Facial expressions are a fundamental element of our daily social interactions. Faces exhibit a rich set of details about someone’s mental status, intentions, concerns, reactions, and feelings [1]. Expressions and other facial gestures are an essential component of nonverbal communication. They are critical in emotional and social behavior analysis, humanoid robots, facial animation, and perceptual interfaces.
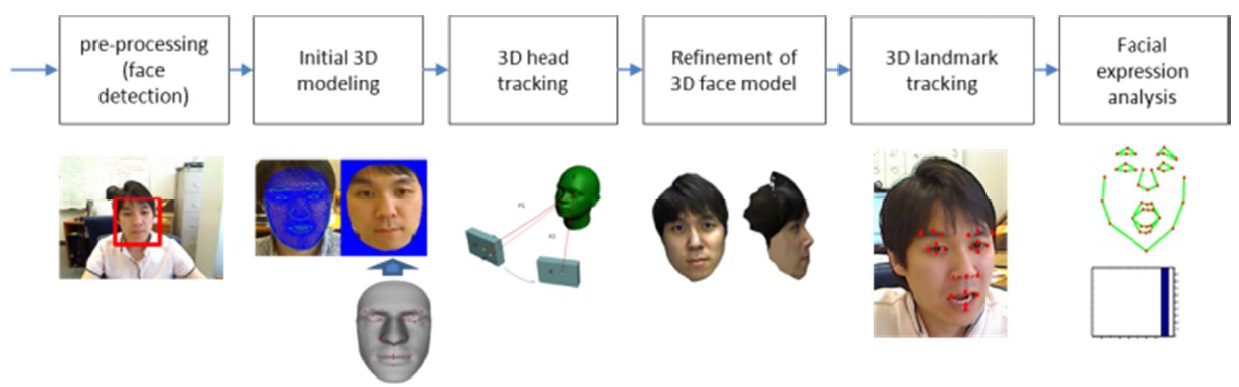
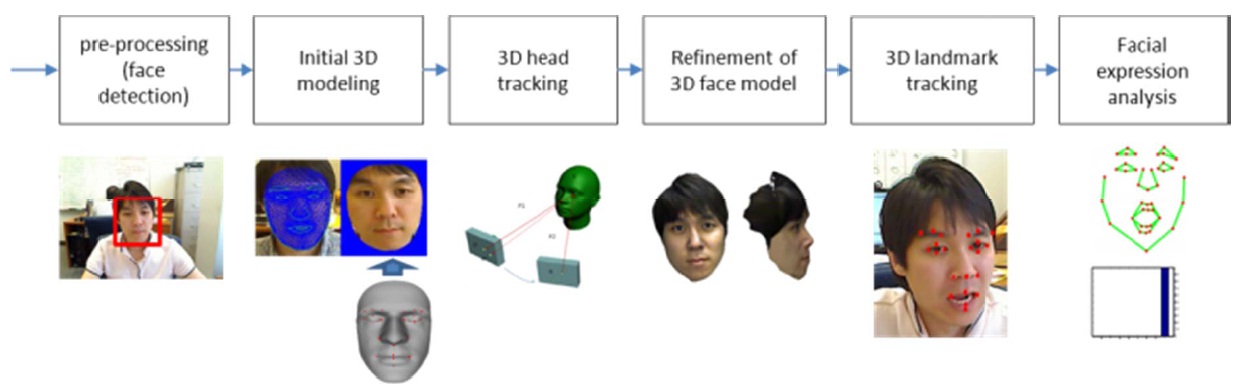
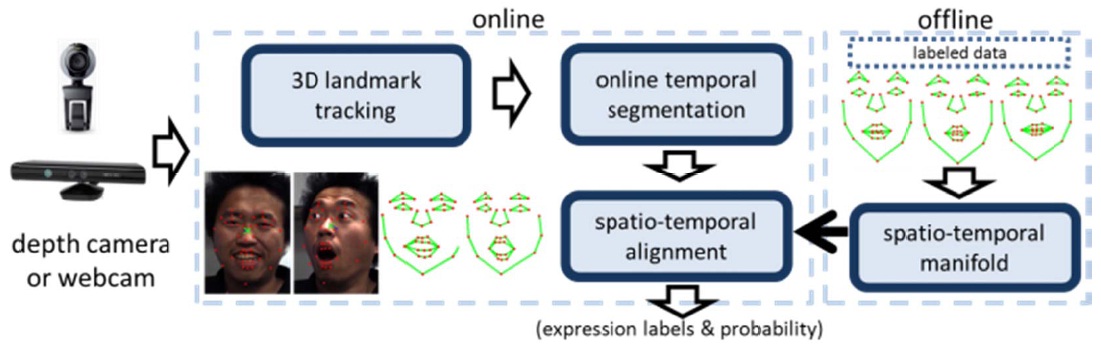
We aim to develop a prototype system that takes real-time video input from a webcam, tracks facial landmarks from a subject looking at the camera, and provides expression recognition results. The system includes use of a 3D generic face model [2,3], adaptation of the generic face model to a user, tracking of 3D facial landmarks, analysis of the set of expressions, and real-time frame rate implementation. The approach is illustrated in Fig. 1.
