Recently, a huge number of documents have been produced and stored in digital archives [1]. Therefore, document classification plays a very important role in many information management and retrieval tasks. It refers to the task of classifying a document into a predefined category. Most digital documents are frequently updated, and writers disseminate information and present their ideas on various topics [2]. Unlike news articles written by well-educated journalists and standardized according to official style guides, most digital documents, such as weblogs and twitter tweets, tend to contain colloquial sentences and slang that misleads the classifier, because anybody can publish anything [3-6]. Considering this cumbersomeness of document classification, researchers have proposed the following approaches.
First, naive Bayes-based approaches have performed well from the perspectives of spam filtering and email categorization, and they require a small training corpus to estimate the parameters necessary for document classification [4]. However, the conditional independence assumption is violated by real-world data and does not consider the frequency of word occurrences [7]. Therefore, these approaches perform very poorly when features are highly correlated [8].
Second, the support vector machine (SVM)-based approaches have been recognized as some of the most effective document classification methods as compared to supervised machine learning algorithms. Nevertheless, these approaches have certain difficulties with respect to parameter tuning and kernel selection [7]. Further, the performance of SVM suitable for binary classification degrades rapidly, as the amount of training data decreases, resulting in a relatively poor performance on large-scale datasets with many labels [8].
Third, knowledge-based approaches have utilized knowledge, such as the meaning and relationships of the words, which can be obtained from an ontology, such as WordNet [8]. However, considering the restricted incompleteness of an ontology, the effect of word sense and relation disambiguation is quite limited [9,10].
Fourth, Web-based approaches have been used for mining desired information, such as popular opinions from Web documents obtained by traversing the Web in order to explore information that is related to a particular topic of interest. However, Web crawlers attempt to search the entire Web, which is impossible because of the size and the complexity of the World Wide Web [11].
In this paper, we propose a document classification model to solve the imbalance of the training corpus size per category by utilizing Web documents. The rest of this paper is organized as follows: Section II presents an overview of the proposed model consisting of a prediction phase to assign a category to a given document, and a learning step to balance the training corpus size by adding Web documents. Then, Section III presents some experimental results, and the characteristics of the proposed method are presented as the conclusion of this paper in Section IV.
II. WEB-BASED DOCUMENT CLASSIFICATION MODEL
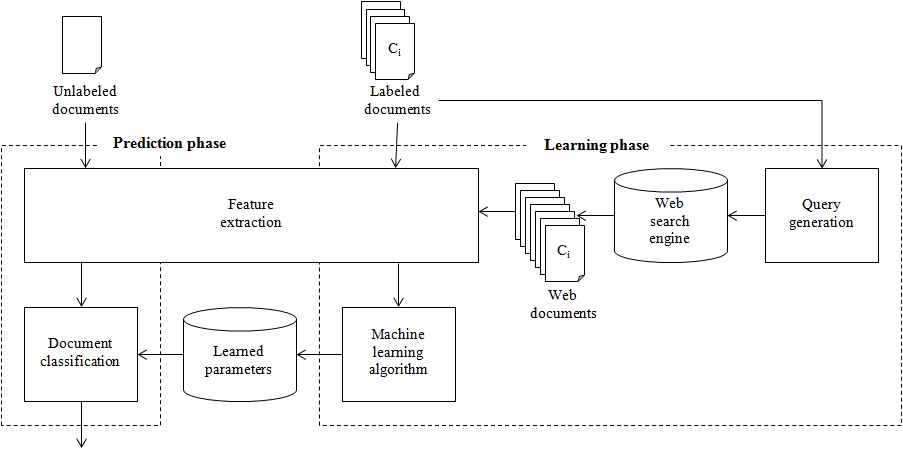
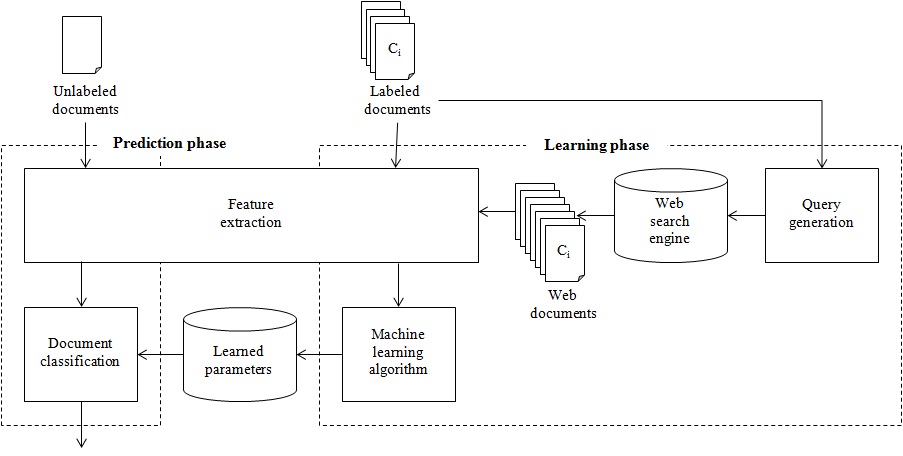
As shown in Fig. 1, the proposed Web-based document classification model is composed of a prediction phase and a learning phase. Given an unlabeled document in the prediction phase, the feature extraction step extracts some word features, such as unigrams and bigrams from the document. Then, the document classification step predicts the category of the document by utilizing the learned parameters. On the other hand, the learning phase obtains these learned parameters, such as word-frequency distribution from the category-labeled documents. Section II-A introduces the document classification method, and Section II-B describessed Web document acquisition method in detail.
