Improving performance through increasing the clock speed of a single processor core is limited by high energy consump-tion and temperature. Thus, performance improvement utilizing multi-core processors has been actively studied [1]. Conse-quently, software structures should be changed to fully utilize the multi-core processor. In other words, there have been numerous researches on creating multiple threads in a single application and executing them in parallel to improve perfor-mance [2]. Therefore, the number of concurrently executing processes is steadily increasing, and it is becoming crucial to manage those processes effectively [3].
Process management under server environments has been previously studied. However, unlike processes running in a server environment, those executing in a multi-core desktop or a multi-core mobile platform have various correlations. There-fore, it is crucial to consider correlations among concurrently running processes [4].
We observe that a significant number of processes are not created directly by the user but depend on the coding style fol-lowed by the programmer when writing an application program.That is, there is an increasing trend that the process creation pat-tern and the process handling characteristics are not explicitly controlled by the user, but depend on the coding style used to write the application program. Especially, processes that are created and managed according to the specific style that was used to write the application are typically created at fixed loca-tions in the binary image of the parent process. We will show that the location where the process is created in the binary image of the parent process and the average running time of child processes residing in the run-queue are strongly corre-lated. We will also present that correlations between the process creation location and the average process execution time can be utilized for efficient system management, especially for process scheduling.
The rest of the paper is organized as follows. In Section II, related works on the characteristics and requirements of multi-core desktop and multi-core mobile device environments along with the application properties running on them are presented.In Section III, process correlations are addressed and our exper-imental method is presented in detail. In Section IV, we analyze our experimental results. Conclusions will follow in the final section.
There have been many researches on application properties under a multi-core desktop environment. Research in [3] stud-ied the degree of thread-level parallelism when applications were executed under a multi-core desktop environment. The results were analyzed. In [5], the authors presented that the response time characteristics when applications request I/O operations under a desktop environment differ from those under a server environment. In [6], recent theoretical results for dynamic power management of multi-core processors were summarized. In [7] and [8], methods to estimate the worst-case execution time of applications running on multi-core processors were proposed.
These previous researches have either focused on analyzing runtime characteristics that can be observed after each process is forked, or considering only the parent-child relationship between processes to predict and exploit processes’ runtime characteristics.
We suggest that the locations where processes are forked in the parent processes’ binary image provide a new clue to help analyze and predict the child processes’ runtime characteristics.And we examine how the new clue can contribute to predicting and exploiting the child processes’ runtime characteristics through experiments.
III. LOCATION-BASED PROCESS MANAGEMENT
We observe that a significant number of processes are created by the coding patterns used to write an application program. Even though the number of concurrently executing processes and the execution patterns are partially dependent on the system user, they are also significantly dependent on the style in which the programmer writes the application. Consequently, it is impor-tant to understand how processes are created by applications, and what characteristics are possessed by each process.
The child processes are typically created at specific locations of the parent processes’ binary image. That is, when program-mers write applications, they call specific library routines or system calls to create child processes. Therefore, locations where many child processes are created can be clearly identi-fied. We will use the name of the binary image of the parent process and the program counter value for the location where the child process is created from the image. These are attached to each child process as process attributes. We claim that the behavioral patterns are correlated with these two attributes, and we verify this claim experimentally. To be precise, we measure the average execution time of child processes residing in the run-queue, and analyze the correlation between this time and the two attributes. Through this analysis, we devise a novel pro-cess management method to improve the system performance.
Our experimental environment is based on Linux Kernel 2.6.31.6 and GNU Library C 2.11.2 and we modified these in order to understand the behavior. An off-line analysis result of the data collected from this environment is stored in a table so that the kernel operation can refer to it. By utilizing the infor-mation collected by the off-line analysis, the overall perfor-mance is significantly improved.