First, we use a real-time 3D head tracking module, which was developed in our lab [4], to track a person’s head in 3D (6 degrees of freedom). We use a RGB video as the input, detect frontal faces [5,6], extract facial landmarks from a neutral face [7-10], deform a 3D generic face model to fit the input face [3,4,10], and track the 3D head motion from the video using the updated 3D face.
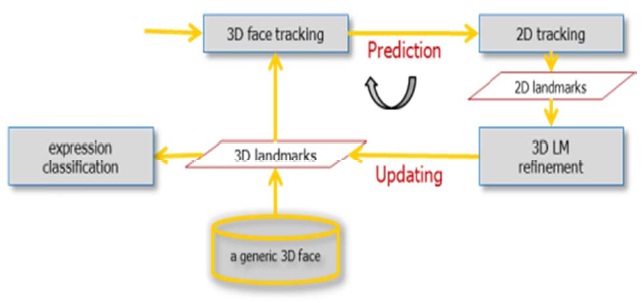
Second, the main contribution is a landmark tracking algorithm. We combine 2D landmark tracking and 3D face pose tracking. In each frame, we predict the locations of 2D facial landmarks using the 3D model, check the consistency between 2D tracking and prediction, and update the 3D landmarks. This integrated tracking loop enables efficiently
tracking the deformations of the non-rigid parts of a face in the presence of large 3D head motion.
Third, we have conducted experiments for facial expression recognition using a standard dynamic time warping algorithm. Our method provides a 75.9% recognition rate (8 subjects) with 7 key expressions (joy, surprise, fear, anger, disgust, sadness, and neutral).
The rest of the paper is organized as follows. Section II provides a short review of the related work. Section III des-cribes the proposed 3D facial landmark tracking, our approach to expression inference and the improvements needed, and preliminary experimental results using facial expression data-bases. Conclusions are given in Section IV.
Active shape models (ASM) [7,8,11] approximate 2D shape deformation as a linear combination of basis shapes which are learned using Principal Component Analysis [12]. An active appearance model (AAM) [8,13] learns not only shapes but also appearance models from texture information. 3D deformable models have also been proposed. A combined 2D+3D AAM is presented in [13]. In [14], Blanz and Vetter show a 3D morphable model for facial animation and face recognition. In [15], Gu and Kanade present a 3D deformable model consisting of sparse 3D points and patches associated with each point. Constrained local models, per-forming an exhaustive local search for each landmark around a current estimate and finding the global non-rigid shape parameters, are presented in [16].
Facial expression analysis in the presence of wide pose variations is important for interaction with multiple persons. In [17], Zhu and Ji proposed a normalized single value decomposition to estimate the pose and expression simulta-neously. Vogler et al. [18] uses ASM to track reliable features and a 3D deformable model to infer the face shape and pose from tracked features. Taheri et al. [19] shows that the affine shape-space, an approximation to the projective shape-space, for 2D facial landmark configurations has Grassmannian properties and non-rigid deformations can be represented as points on the Grassmannian manifold, which can be used to perform expression analysis without the need for pose nor-malization. Facial expression analysis is performed on tracked facial features [17,19,20], which can be represented in low-dimensional manifolds [21].
