysis on neuronal networks, data mining, opinion dynamics, neuroscience, or social sciences have been developed (Blasius et al. 1999; Buchanan, 2007; Elowitz & Leibler, 2000; Garcia-Ojalvo et al., 2004; Pluchino et al., 2005).
Applications of synchronization in data mining have been proposed for data clustering. The assumption for applying synchronization on data mining is that the dynamics of the data system could be categorized into clusters by detecting synchronization, and most of the previous research focused on dynamic modeling for the detection. Based on statistical methods of data mining, therefore, synchronization has been used in sophisticating the data mining techniques and exploiting the applicability of synchronization in data mining (Jalili, 2013; Jha & Yadava, 2012; Miyano & Tsutsui, 2007a; Miyano & Tsutsui, 2007b; Miyano & Tsutsui, 2008a; Miyano & Tsutsui, 2008b; Miyano & Tsutsui, 2009; Miyano & Tsutsui, 2013;Tilles et al., 2013; Wan et al., 2010).
Along with the previous studies, the application of synchronization in text mining was explored in this study by applying the concept in deliberating the result of topic modeling. There are operational definitions for the application. It is assumed that a multi-assigned keyword can be re-assigned to a certain topic by synchronizing the topic of the keyword with those of its co-occurring keywords. In this study, therefore, “keywords in co-word network” is matched to “the nodes” in the synchronization network and “re-assignment of one topic to a multi-assigned keyword” is matched for “phase transition.” The “entire network” is defined operationally as an ego-centric network of a certain multi-assigned keyword and its connected keywords that were used for determining the topic for the ego.
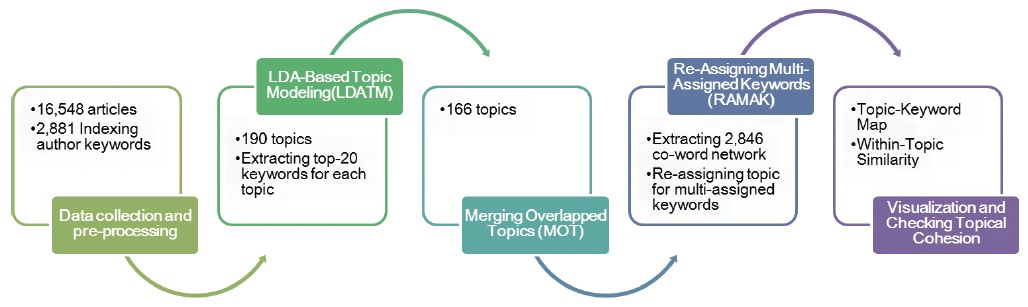
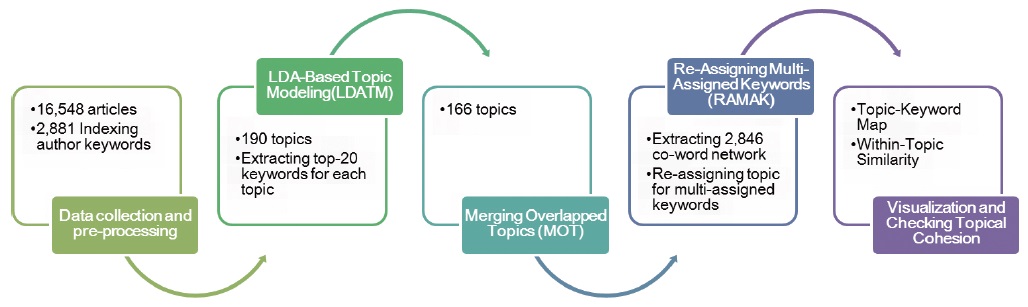
This study suggested the combined approach of text mining and network analysis. The research design of this study is shown in figure 1. The perplexity from the natural language processing domain was considered in the first step, and topical similarity from text mining was applied in LDA (Latent Dirichlet Allocation, Blei et al., 2003)-based Topic Modeling (“LDATM”) and Merging Overlapped Topics (“MOT”) steps. The concept of synchronization networks and ego-centric networks from complex networks was applied in the Re-Assigning Multi-Assigned Keyword (“RAMAK”) step.
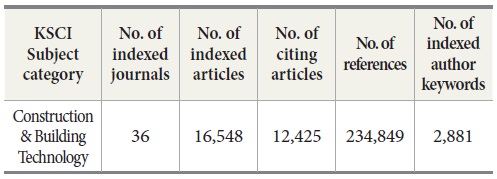
In the subject of Construction & Building Technology, 16,584 bibliographic records of KSCI-indexed articles1 were collected and pre-processed for topic modeling and co-word analysis. The indexed keywords for the analysis were from an English authors’ keyword field, and 2,881 keywords were used in the modeling.
LDATM was performed after 10 times of pre-testing for finding the optimal number of topics, and the top 20 keywords for each topic were selected. After modeling, all pairs of topics with similarity values of 1 by comparing all the probability of the loaded keywords were merged as one topic. The multi-assigned keywords were also identified after merging topics.
For the re-assigning process (RAMAK), a co-word network of 2,486 top 20 keywords was extracted by calculating cosine similarity between keywords from a document-keyword matrix. The Ego-centric network of each multi-assigned keyword was extracted and re-assigned a topic on the ego that was determined by finding the most frequently occurring topic number from its nearest neighbor keywords, with the cosine similarity of their connections in mind.
The details of each process are as follows in 2.2, 2.3, 2.4 and 2.5.
2.2. Data Collection and Pre-Processing
To begin, 16,548 KSCI-indexed articles in the domain of construction and building technology were collected for the analysis. The data fields for articles collected were: publication year, DOI, ISSN, journal name, citation counts, title, author name, affiliation, author keywords, and abstracts. All the text fields, such as title, author keywords, or abstracts were written both in English and Korean. For this study, author keywords were indexed and all syntactic stopwords were eliminated. The total number of indexed terms from author keyword fields is 2,881 as shown in Table 1.

Data Collection
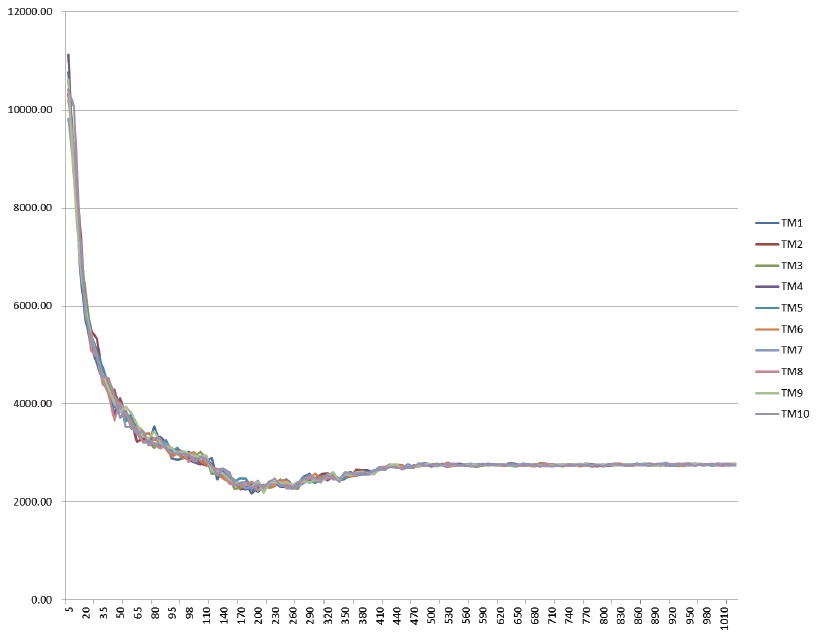
In order to set the number of topics, a perplexity score was calculated with 1,030 times of LDA-Based Topic Modeling. Perplexity score in a corpus means the predictability of a topic model and it is a widely-used metric in topic model evaluation (Asuncion et al., 2009).