>
A. Process Creation of Linux Systems
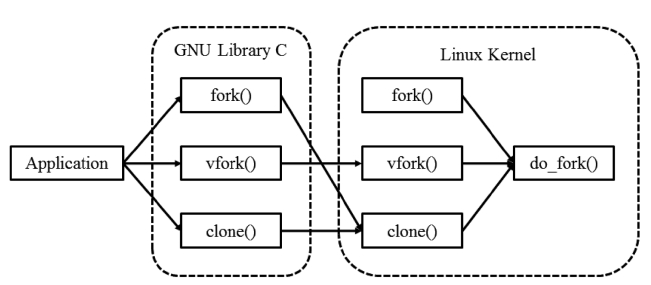
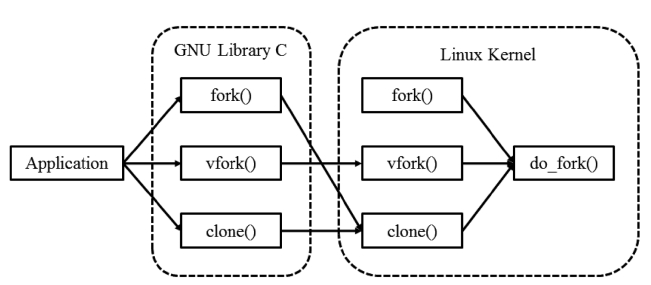
Processes are created using fork(), vfork(), and clone() sys-tem calls in Linux systems. However, it is uncommon for appli-cation programs to invoke these system calls directly. Instead, these system calls are usually called indirectly via the fork(), vfork(), and clone() library functions provided by GNU Library C. In the Linux kernel, the do_fork() function is called to actually carry out the process creation task for the fork(), vfork() and clone() system calls.
>
B. Data Collection for Process Creation Location and The Average Execution Time
To understand the correlation between the process creation location and the process behavior, first we need to collect the information on the locations (i.e., program counter values) where the child processes are created. To this end, we modified the routines for process creation in the GNU Library C and the
Linux kernel. First, we collect the return addresses that are stored in the applications’ stack for the fork() and clone() func-tions. Since vfork() passes the return address to the kernel, no modification is necessary. These return addresses correspond to the program counter values where the child process is created. The collected return addresses are passed to the Linux kernel as arguments for system calls, and stored in a data structure.
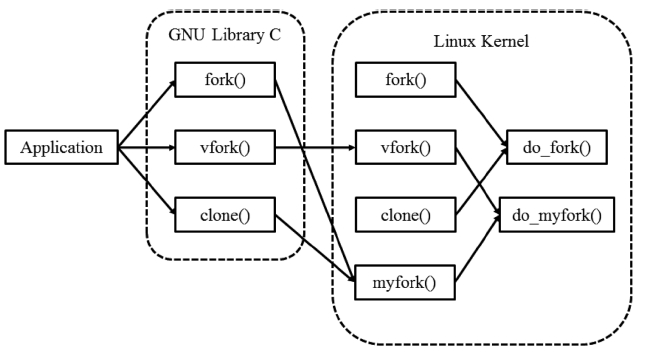
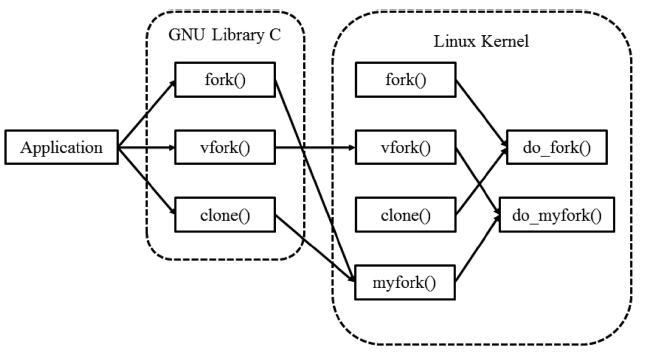
To pass return addresses, system call interfaces should be changed. However, changing the interface of the original sys-tem calls can be a very dangerous operation, which may cause the system operation to become unstable. Therefore, we imple-mented a new wrapper function called myfork(), so that this wrapper function is called instead of the original one when we collect the information. We also add a new wrapper function for do_fork() called do_myfork(), so that the myfork() and vfork() system calls will call the wrapper for do_fork(). Function do_myfork() stores the collected data, which consist of the name of the binary image of the parent process and the program counter value indicating the location of the child process cre-ation in the image, in the data structure. It also performs the original function of creating processes. A simple routine is added to the system calls fork() and clone() and function do_fork() that enables them to print out kernel error messages every time that the calls are invoked under exceptional circum-stances. In this manner, the original do_fork() is called when the calling sequence fails to follow the proposed modified process creation path. In this case, we can identify the exceptional cases by the printed kernel error message.