Our method leverages the accurate estimation of a 3D pose and surface model to infer non-rigid motion of 3D facial features. In addition, intra/interclass variations in the low-dimensional spatio-temporal manifold are handled by a novel spatio-temporal alignment algorithm to recognize facial expressions.
The goal of the system is, given as input a 2D video (taken from a webcam) of a face, to recognize in real-time the emotions expressed by the person. In order to perform the recognition, we need to collect appearance and shape in-formation and classify it into expressions. This information relies on facial motion and deformations. We consequently track a set of feature points, called
The approach starts with face detection. Then, we need to locate predefined key points on the face and to track them along the video stream. It is a difficult task; first, for ex-ternal reasons, changes in resolution, illumination, and occlusions occur regularly. The subject will probably move; the difficulty is not translations, but about rotations of the head (change of pose)―these change the appearance of the face. The next difficulty is the nature of the face; it is deformable and highly complex. We can differentiate bet-ween non-rigid landmarks, that are localized on deformable parts of the face and so much more difficult to track, and the rigid ones. These two categories require different kinds of tracking.
As shown in Fig. 1, our system is divided in three main modules: 3D face tracking, landmark tracking, and expression recognition. 3D face tracking, developed by our group, is described in [4]. It detects the face in a 2D image and fits a generic 3D model to it using ASM: 3D landmarks of the generic model are aligned with the 2D landmarks of the face found using ASM, allowing a warping of the generic 3D mesh to obtain a 3D model of the person.
To perform landmark tracking, we then have two sources of information: the 2D images from the webcam and the 3D face model that is simultaneously tracked. The idea here is to use a classic tracking algorithm to track the 2D landmarks, whose initial positions are obtained from the reconstructed 3D model and estimated 3D pose of the model. We can then monitor this 2D tracking using the tracked 3D model.
The difficulty here concerns non-rigid landmarks: their positions cannot be checked by the 3D model (which is rigid) and we need to rely only on the 2D image to track these de-formations. We have proposed and implemented a tracking loop that uses the information of the 3D model, a set of 3D landmarks corresponding to the 2D landmarks in facial images, to evaluate the 2D tracking, and the results of 2D tracking to update the 3D model (i.e., 3D landmarks). It can handle face deformation, using projection of the tracked points on an “authorized” area, determined by the natural constraints of the face (as a point of the inferior lip can only move vertically in a specific range in the 3D face reference frame).
>
B. 3D Facial Landmark Tracking
1) 3D Face Modeling and Tracking Using a Webcam
Described in [4], our approach consists of face detection, initial 3D model fitting, 3D head tracking and re-acquisition, and 3D face model refinement. We need a 3D model, which can either be a generic model, or a specific one retrieved from a database. In the initial 3D modeling step, the model is warped orthogonally to the focal axis in order to fit to the user’s face in an input image, by matching 2D facial land-marks extracted at runtime. Our tracker uses this 3D model to compute 3D head motion despite partial occlusions and expression changes, even in case of erroneous corresponding points. The robustness is achieved by acquiring new 2D and 3D keypoints along the tracking, for instance coming from a profile view. At each iteration, only the most relevant key-points, according to the camera field of view, are matched between the 3D model rendering and the input video.
In addition, we have a recovery mechanism in case the tracker loses track. Tracking failures are identified by a sharp decrease in the number of tracked features, and a background process matches features in the next frame(s) against the reference frontal face. Refinement of the 3D face model, a background process, improves the accuracy of 3D face tracking and 3D landmark tracking.