Perplexity score is a parameter of how well a probability model predicts a test set (sample) in information theory and measurement of evaluating Language Modelin natural language processing. A lower value means a surer model (Brown et al., 1992).
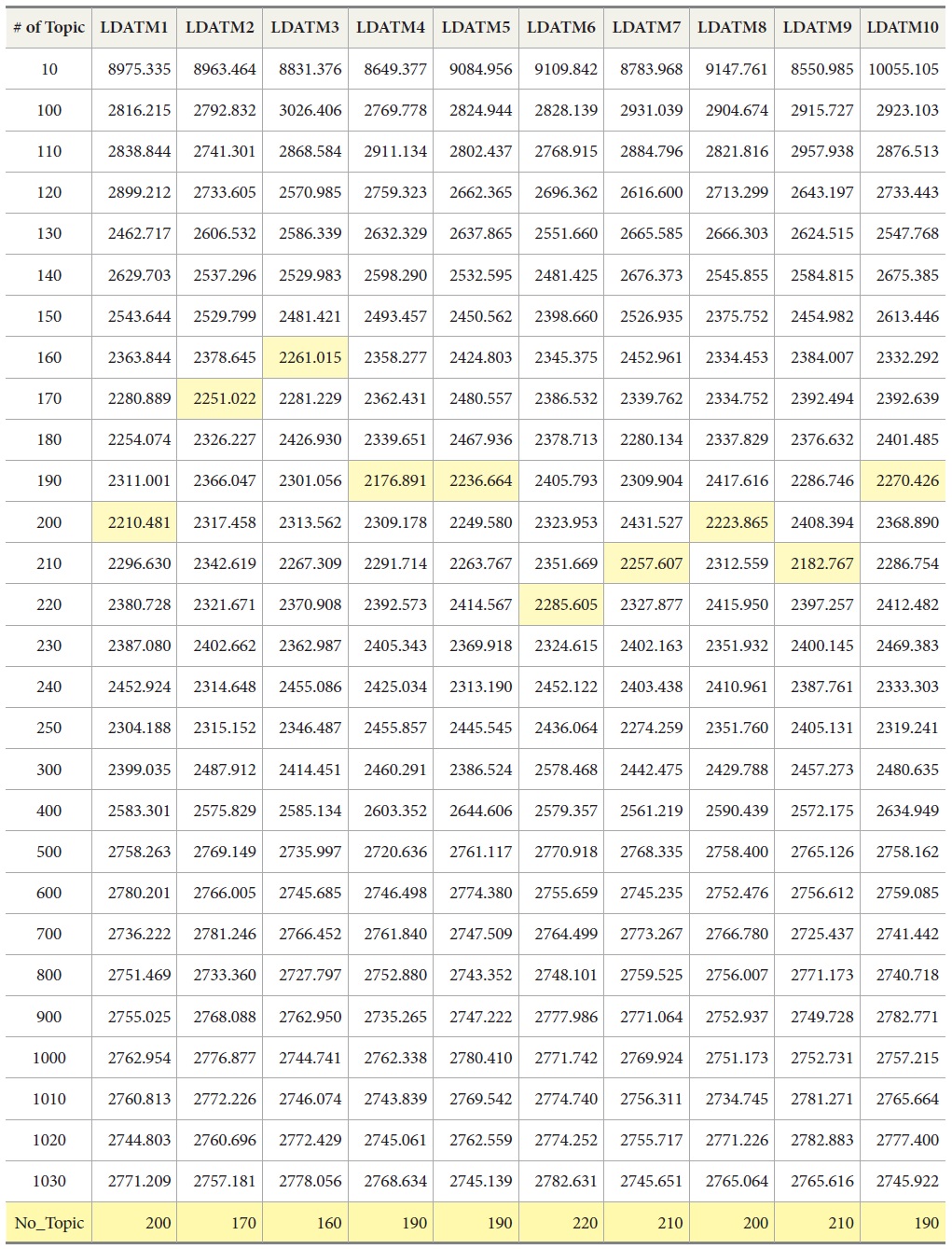
The modelings were executed with different numbers of topics and 1,000 iterations, and the number of topics in a model has been changed in the range from 10 to 1030 by increasing 10 for each modeling. The number of topics with the lowest perplexity score was estimated as 190.
Stanford Topic Modeling Toolbox 0.4.0 (“TMT,” Ramage et al., 2009a) was used in pre-testing. TMT, which has been developed by Stanford National Language Lab, was aimed to support research in social sciences and related fields by applying topic modeling on textual data. It is based on Java and supports LDA, Labeled LDA, and Partially Labeled LDA (Blei et al., 2003; Blei et al., 2006; Ramage et al., 2011).
As a result, the optimal number of topics was estimated as 190 by using perplexity value. The most frequently identified number of topics with a minimum value of perplexity was 190.