Also, we need to collect the average runtime, which is defined as the time during which each process is residing in the run-queue. We collect the information by modifying the process scheduler of the Linux kernel, which has a scheduler called completely fair scheduler (CFS). In CFS, each run-queue is implemented using a red-black (RB) tree structure [9]. The average execution time of each process can be obtained by com-puting the average duration time between the time when the process is inserted into the RB tree and the time when the pro-cess is removed from the RB tree. The Linux kernel calls the update_curr() function to compute the actual execution time of the current process on the processor. In our experiment, we modified the update_curr() function to store the execution times in a separate data structure in addition to performing the origi-nal function.
Using all the collected data of the binary image, the program counter values, and the average execution times, we can com-pute the average time that each child process resides in the run-queue after it was created at a specific location of the binary image of the parent process.
>
C. Utilization of Correlation between the Process Creation Location and the Average Execution Time
We claim that depending on the location of the child process creation, the average execution time can differ significantly, and we used the collected data to verify this property. In the Linux scheduler, a process with a relatively short execution time is assumed to have a more interactive property than that with a large execution time. Hence the scheduler assigns a higher pri-ority to such processes in order to improve the overall response time. In reality, the CFS incorporates the actual execution time of each process into the process priority and computes the virtual runtime after normalization. After computing the virtual runtime, on scheduling a process, it selects the process with the shortest virtual runtime for execution. However, this algorithm has a limit that even though an interactive process is created, it can only get CPU-time if it has the smallest computed virtual runtime.
On the other hand, the proposed method in this paper is based on an offline analysis on the average execution time. If the location where processes are created in the binary image of the parent process and the average running time of the child processes residing in the run-queue are strongly correlated, we could exploit the correlation to predict the interactivity of the newly created child processes at each location. Thus, when interactive processes are likely to have a shorter runtime, based on the analysis they may be scheduled to the CPU before CFS, thus shortening the overall response time. From our experi-ments, we verified that such interactive processes are executed immediately after creation, without waiting until they have the smallest virtual runtime. Thus, the overall performance is improved.
Our experimental environment is a virtual machine environ-ment running on a platform that consists of Intel Core i7-2600 3.40GHz, 4GB of RAM, Windows 7 (32bits). Data collection and scheduler modification are done on Linux Kernel 2.6.31.6 and GNU Library C 2.11.2. We used a set of applications on Firefox [10] consisting of streaming audio play, web game play, and webpage surfing. In addition to the experiment on Firefox, we also carried out experiments on the Make utility and Ope-nOffice [11].
To analyze the correlation between the location of the pro-cess creation and the average runtime, first we ran the Firefox web browser on a Linux system after we modified the system as explained.