2) 3D Landmark Tracking
(a) Key idea
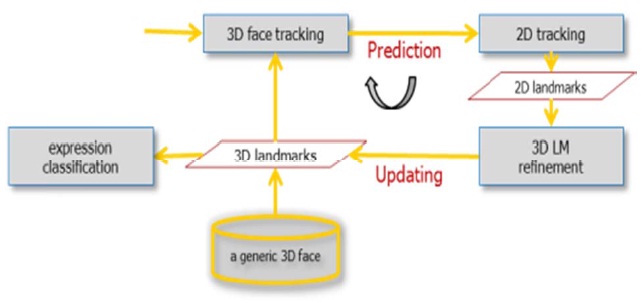
Our method consists of prediction of 2D landmarks and an update of 3D landmarks (See Fig. 2). At each iteration, we predict the 2D locations of all 3D landmarks using the estimated head motion. Then, we update some of the 3D landmarks if and only if our prediction does not explain the observed 2D points that are tracked by a 2D tracking al-gorithm from the previous frame.
The prediction process is done by 3D pose estimation. Given a 3D point (
In the comparison step, we compute the distance between a predicted location and a tracked location by a 2D feature tracker. If there are no expression changes or tracking errors, the locations should be the same. However, there are several sources of error, such as a 3D head tracking error, 2D landmark tracking error, and facial deformation.
We validate the quality of 3D face tracking by comparing the predicted and tracked locations from a set of rigid points. For instance, points on the nose should not be deformed and if the distances between projected nose points and tracked nose points are large, we can update the global 3D head motion by minimizing the re-projection error.
We represent the error between our prediction and obser-vations as
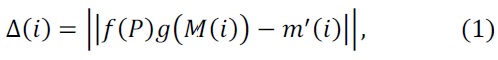
where
(b) Implementation of 3D landmark tracking
We describe the actual implementation of our 3D land-mark tracking loop. Fig. 3 shows the pipeline for each frame. Using the camera parameters for the frame
We use the Lucas-Kanade tracker (LKT) [22] to track our landmarks
We define several areas that have their own deformations (i.e., mouth, eyes, and eyebrows). What is important to the consistency of our tracking for an area is the distance
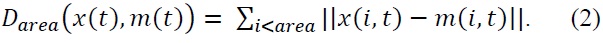
If this distance goes above a certain threshold, we go into the deformation step: the consistency of the tracked points
Fig. 3 shows the deformation step. In purple are the points defining the convex spaces on which the tracked points are projected, while the green points are the tracked points after the deformation step. Most of the authorized movements are defined by segments (upper and lower lips, eyelids, and eyebrows) but the corner points of the lips are projected into a triangle.
The points defining the convex spaces are taken from the 3D model, and we do a reverse projection of the tracked points
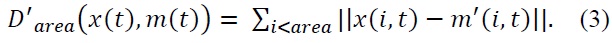
If the distance goes above a (larger) threshold, we use a stronger tracker for re-acquisition. However, in practice, the need for re-acquisition almost never occurs. Indeed, in case of motion, the deformation step helps the LKT by limiting potential drifting, and significantly reduces the impact of the aperture problem.
>
C. Facial Expression Recognition
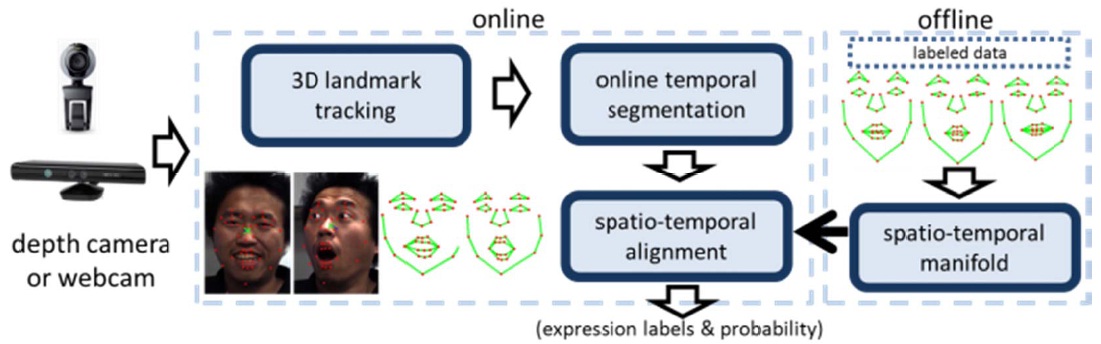
Since human facial expressions are dynamic in nature, we focus on expression recognition on a sequence of images. Fig. 5 shows the overview of our approach. Given a video input,
we perform online temporal segmentation and compute the distance between input data and stored labeled data using spatio-temporal alignment algorithms. In this paper, we focus on the spatio-temporal alignment. In the following sections, we describe the details of our approach.
