이상적 저자-망은 그 노드가 저자를 표현하도록 정의된다. 그러나 실제 자동 생성되는 대부분 저자망의 노드는 저자명을 저자 식별자로 사상시키는 어려움으로 인해 단순히 저자명으로 표현된다. 실 세계 저자를 표현하기 위해 이처럼 저자명을 사용하여 저자망을 구성하는 것은 서로 다른 동명 저자들이하나의 저자명 노드로 병합됨으로 인해 저자망의 특성을 왜곡하는 문제가 발생한다. 이 연구는 공저관계에 의존하여 저자명이 갖는 중의성을 해소하고 저자 노드로 구성된 저자망을 자동 생성하는 알고리즘을 제시한다. 공저자 자질의 특성상 이 알고리즘은 과소군집오류를 희생하면서 과다군집오류를 최소화하는 군집 결과를 만든다. 실험에서는 한글 동명 저자명이 출현한 실제 서지레코드 집합을 대상으로 알고리즘의 적용 결과를 제시한다.
저자명 네트워크(저자명 그래프)는 저자명을 노드로 저자명 사이의 관계(인용, 공저 관계 등) 유무(및 강도)를 노드 간 링크(및 링크강도)로 두고 만들어진 그래프이며, 저자 네트워크(저자 그래프, 저자망)는 노드가 저자이며노드 간 링크가 저자 관계인 그래프이다. 저자명과 저자의 차이는 이름과 사람의 차이와 같다. 한 사람이 복수 개 이름 표기를 사용할 수 있다는 측면에서 저자명 그래프에서 동일 연구자를 지칭하는 복수 개의 저자명 노드들은저자 그래프에서 하나의 저자 노드로 병합되어야 할 것이다. 또한 서로 다른 사람들이 동일 이름 표기를 사용할 수 있다는 측면에서 저자명 그래프에서 서로 다른 실 세계 연구자를 지칭하는 하나의 저자명 노드는 저자 그래프에서 복수 개의 저자 노드로 분할되어야 할 것이다. 이처럼 저자명 표기에 기초하여 구축되는 저자명 네트워크는 실 세계 저자들의 근본특성을 왜곡하는 위험이 있다. 한 언어로 한정된 경우는 다양한 저자명 표기들에 대한 표준형(canonical form)으로의 정규화를 통해 전술한 병합의 문제가 상당히 완화될 수 있다. 그러나 서로 다른 언어(예: 한국어, 영어 등)사이의 저자명 표기 정규화는 한 언어에서의 이름 표기가 다른 언어로 변환될 때 개입되는정보의 손실 및 자의성1)으로 인해 어려움을 겪을 수 있다.
본 연구에서는 서지레코드로부터 저자 그래프를 만드는 시도를 한다. 기본 아이디어로 공그래프(null graph)에서 출발하여 저자명 노드가 아닌 저자 노드를 추가하면서 저자 그래프를 점증적으로 만든다. 또한 전체 저자 집합에 대한 저자 그래프 생성 문제를 특정 저자에 대해 저자 그래프를 생성하는 부분 문제로 분해하여 생각한다. 전술한 부분 문제를 단위저자 그래프(unit author graph) 생성이라 정의하고 본 연구에서는 단위저자 그래프 생성문제에 집중한다. 단위저자 그래프의 활용 예로 학술정보시스템에서 특정 저자명에 대한 검색이 발생할 때 해당 저자명이 출현한 서지레코드에 대해 단위저자 그래프를 생성하여 사용자에게 제시할 수 있을 것이다. 이후 특별한 언급이 없는 한 이 논문에서 용어 ‘저자 그래프’는 단위저자 그래프를 지칭하기 위해 사용할 것이다.