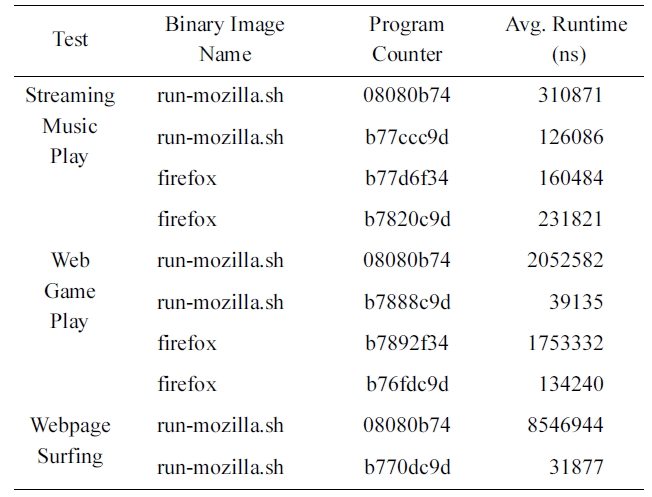
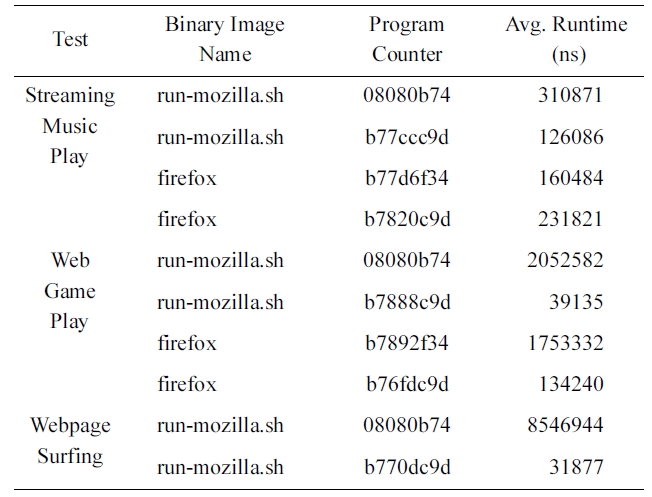
Table 1 summarizes the results. The set of locations for child process creation differs according to the running application, and the average execution times differ according to the values of the program counter. Also, we can verify from the case of the binary image called
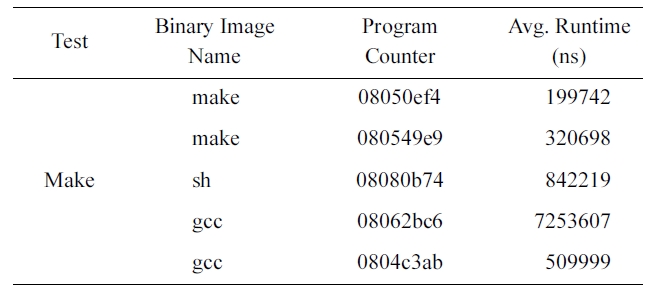
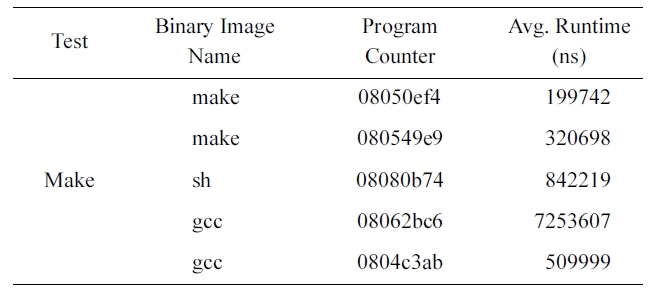
Next, we compiled the Linux kernel with the Make utility. Table 2 shows the results. As in the cases of the web browser, the average execution times differ according to the program counter and the binary image name.
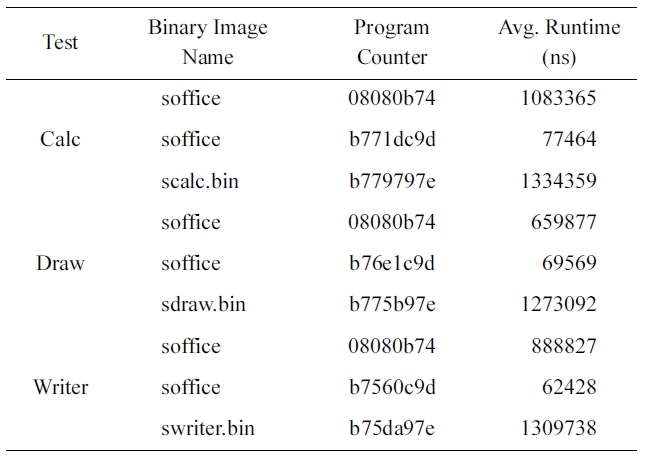
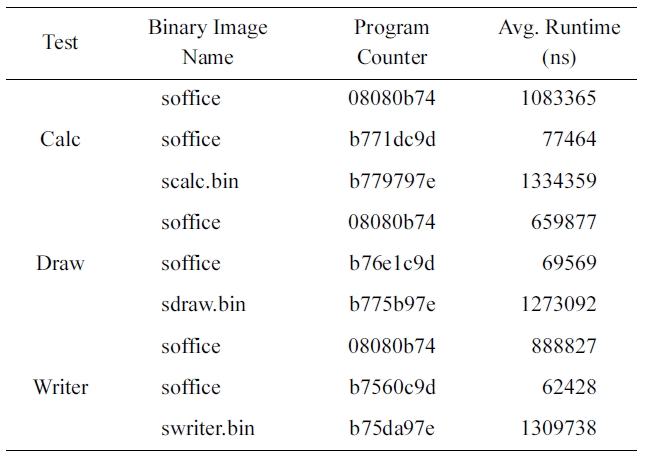
Finally, Table 3 shows the results obtained from running OpenOffice. We ran a spreadsheet program (Calc), a 2D paint-ing program (Draw), and a word processing program (Writer) in OpenOffice. In the spreadsheet program, we entered some num-bers and then calculated the average and the standard deviation of the data. In the 2D painting program, we drew simple figures and colored them. In the word processor program, we typed a
[Table 1.] The average execution time for process creation location on Firefox
The average execution time for process creation location on Firefox
[Table 2.] The average execution time for process creation location on theMake utility
The average execution time for process creation location on theMake utility
[Table 3.] The average execution time for process creation location on OpenOffice
The average execution time for process creation location on OpenOffice
short text and carried out spellchecking.
We can infer from the above results that the average execu-tion times of the child processes differ according to the creation location in the parent process’s binary image.
This section will address how we can utilize the correlation information to improve the overall system performance. For this
[Table 4.] Comparison of execution times between the conventional and proposed methods
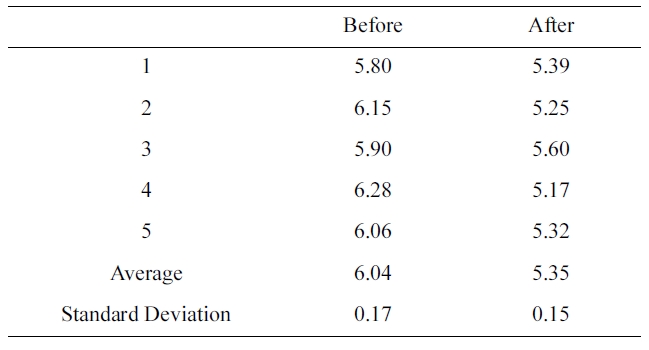
Comparison of execution times between the conventional and proposed methods
purpose, we modified the scheduler such that the process with the shortest average runtime from the offline analysis of the binary image and the process creation location will get CPU - time after being assigned the highest priority immediately after its creation.