1) Sequence-Based and Frame-Based Recognition
Understanding the dynamics of expression changes is im-portant. We can classify expression recognition methods into two categories: sequence-based and frame-based recognition methods. A sequence-based method uses a segmented sequence as an input to the system, while a frame-based method takes only a single frame. The segmentation is by a temporal segmentation algorithm or a sliding window technique. In general, a sequence-based method can provide more accurate results than a frame-based one since the neighbor frames are highly correlated and a sequence-based method utilizes a data fusion technique. However, sequence-based methods might have significantly delayed responses.
2) Recognition Using Sequences
We compute the distance between
Since the absolute scale of a shape is independent of facial expressions, we normalize each shape vector as
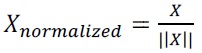
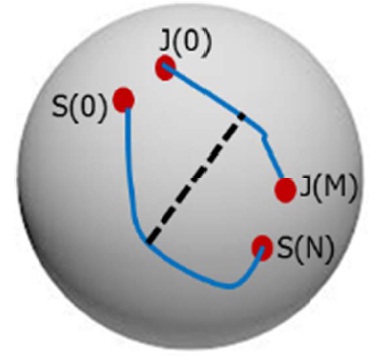
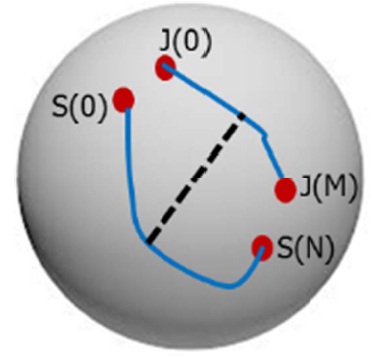
so all of the shape vectors lay on a unit hypersphere (Fig. 6).
Each observation, containing a set of shapes, is a sequence (a trajectory) on the sphere. The issue is that if we compare “joy” and “surprise”, the end points that depict the mouth opening might be similar to each other. Hence, we want to compare the entire sequences instead of comparing them only at the end points which correspond to static shapes (i.e., two frames or two set of landmarks).
The dynamic time warping (DTW) algorithm is a well-known method that aligns two data sets containing sequential observations [23,24]. We align two sequences using dy-namic programming and a distance function (we use the cosine distance between two landmarks). We then compute the Chebyshev distance between the two aligned sequences.
The Chebyshev distance between two points
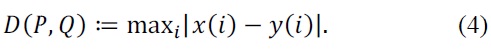
This equals the limit of the Minkowski distance and hence it is also known as the L-∞ norm. In our facial expression recognition, each aligned element represents the correlation value between signals. Hence, our distance is represented as
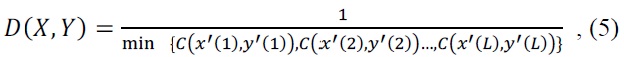
where
3) Evaluation of Facial Expression Recognition
We present two evaluation results of facial expression recognition. First, we present results of a frame-based method using the k-nearest neighbor (K-NN) algorithm. Second, we show results of a sequence-based algorithm using the DTW algorithm.
(a) Data and setup
We defined 7 expressions: joy, surprise, fear, anger, dis-gust, sadness, and neutral. We collected 182 (13 subjects × 7 expressions × 2 sessions) videos from 13 people (14 videos per subject).