[Table 2.] Perplexity changes in pre-test
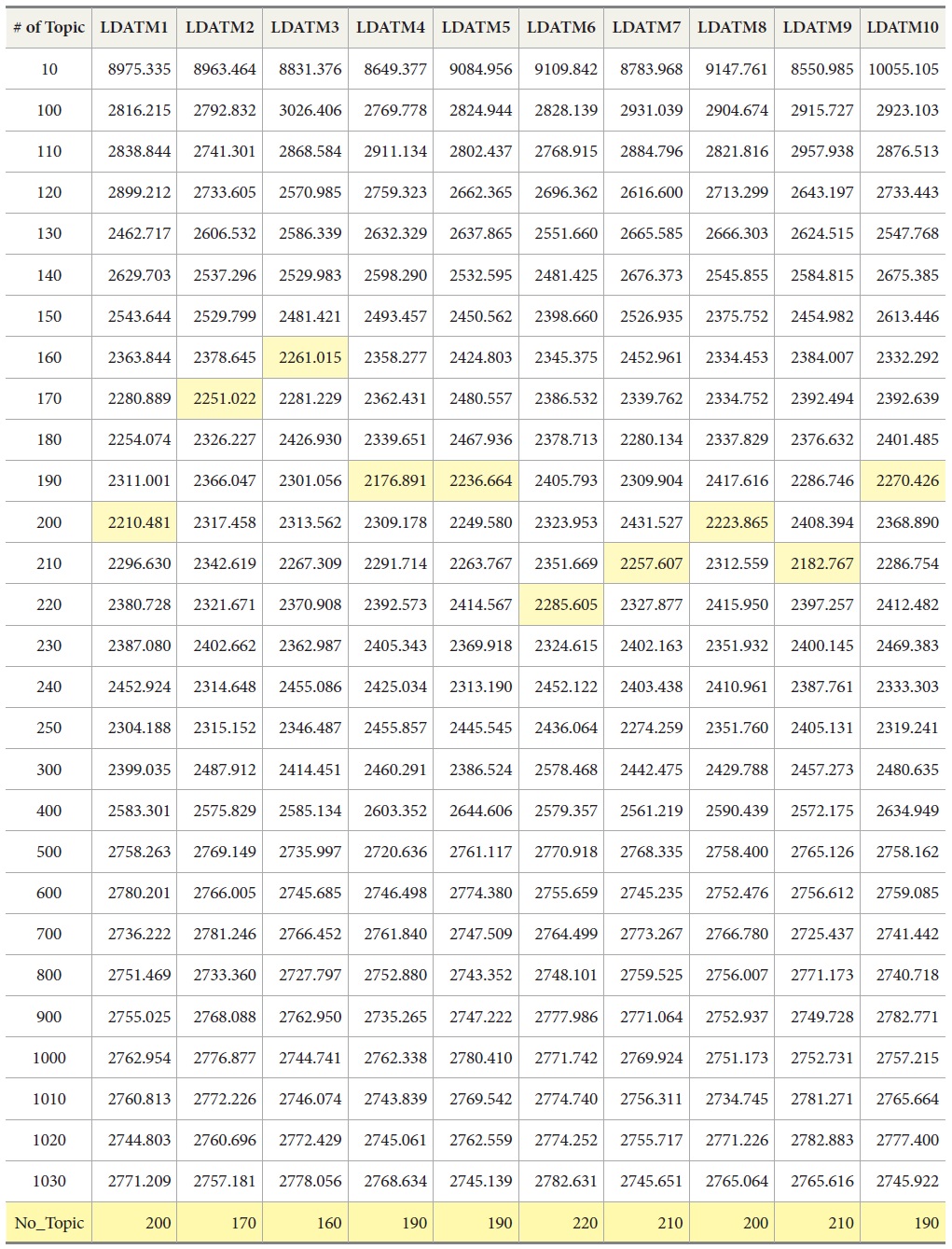
Perplexity changes in pre-test
2.3. Topic Detection and Merging Similar Topics
By setting the number of topics as 190, LDA-based Topic Modeling (LDATM) was performed with 1,000 repetitions. Topic Modeling Toolbox 0.4 was used for the modeling. Each topic was labeled with its topic number, such as ‘T1,’ and the most dominant topic had a smaller number in the label. The top 20 keywords of each topic were selected to describe the topic and the total number of unique top keywords was 2,846. Stanford TMT 0.4.0 was also used in topic detection.
Merging overlapped Topics (MOT) was executed by calculating similarity between two topics, and the topics are merged at a threshold of 1. The merged topic that 25 topics were merged into was labeled as “T4.”
2.4. Extracting Co-Word Network and Re-arranging Multi-Assigned Top-Keywords
The purpose of this step was to re-arrange a multi-assigned top-keyword in LDA-Based TM by assigning the keyword into one topic. There were 609 top-keywords which were assigned to more than two topics at the same time.
In this step, the concept of oscillator in synchronization networks was applied practically to determine and assign one topic to a multi-assigned keyword. In this study, the suggested application is more focused on the result of synchronization itself as a change of the property of a node evoked by its neighbor nodes, rather than modeling the dynamics of synchronization, in order to use the concept of synchronization to assign one topic to a multi-assigned keyword considering the topics which its nearest neighbors were assigned to. That is, the topic of the multi-assigned keyword is determined by the most frequently occurring topic from its nearest neighbors.
The process of applying synchronization is:
To extract an ego-centric network, co-occurrence networks among 2,846 top-keywords were extracted by using cosine similarity. For 609 multi-assigned keywords, 609 individual ego-centric networks were extracted. In each network of “EGO,” the ego node is a certain multi-assigned keyword. The network consists of the ego and its nearest neighbors, which are directly connected to the ego. The link weight is the cosine similarity between two nodes.
When each keyword is assigned to a certain topic as a result of LDATM and the links are calculated by using cosine similarity, the combination of those LDATM and co-occurrence similarities is used to determine the topic for the “EGO.”
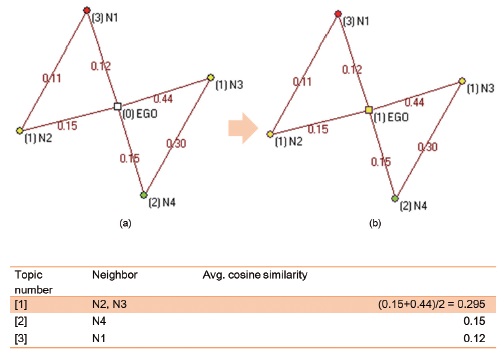
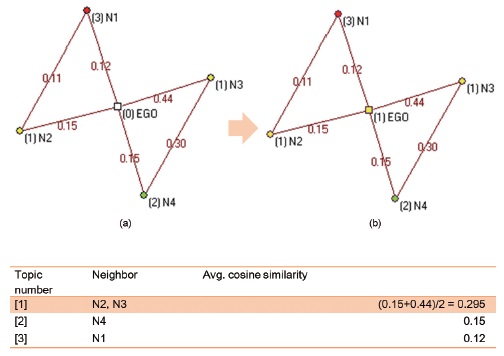
For example, assume that there is an ego-centric network for a multi-assigned keyword “EGO” with four nearest neighbor keywords, “N1,” “N2,” “N3,” and “N4.” This is a subset of the co-word network consisting of “EGO” and its nearest neighbors as node and links among them. The link weight between two nodes is the cosine similarity score of their co-occurrence in a document. To determine the topic category of the “EGO,” the weight score for a certain topic is averaged by using the cosine similarity between the “EGO” and its connected keywords that are assigned in the topic. For instance, N1 and N3 were assigned to Topic [1], while N4 for Topic [3], and N2 for Topic[2] were assigned, respectively, in figure 3. The topic for “EGO” was re-assigned as Topic[1] because the highest weight was from the combination of N2 and N3 with Topic[1], as shown in figure 3-(b).
2.5. Comparison of Maps and Topical Cohesion
To identify the effect of applying RAMAK, comparison of topic-keywords networks was conducted. The topic-keywords maps were made by using PAJEK 3.0 for visual comparison. For seeing a structural difference, the density and average degree of nodes were calculated and compared.