이 연구가 다루는 저자 그래프 생성은 서지레코드에 출현한 같은 저자 이름들을 실 세계저자에 대응하는 식별자로 사상시키는 저자식별의 문제와 다르지 않다. 군집화 관점에서 고찰할 때 저자식별은 식별 대상이 되는 n개의동일 표기 저자명(개체)들에 대해 임의의 두 개체 사이에 계산되는 거리/유사도 값에 의존하므로 계층적 군집법의 경우 최소 O(n2)의 시간 복잡도를 요구한다. 일례로 최근의 대용량 저자식별 실험은 고정된 15.3백만여 건 서지레코드집합(2006년 MEDLINE 논문)에 출현한 46.7백만여 저자명들을 저자 식별자로사상시키는데 4대의 컴퓨터(듀얼코어, 메모리4G)에서 총 3주의 시간이 소요되었으며 개체쌍 유사도 계산을 시간 지연의 주요 원인 중하나로 보고하였다(Torvik et al. 2009). 본연구에서는, 저자의 구분은 그의 공동저자에 의존한다는, 공저자 식별가정에 기반하여 저자를 식별하는 방식을 사용하며 O(n)의 시간복잡도를 요구하는 저자 그래프 생성 알고리즘을 제안한다.
논문의 구성은 다음과 같다. 2장에서 관련연구를 기술한다. 3장에서 공저자 기반 저자그래프 생성 과정을 예와 함께 설명하고, 4장에서 저자 그래프 생성 알고리즘을 제시한다. 5장에서는 한글 서지레코드로부터 실제 저자그래프를 생성한 사례를 소개하고, 6장에서토론 및 결론을 기술한다.
1) 저자명 홍 길동 의 로마자표기법은 Hong, Gil-Dong이나 이 저자명을 G.D. Hong 혹은 G. Hong으로 써서 정보의 손실을 일으키거나 새롭게 작명된 David Hong 혹은 D. Hong으로 쓸 수도 있다.
저자식별2)은 서지레코드 내에 출현한 동일표기 저자명 개체집합을 입력 받아 저자명 개체쌍의 유사도 혹은 거리를 계산한 다음 이를 바탕으로 실 세계의 동일인으로 추측되는 유사 저자명 개체들을 병합하는 과정으로 수행된다. 저자명 개체쌍의 유사도 계산을 위해 일반적으로 각 저자명 개체를 자질(fea- ture)들(논문제목, 공동저자명, 게재지명, 전자메일주소, 소속 등)을 벡터로 표현하고 이러한 개체 벡터쌍에 대해 코사인 거리, 유클리디언 거리 등의 유사도 수식을 적용한다. Song 등(2007)은 외부적으로 관찰되는 표층 자질들이 갖는 중복성, 비독립성 등의 악영향(Tor- vik et al. 2005)을 줄이기 위해 PLSA (Hofmann 1999), LDA(Blei et al. 2003) 기법을 통해 표층 자질들을 새로운 자질 공간으로 변환시키는 시도를 하였고 저자식별 성능의 큰향상을 보고하였다. 이와 관련하여 Huang 등(2006)과 강인수(2008)는 수작업으로 저자식별된 저자명 개체가 출현하는 서지레코드를 학습데이터로 사용하여 SVM, K-NN 등의 기계학습기법을 적용하여 유사도 함수를 학습하는시도를 하였다.
저자명 개체쌍 유사도에 기반하여 유사 저자명 개체들을 병합하는 군집화에서는 대부분 single linkage, complete linkage 등의 계층적 군집법이 사용되었으나, Huang 등(2006)은 저자식별의 이행성(transitivity) 위배 문제를 다루기 위해 DBSCAN 군집법을 시도하였다.