To perform expressions, we showed subjects typical image search results from Google using corresponding keywords (e.g., “joy face”, “fear face”, “surprise face”, …). Each person was asked to sit in front of a webcam (0.8?1.2 m) for a short period (about 10 seconds for each expression) in an office environment. We controlled the distance from the subject to the camera so that the distance from the eye to the camera was in a range between 150?200 pixels. We collected two videos for each expression from each subject: session 1 and session 2. Videos from sessions 1 and 2 were used for training and testing, respectively. The image resolution was
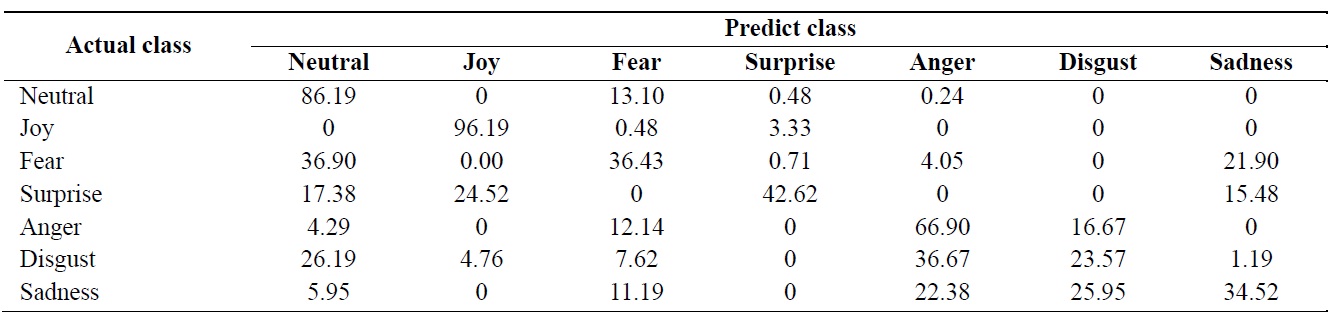
[Table 1.] Frame-based recognition rate (%) using k-nearest neighbor algorithm (average = 55.2%)
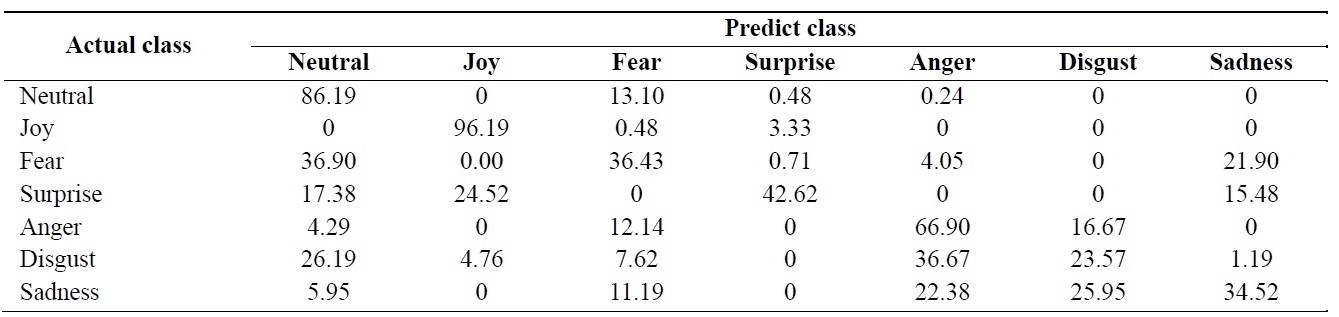
Frame-based recognition rate (%) using k-nearest neighbor algorithm (average = 55.2%)
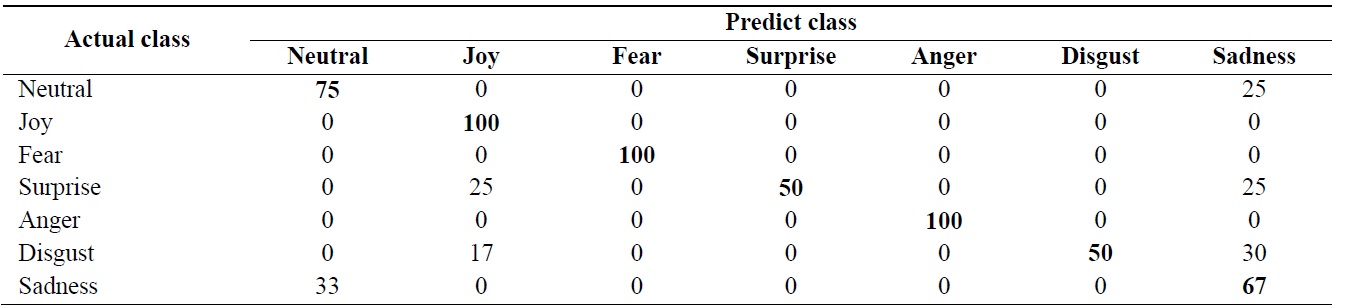
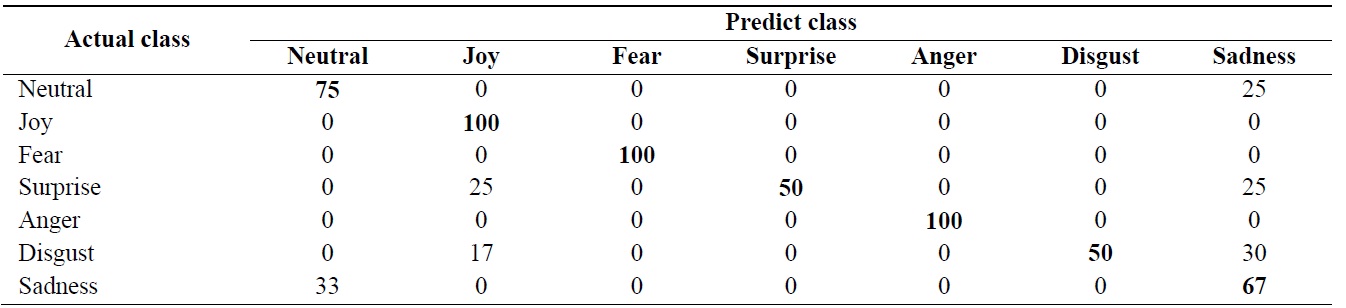
Sequence-based recognition rate (%) using dynamic time warping algorithm (average = 75.8%)
VGA (640 × 480) and we recorded videos at 15 fps.
(b) Experiment 1: using a single frame
We collected a subset of data containing 6 people’s videos: 42 videos from each session. From each video, we used 170 frames for testing. The gallery set contains 7,140 frames (170 frames × 7 expressions × 6 subjects) and the probe set has the same number of frames.
All of the landmarks are aligned to a single reference shape, which is the first shape from the first subject in the database. To align the two sets of 2D points, we compute the affine transformation using the homography relationship
We compute the distance between each frame (