>
A. Document Classification Method
The proposed document classification method selects the category
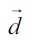
consisting of feature values extracted from the document by the feature extraction step. Each feature value indicates the number of times that each word feature, such as the bigram “arcade game” appears in the document [12]. Most elements of the document vector take a zero value.
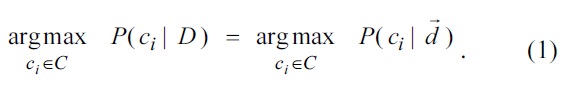
In the maximum entropy framework [12-15], the conditional probability of predicting an outcome
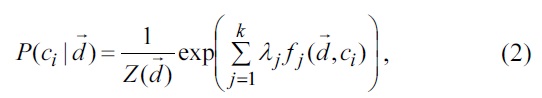
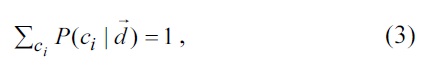
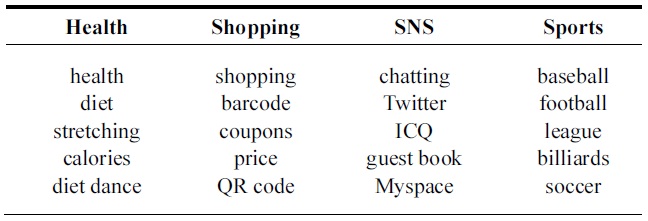
[Table 1.] Some word features selected on the basis of chi-square statistics
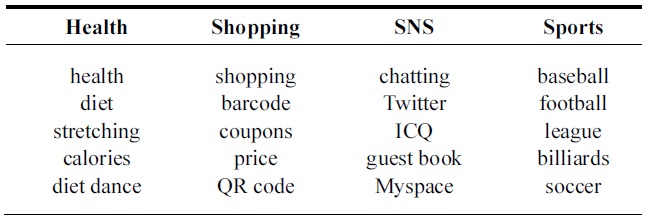
Some word features selected on the basis of chi-square statistics
where
>
B. Web Document Acquisition Method
In order to balance the training corpus size per category, the proposed Web-based document classification model increases the number of labeled documents by utilizing a Web search engine to retrieve the Web documents.
In the query generation step shown in Fig. 1, the proposed method first selects some useful word features per category on the basis of the chi-square statistics [16,17]. The chi-square statistics of word feature
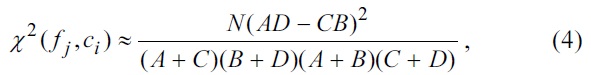
where
number of documents. Each word feature
Given the selected word features per category, the proposed Web document acquisition method generates a query for the Web search engine. Considering that the lower-ranked word features can be less related to the characteristics of the category, the proposed method combines two of the higher-ranked word features and the title of the category for the purpose of retrieving the Web documents closely related to the category. Therefore, the query consists of three word features: the category title, one of the top 5 ranked word features, and one of the top 200 ranked word features except the top 5 ranked word features. For each category, the proposed query generation step maximally yields 975 queries by multiplying the 5 higherranked word features with the 195 lower-ranked word features.
Finally, the proposed Web document acquisition method sends each combined query to the open application programming interface (API) of the Web search engine, and receives the snippet results retrieved from the Web search engine. The proposed Web document acquisition method assumes the snippet results of each query as one Web document.