In this experiment, we mainly used web browser executions, since the web browser runs a variety of workloads under a sin-gle application [12]. Experimental results show that when streaming audio decoding and web surfing are executed concur-rently, streaming audio decoding is finished earlier, since its average execution time is relatively shorter.
As the number of concurrently executing processes on multi-core desktops or mobile devices is rapidly increasing, it is cru-cial to manage such concurrent processes efficiently. Unlike processes running in a server environment, those executing in a multi-core desktop or a multi-core mobile platform have various correlations. Therefore, it is crucial to consider correlations among concurrently running processes. In this paper, we exploit the property that depending on the created location of child pro-cesses in the binary image of the parent process, the average running time of the child process residing in the run-queue dif-fers. To verify this property we modified the Linux kernel and GNU Library C, and carried out experiments. Through the experiments, we could verify that the average execution time of the child process may differ according to the binary image of the parent process and the location of the child process creation.Also we modified the kernel scheduler such that we assign a higher priority to processes with shorter average runtime when they are invoked at specific locations. The experimental results show that when we execute streaming music play and web browsing in parallel, the average execution time of the stream-ing music play is shorter. This verifies that our proposed sched-uling method is effective and is sufficiently accurate to achieve overall performance improvement. Lastly, we have found additional possible correlations in the process creation locations, and methods to exploit these addi-tional correlations for optimiz-ing process management. Especially, we are seeking to exploit the child processes’ average running time according to the cre-ated location as a workload weight of each child process in order to calculate the effective workload of each core in multi-core systems.