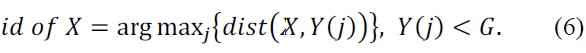
Table 1 shows a confusion matrix. The average recognition rate is 55.2%.
(c) Experiment 2: using a sequence
We used a subset of data for experiment 2. We built gallery datasets from all of the first videos (session 1) from 8 people’s data. The first gallery database included 29 tracked sequences from the subjects:
G = {g(1,1), g(2,1), …, g(7,1), g(1,2), …, g(Eg, Ng)},
where
P = {p(1,1), p(2,1), …, p(7,1), p(1,2), …, p(Ep, Np)}
where
g(i, j) = X = {x(1), x(2), …, x(N)} and p(k, m) = Y = {y(1), y(2), …, y(M)},
where each element of the sequence
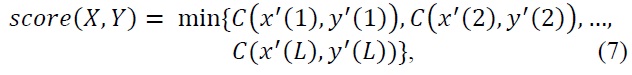
where
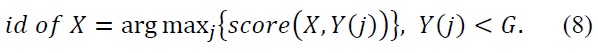
Table 2 shows a confusion matrix and the average re-cognition rate is 75.8% for the 7 expressions.
We present a system that is able to, from a low-resolution video stream, detect the face of a subject, build a 3D model of it, and track it in real-time, as well as obtain predefined facial feature points, the facial landmarks. Both rigid motion and non-rigid deformation are tracked, within a large range of head movements. In addition, we developed face recognition algorithms using a single frame and a sequence of images. We have validated our approach with a real database containing 7 facial expressions (joy, surprise, fear, anger, disgust, sad-ness, and neutral).
Further work will consist of improving the accuracy of both deformation tacking and face recognition algorithms. Updating the 3D face model should enable providing more accurate rigid and non-rigid tracking. Analysis of facial expression manifolds is one of the key tasks that needs to be investigated to improve the recognition rate.