저자식별의 실질적 성능 향상 측면에서 공동저자명, 전자메일주소, 소속, 저자 홈페이지등의 영향력 있는 자질(Torvik et al. 2009)의 획득은 큰 기여를 한다. Kang 등(2009)은웹에 표현된 서지정보로부터 특정 연구자의공동저자들을 자동 수집하는 시도를 하였으며저자식별의 성능 향상을 보고하였다. 특정 연구자의 홈페이지에서 관리되는 출판 논문 리스트 정보는 가장 신뢰할 만한 자질 중 하나로 최근까지 여러 연구(Tan et al. 2006; Pereira et al. 2009)에서 그 효과를 보고하였다. 논문의 원문으로부터 획득되는 전자메일주소와 소속 자질 또한 사회에서 한 개인을 특정하는 역할을 하므로 저자 식별에 기여하는바가 크다. 그러나 서지레코드와 연결된 논문원문과 저자 홈페이지 자질은 항상 획득 가능하다고 가정할 수 없어 자질 적용률(coverage)이 낮을 위험이 내재되어 있다. 강인수 등(2008)은 한글 저자식별에서 논문제목, 게재지명, 참고문헌 자질과 함께 전술한 자질들의특성을 비교하고 있는데 이 중 공동저자 자질은 출현 보편성과 적용 위험성 측면에서 단일자질로서 가장 효과적임을 보고하였다.
기존 저자식별 연구들은 저자식별의 성능(effectiveness) 향상을 위한 자질의 획득, 개체유사도계산법/군집법의 적용 및 개발 연구에 집중하였다. 이와 달리 본 연구는 식별 과정의 시간 복잡도(efficiency)를 개선하는 시도이다.
사회망 연구에서 저자 네트워크, 저자망, 혹은 저자 그래프(author network, author graph)는 전역적, 지역적측면에서 고찰 및 분석되어 왔으며 이 연구가 다루는 저자 그래프 생성은 지역적 측면과 관련이 깊다. 저자망의 전역적 분석은 수학, 의학, 컴퓨터과학 등 특정 연구 분야의 대용량 서지DB로부터 얻어진 저자망에 대해 giant component3), clustering coefficient4), mean distance5), centrality6)등 망의 전체적 특성을 설명하려는 시도이다(Braun et al. 2001; Newman 2004a; 2004b; Elmacioglu & Dongwon 2005; Liu et al. 2005; Tomassini et al. 2007).
저자망의 지역적 분석은 개별 연구자, 특정연구기관 혹은 구체적 연구 주제와 관련된 연구자 커뮤니티(research community, scientific collaboration network)를 대용량 서지DB에서 얻어진 저자망 내에서 찾고 그 특성을 밝히려는 시도이다. 그래프로 표현된 망 내에서 어떤 노드(vertex, node)들의 그룹이 내부노드들 상호간 연결(edge, link)이 조밀하면서 그룹 외부 노드들과의 연결이 상대적으로희박한 경우 해당 그룹은 커뮤니티 구조를 갖는다고 말하며 커뮤니티는 클러스터와 다르지 않다(Fortunato 2010). 사회망(social network)의 특성을 갖는 저자망의 경우 커뮤니티구조를 보인다고 알려져 있으며 저자망 내의커뮤니티(들)은 공동 연구 그룹(들)을 의미한다. 커뮤니티 인식(community detection)은 그래프 내부의 커뮤니티(들)을 찾는 것이며 개체 집단 내의 유사 군집(cluster, 클러스터)들을 찾는 군집화(clustering, 클러스터링)와 유사하다. 커뮤니티 인식을 위해 전통적인 계층적 군집법(hierarchical clustering)을 포함하여 betweenness에 기반한 Girvan-Newman알고리즘(Girvan & Newman 2002), modularity기반 기법(Newman 2004c) 등이개발되었다. 이 연구가 다루는 저자 그래프 생성은, 노드가 저자명(예: J. Smith)인 저자망에 대해 동명 저자 각각(예: MIT의 J. Smith,CMU의 J. Smith 등)의 연구자 커뮤니티를 찾고 최초 저자망의 동명 저자명 노드(예: J.Smith)를 커뮤니티 수만큼 분할하는 과정에 해당한다.