For comparing topical cohesion, “within-topic cosine similarity” was computed. The value of within-topic cosine similarity is an average cosine similarity of all occurring pairs of keywords in a specific topic. For a topic
Within-topic similarity
The differences in within topic similarity for all topics were statistically tested by conducting a paired-sample t-test and correlation analysis using SPSS21.
1KSCI (Korea Science Citation Index) is one of the national citation indices of the Republic of Korea and it provides bibliographic records of articles published in 661 national major journals of science and technology. See http://ksci.kisti.re.kr/main/about.ksci.
3.1. Changes in Major Topics and Related Keywords
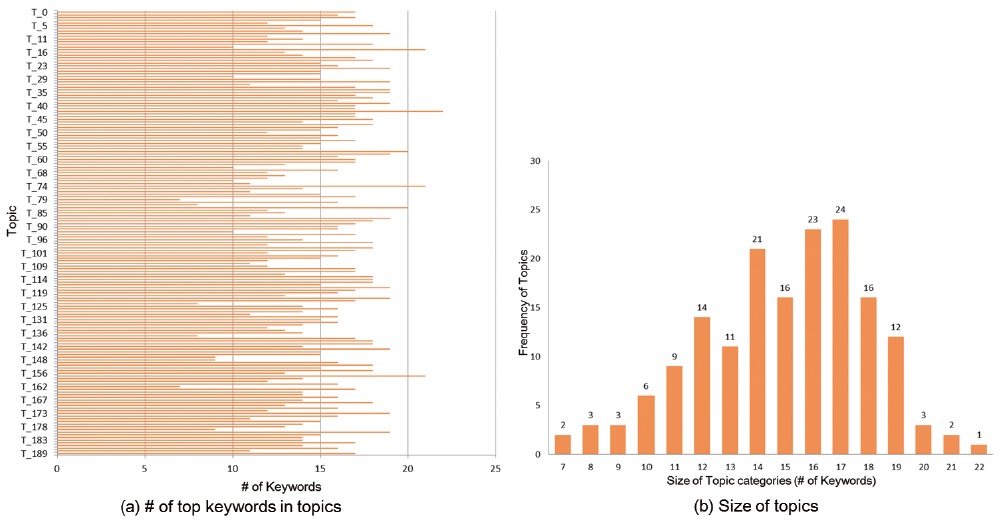
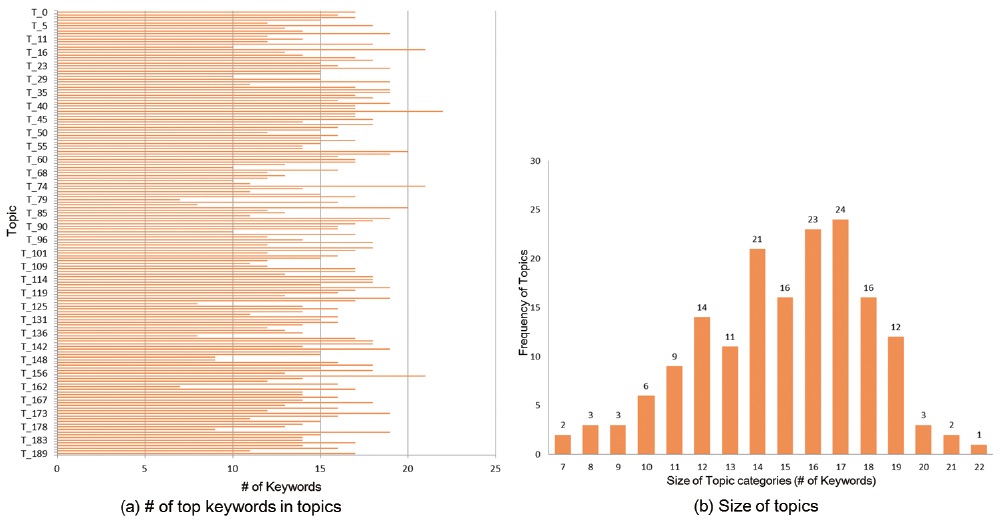
Each topic has top 20 keywords after applying LDATM and the number of the top keywords in several topic categories was changed by applying MOT and RAMAK. The number of 20 top keywords in only three topics (T157, T57, and T83) had been kept after reassigning the multi-assigned keywords, and the number of top-keywords in the other 163 topics had been changed. Only three topic categories (T15, T42, and T74) were expanded in terms of size, and another 160 topic categories resulted in fewer top-keywords. This doesn’t mean the decrease of the number of top-keywords but the decrease of the number of multi-assigned keywords.
figure 4 –(a) shows the number of changes in the number of top-keywords for each topic category and figure 4 –(b) shows the number of topic categories with the size of the topic. The sizes of topics mostly decreased, and only three topics were increased in size. The topics which resulted in less than 10 top keywords are T79 and T612, while the topics with more than 20 top keywords are T15, T42, and T74.
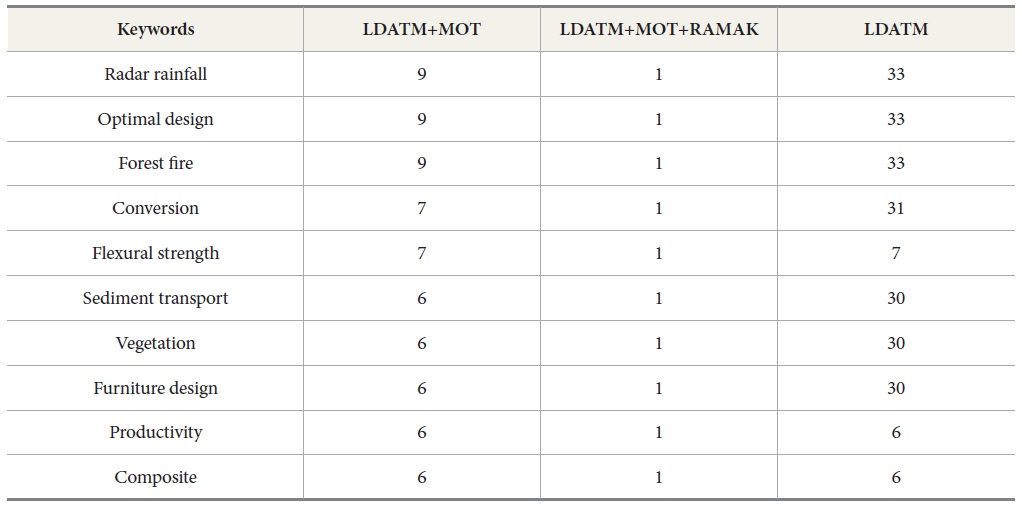
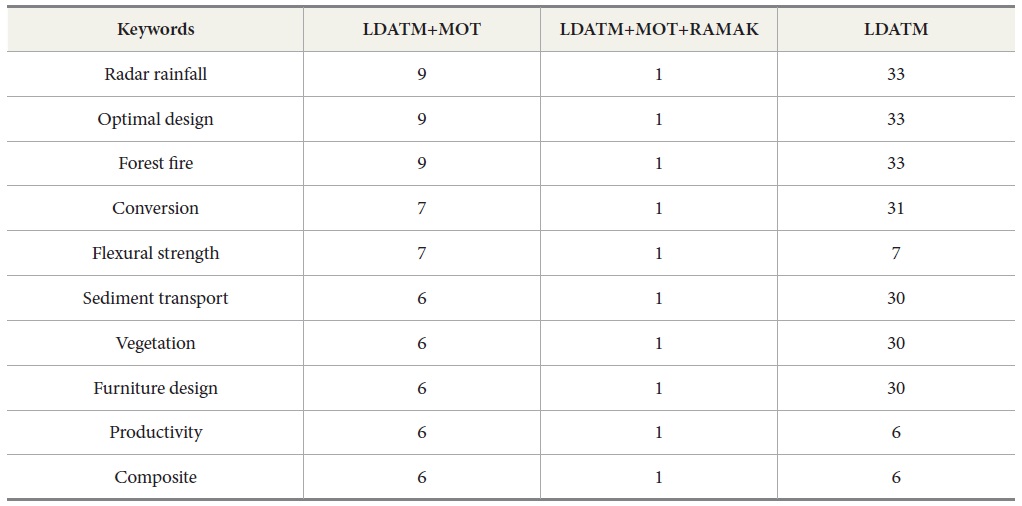
The number of keywords being assigned in more than two topics (“multi-assigned keyword”) was 609, which is 21.3% of the total number of unique top keywords (2,864). The number of multi-assigned top-keywords was also decreased to 7, and 602 out of 609 multi-assigned keyword were re-assigned to one topic category by applying RAMAK. The remains of multi-assigned keywords were “Shape memory alloy,” “Urban Residential Area,” “Design Value Engineering,” “Peter Zumthor,” “Brittle fracture,” “Fatigue crack,” and “Housing Satisfaction,” which cover several research topics of construction and building technology in general.