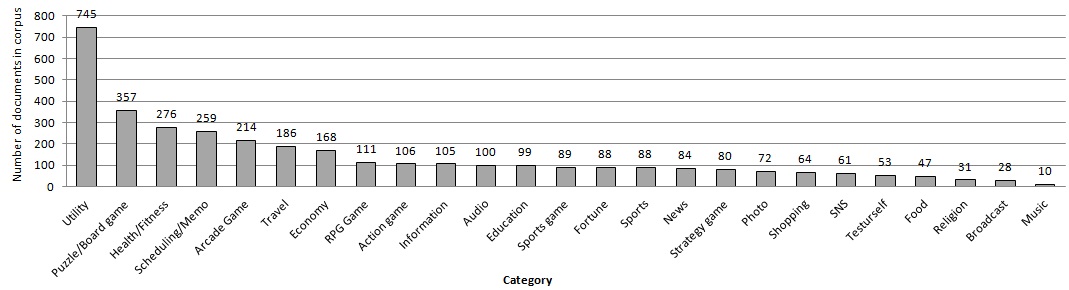
In order to prove the validity of utilizing the Web documents, we have tested the MALLET document classification package [12] with a mobile application description document corpus [18], which is divided into 90% for the training set and 10% for the test set. The document corpus consists of 3,521 documents and 302,772 words. Each
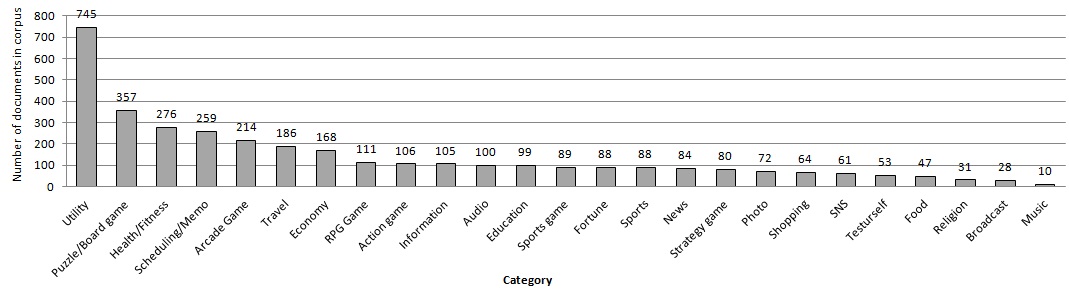
document has 3 to 515 words, and a document is composed of 85.99 words on average. As described in Fig. 2, the distribution of documents is not balanced among categories in the corpus. For instance, the documents corresponding to the
On the other hand, the proposed method is evaluated on the basis of the following evaluation criteria: precision, recall, and F-measure. Precision indicates the ratio of correct candidate categories to the candidate categories predicted by the proposed document classification model. Recall indicates the ratio of correct candidate categories to the total number of categories of the documents in the corpus. F-measure indicates the harmonic mean of the precision and the recall.
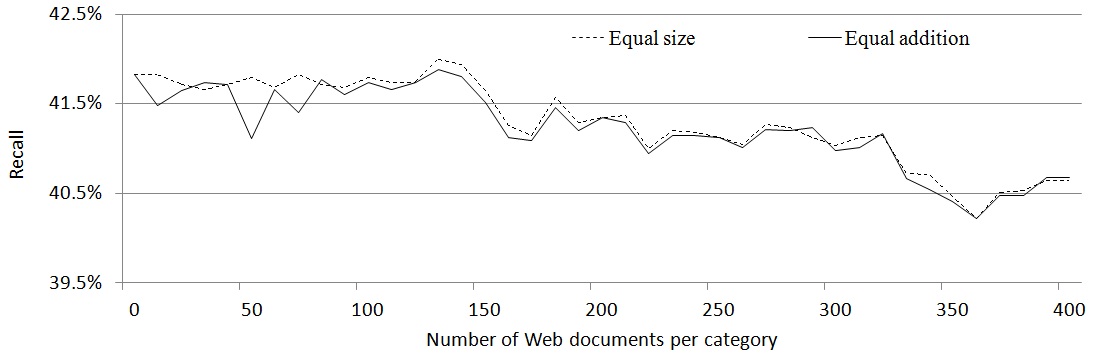
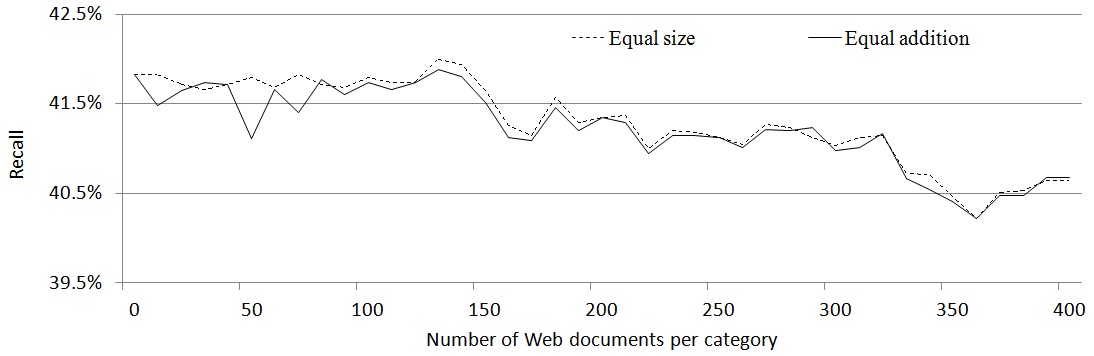
Fig. 3 shows that the performance is improved by adding Web documents; here, each performance value is an average of the 10-fold cross validation. In this figure, the y-axis indicates the recall value, and x-axis denotes the number of Web documents. Because the proposed document classification model predicts all categories of the given documents, the precision is the same as the recall. The baseline performance without any document classification model is
21% because the documents corresponding to the utility account for roughly 21% of the corpus.