The top 10 topics with loaded top keywords were shown in Table 4. As shown in the table, multi-assigned keywords were re-assigned to non-top 10 topics and new top keywords from non-top 10 topics were added to any of the top 10 topics.
[Table 3.] Major Multi-Assigned Keywords
Major Multi-Assigned Keywords
[Table 4.] Comparison of Top 10 Topic Categories and Its Keywords

Comparison of Top 10 Topic Categories and Its Keywords
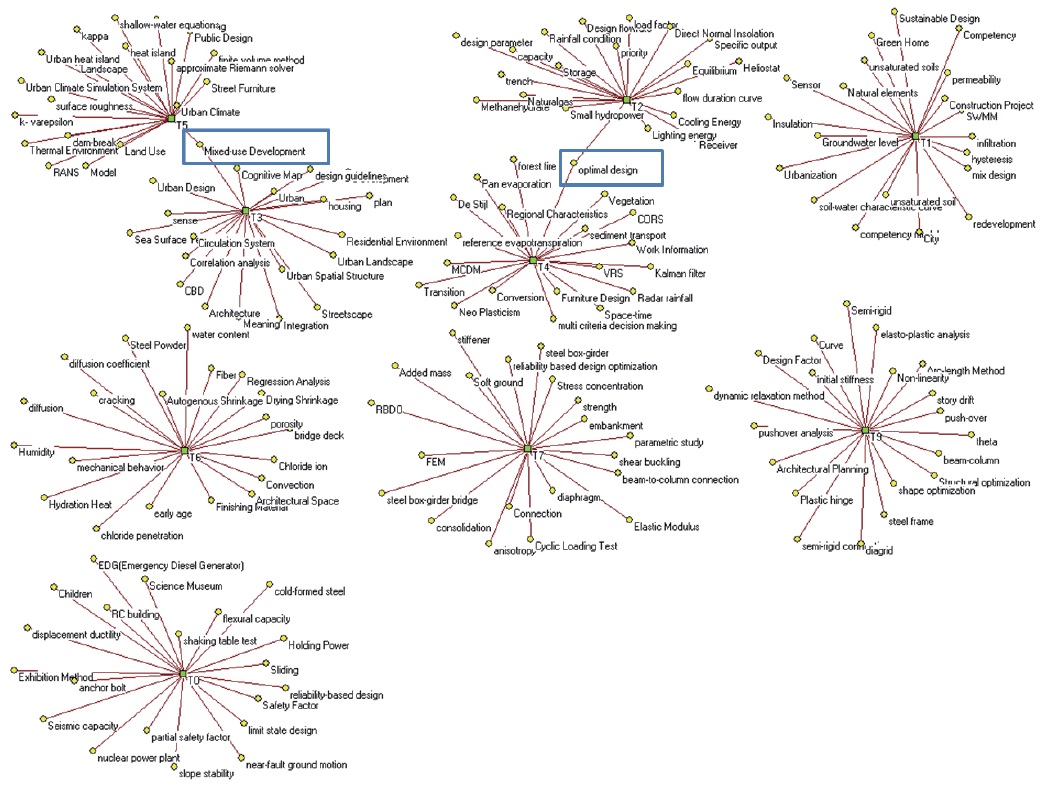
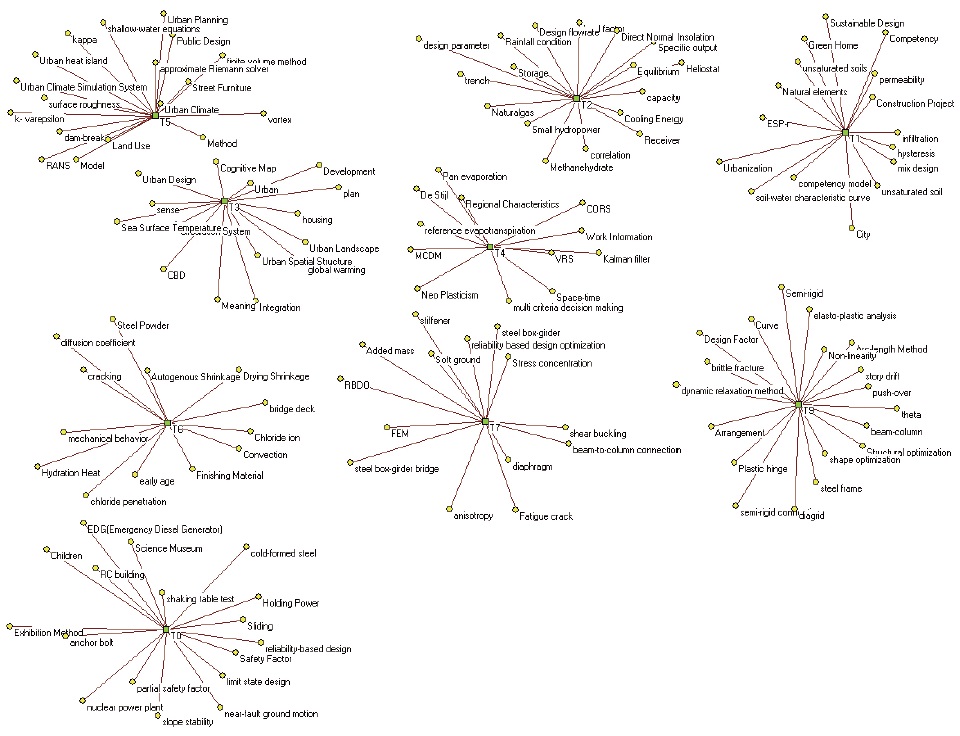
For example, the word term of “optimal design” in italics had been loaded to three topics among the top 10 topics; that is, T2, T4, and T8 in LDATM result, and it had been loaded to 33 different topics among the 190 topics. It was re-loaded to T100 after applying MOT and RAMAK. And the word term of “Mixed-Use Development” in T3 and T5 was re-located in T15 by applying MOT and RAMAK.
Adding new top keywords to the top 10 topic categories was made by the application. For example, “global warming” (underlined) in T3 was added to T3 by considering the most prominent topic number among its strongly connected co-words. All newly added top-keywords in the top 10 topics were underlined in Table 4.
3.2. Changes in Knowledge Structure
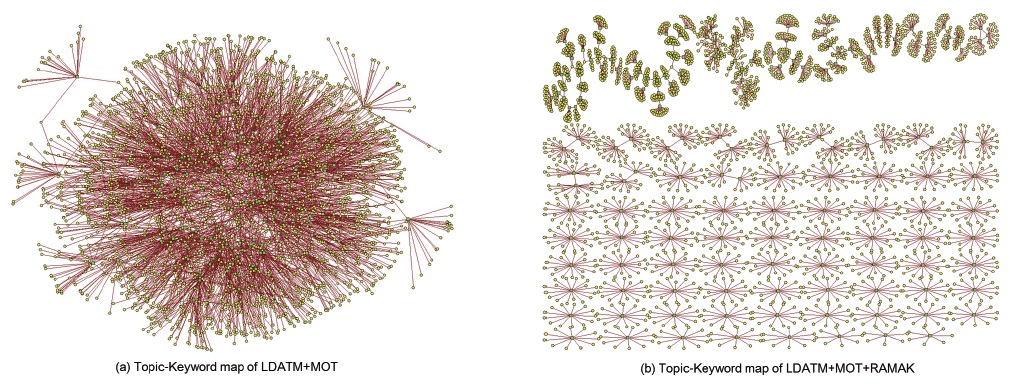
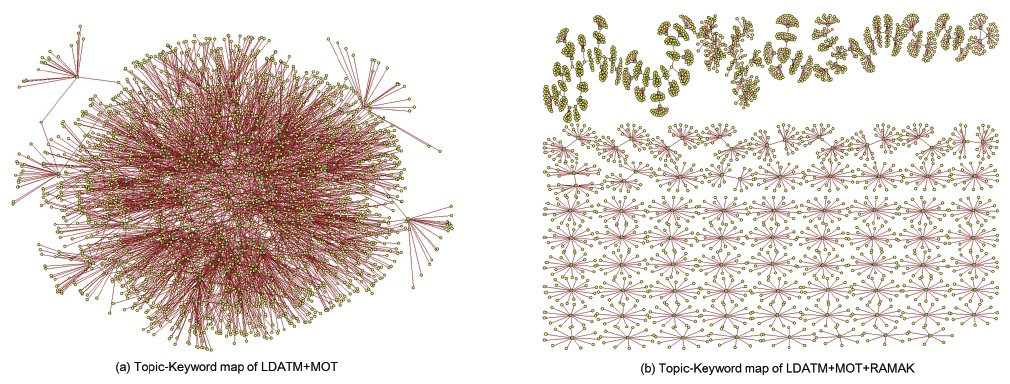
Both the density and average degree of the topic keyword network were decreased by applying MOT+RAMAK, due to the fact that the links between multiple topics and top keywords were eliminated. Therefore, the network of “LDATM+MOT+RAMAK” was identified as providing a clearer view visually.
The enhancement in visualization could be identified in network structure in terms of density and average degree. The density of the topic-keyword network of LDATM+MOT+RAMAK was decreased to 0.006 from 0.008, so that it could be expected to have less complex link structures. The average number of connected nodes for each node in the network (Avg. Degree) was also decreased to 1.88 from 2.84.
The improvement in visualization was also presented in comparing those maps visually. As shown in figure 5–(a) and figure 5 –(b), it can be visually identified that the “LDATM+MOT+RAMAK” network has a more refined and clearer structure between topics and their top keywords. The box indicates a topic category and the eclipse indicates a certain top keyword.
[Table 5.] Structure of Topic-Keyword Networks

Structure of Topic-Keyword Networks
There was only one component in figure 5-(a), in which all topics and keywords were connected by the multi-assigned keywords. It was obvious that all topics in the analyzed domain were related to each other, but interpretation was difficult because of the visual complexity. The map of figure 5-(b), which was the result of applying RAMAK, presented a relatively clearer and more easy-to-analyze situation. The number of connected topics and keywords was decreased and most of the topics were differentiated from each other visually.
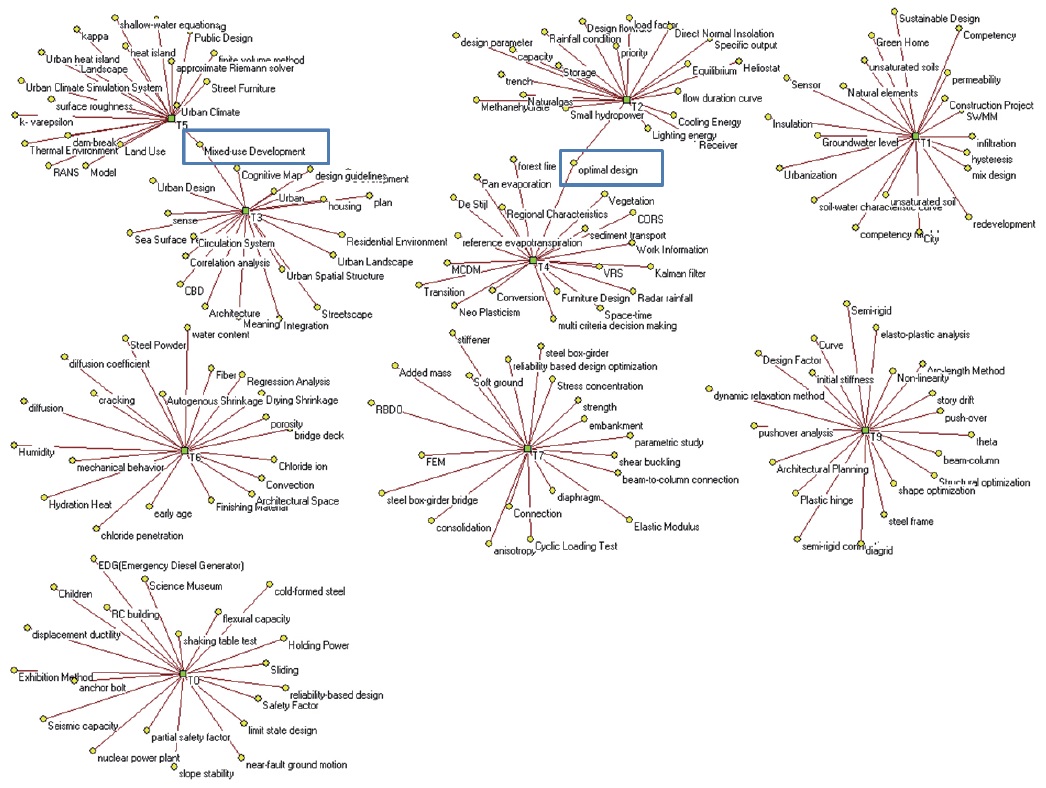
In addition to the change in overall topic-keywords network structure, a change in the 10 dominant topics and their pertinent keywords was also analyzed. The number of keywords in figure 6 was 178 and the number of keywords in figure 7 is 141, because of re-assigning the multi-assigned keywords. As was identified in Table 4, two multi-assigned keywords, that is, “optimal design” and “multi-use development” were re-located to other topic categories and links between T3 and T5 and between T2 and T4 were eliminated.