Fig. 3 shows that the
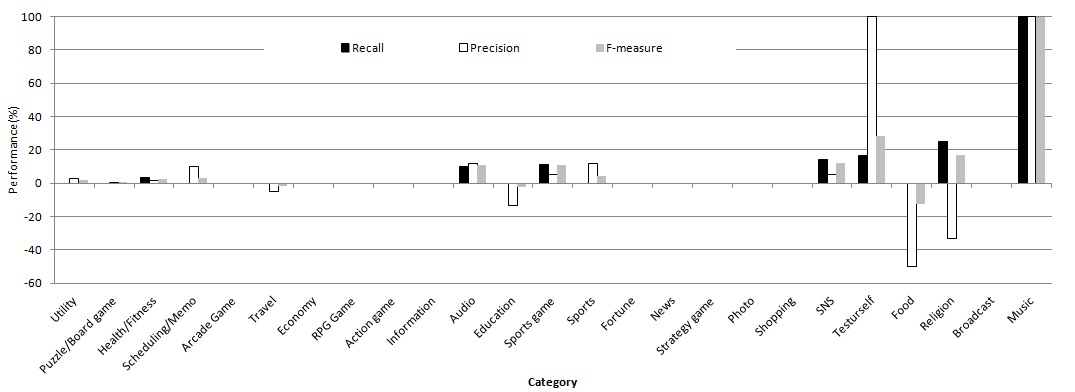
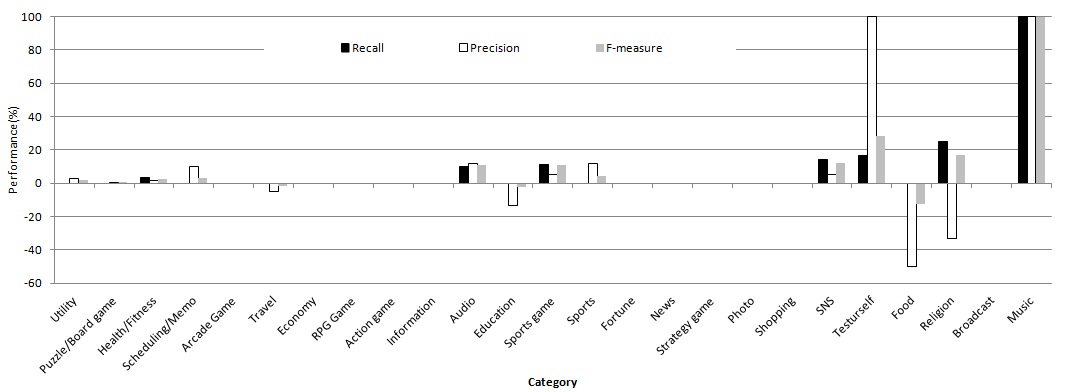
Fig. 4 shows the effects of Web documents according to categories at the peak performance by adding 150 Web documents per category. It indicates that the effects of Web documents can differ considerably from each other according to the category, although the general performance did not increase much upon the addition of Web documents. In particular, the recall and the precision of
In this paper, we propose a document classification model utilizing Web documents. The proposed model has the following characteristics: the proposed model can adjust the balance of the training corpus size per category by adding Web documents to the training corpus. Further, the proposed model can retrieve Web documents that are closely related to each category by combining two of the higher-ranked word features and the category title according to the matching score between the word features and the category. Experimental results show that the proposed model improves performance in some categories in the case of small training sets by balancing the number of documents per category. In the future, we intend to compare the effects of some feature selection methods, such as mutual information and information gain. Further, we plan to automatically generate word clusters and apply them to the proposed model.