It was identified that the changes in dominant topics were not huge, relatively, when comparing the result to Figure 5. It could, therefore, imply that the process of re-assigning multi-assigned keywords could keep the major knowledge structure while refining the relatively peripheral topics.
3.3. Changes in Topical Cohesion
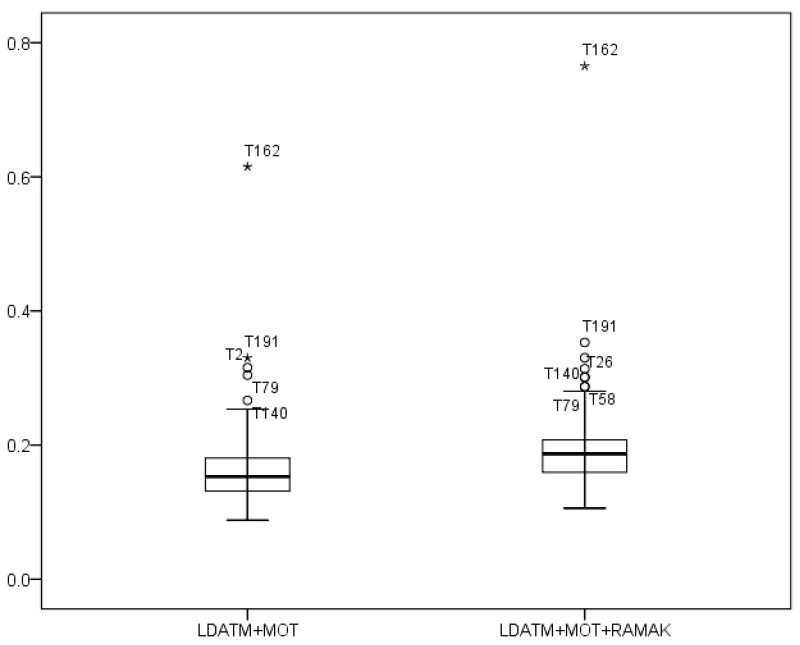
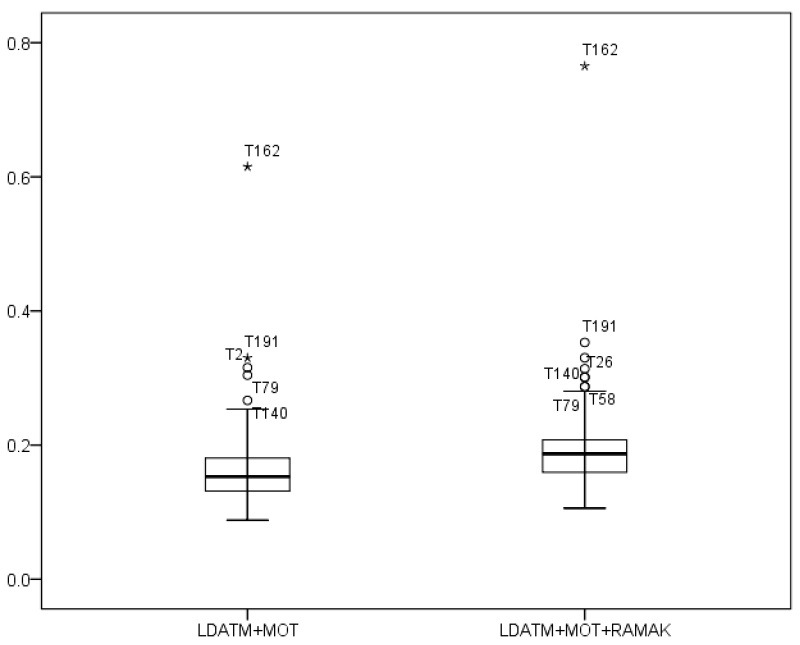
The average value of within-topic cosine similarity over 166 topic categories was increased by 0.029 after re-assigning the multi-assigned keywords, and the difference was statistically significant (
A paired-samples t-test, therefore, was conducted to evaluate whether the within-topic similarity of LDATM+MOT+RAMAK(B) is higher than that of LDATM+MOT(A). The results shows that the mean of (B) (
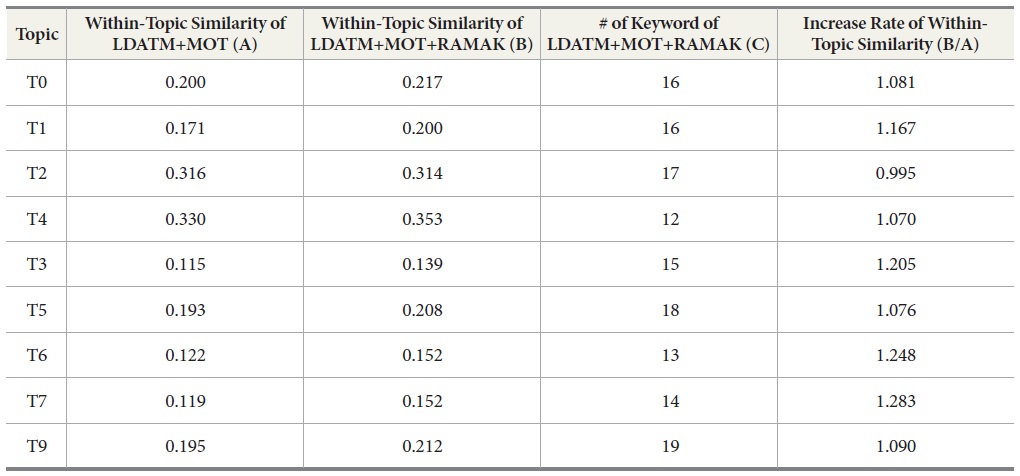
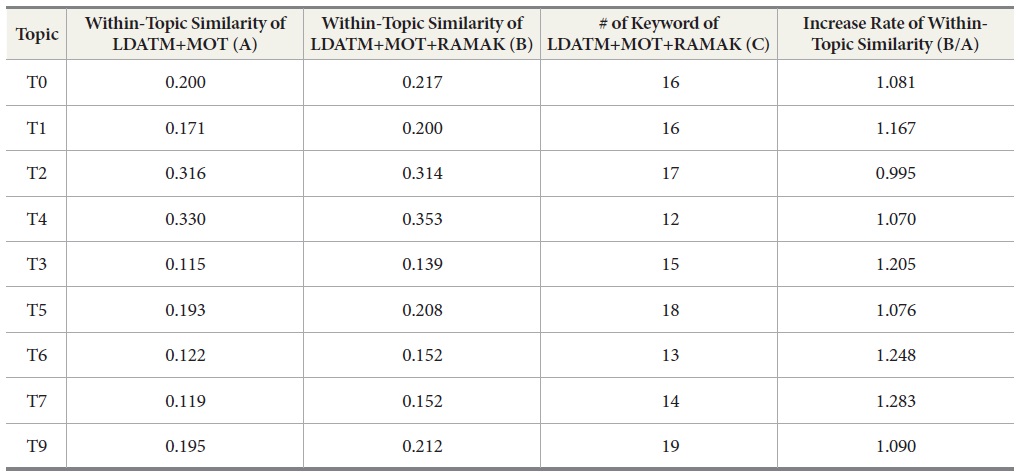
Table 6 shows the changes of topical cohesion in major topics, and all topics except T2 had an increase in topical cohesion among the keywords in the topic. The value of within-topic similarity of all topics except T2 increased after applying RAMAK.
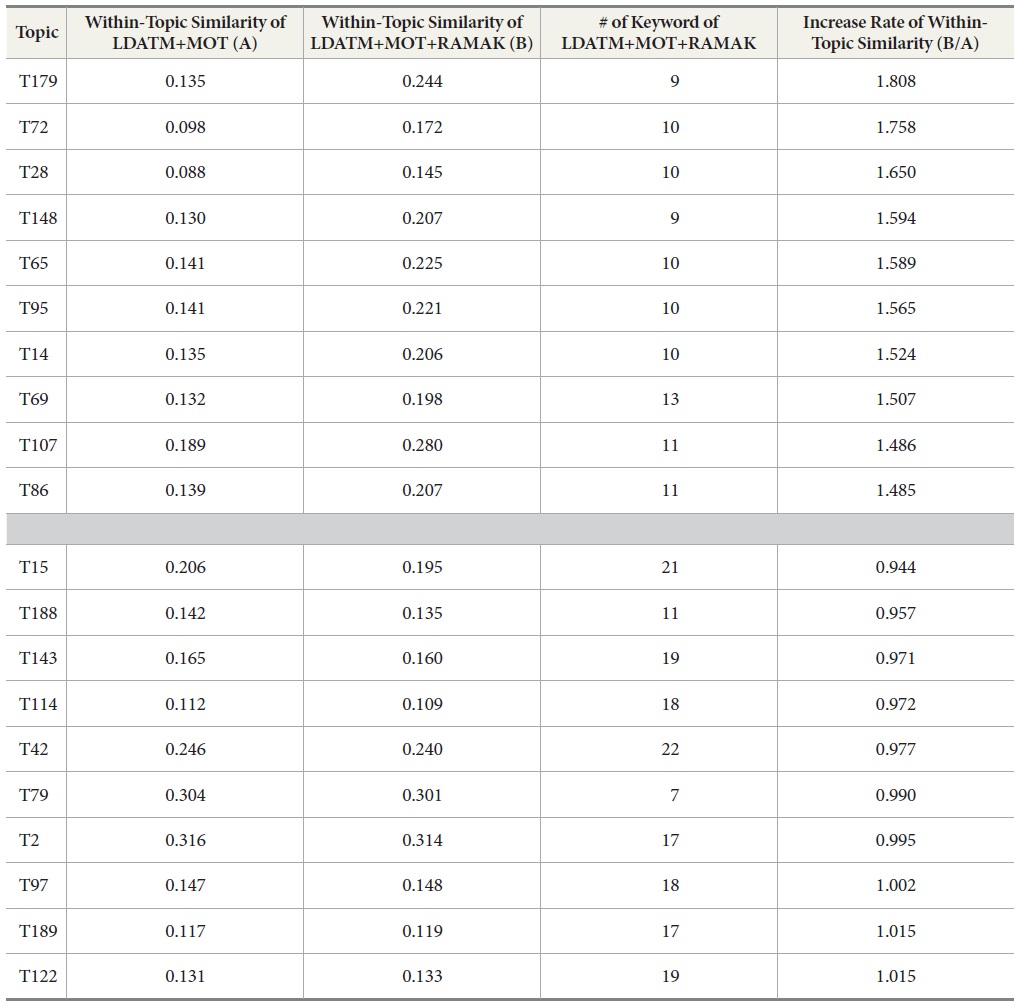
The 10 topic categories with the highest increase rate and the 10 topic categories with the lowest increase rate are shown in Table 7. The increase rate of within-topic similarity is a ratio of the within-topic similarity of LDATM+MOT+RAMAK based on the within-topic similarity of LDATM. As shown in Table 7, the increase rate below one is only seven topic categories and the values were close to one.
[Table 6.] Changes of Topical Cohesion in Major Topics
Changes of Topical Cohesion in Major Topics
[Table 7.] Top 10 Topics with the Major Changes in Within-Topic Similarity

Top 10 Topics with the Major Changes in Within-Topic Similarity
It also implies that a certain topic with fewer top-keywords has a more cohesive structure topically. Spearman’s rho was computed between the increase rate of within-topic similarity and the change in the number of keywords. The result of the correlation analysis was statistically significant (
This study combined the approaches of natural language processing, text mining, and network analysis to explore the applicability of the concept of synchronization in the result of topic modeling. As a result of applying the combined approach to the domain analysis of construction and building engineering, visibility not only in the relationships of topic-keyword but also in that of topic-topic was observed as being improved and topical cohesion in a topic was significantly increased overall.
The combined approach of this study could be regarded as being easy to apply with the best of knowledge on the phenomenon of synchronization in a complex network. The approach of re-assigning the multi-assigned keyword after merging similar topics on the result of LDA-based topic modeling is practical and step-wise. Also, the approach suggested in this study could provide more acceptable and interpretable evidence to researchers and experts in a specific domain in order to help them to detect and analyze the overview of the domain based on their knowledge of it, because the approach could reduce complex connections between multi-assigned keywords and topics.
Because the suggested approach of this study is exploratory, there should be more cases of applying the approach in various domains for generalization and advancement of the approach. More sophisticated evaluation, such as performing user evaluation or calculating a ratio of between-topic similarity and within-topic similarity, should also be investigated to develop the advanced methods of the suggested approach.