3) 그래프 내에서 가장 큰 connected subgraph로 학문 분야가 태동기로부터 성숙기로 변하면서 새로운 공동 연구관계의 발생으로 인해 giant component가 점차 커지는 경향을 보인다. 4) 노드(들의 집합)이 다른 모든 노드들과 연결된 정도이며 저자망 내 공동연구의 정도를 가늠할 수 있다. 5) 임의의 두 노드 간 최단거리의 평균으로 저자망과 같은 사회망의 경우도 대부분 6을 넘지 못하며 이는six degrees of separation과 관련성이 있다. 6) 대용량 저자망 내에서 중심적(central, prominent) 저자를 찾기 위해 사용되는 지표로 betweenness, closeness등이 있다.
저자 그래프 생성을 위해서는 저자 그래프에 저자명 노드가 아닌 저자 노드를 추가하는 절차가 요구된다. 이상적 저자 노드는 실 세계에서 한 개인의 신원을 결정할 수 있는 고유번호(주민등록번호, social security number 등)로 식별되는 노드일 것이다. 그러나 이러한 개인 신상정보는 오남용의 우려로 공개 및 확인이 쉽지 않다. 가상공간에서의 개인의 준고유번호인 전자메일주소는 적절한 대안이 될 수있으나 메일주소를 포함하는 학술문헌 원문의확보 및 정확한 자동 인식이 전제되어야 하는 어려움이 따른다. 이 연구에서는 한 저자의 신원이 그 저자와 공동 연구를 수행한 다른 저자들에 의해 결정된다고 하는 다음 공저자 식별가정에 기초하여 저자 노드를 표현한다.
공저자 식별가정: 한 저자의 신원은 그저자의 공동저자(들)에 의해 결정된다.
즉 이름이 ‘홍길동’인 수많은 동명이인들 중 다음 서지레코드 R1에 출현한 특정한 홍길동 을 지칭하기 위해 공저자들을 사용하여 “김철수와 이영희가 알고 있는 홍길동”이라는 방식을 사용한다. 이것은 저자 그래프에서 R1의 홍길동 을 저자 노드로 표현할 때 “공저자김철수, 이영희가 알고 있는 홍길동”이라는 의미를 갖게 됨을 의미한다.
R1: 홍길동, 김철수, 이영희. (2009). 스마트 폰 운영체제 특성 비교. JCSE,10(5):34-45.
공저자들은 많을수록 R1의 홍길동을 보다 더 특정할 수 있을 것이다. 그러면 반대로 R1의 홍길동 을 지칭하기 위해 최소 몇 명의 공저자(명)가 필요한가? 하나의 공저자명 ‘김철수’만을 고려한다면 “공저자 김철수가 아는 홍길동”으로서 저자 그래프 내의 저자 노드 (R1의) 홍길동을 표현하게 될 것이다. 그러나 “공저자 김철수가 아는 홍길동”이라는 표현은 이세상에서 이름이 홍길동인 동명이인 홍길동의전체집합을, 이름이 김철수인 사람이 아는 홍길동과 그렇지 않은 홍길동으로 구분할 수는 있으나 서지레코드 R1의 저자 홍길동을 유일하게 지칭하지 못할 수 있다. 그 이유는(a) 이름이 김철수인 사람이 이 세상에 한 사람뿐이라 하더라도 그 사람이 아는 동명이인 홍길동들이 여러 명일 수 있으며, 일반적으로는 (b)동명이인 김철수들 각각이 서로 다른 동명이인 홍길동을 알고 있을 수 있기 때문이다. 그러나 사람의 집합을 학술연구자들의 집합으로 제한하면 (a), (b)의 가능성은 상당히 감소할 것이다. 또한 학술연구자의 집합을 인문학, 자연과학, 공학 등으로 분류한 다음 공학을 다시 전기, 전자, 컴퓨터 등으로 분류하는 식으로 세분해 나가면 소분류 학문 분야에 해당하는 학술연구자집합 내에서(a), (b)의 가능성은 급격히 줄어들 것이다. 예를 들어 컴퓨터 분야에서 ‘홍길동’, ‘김철수’라는 이름이 동시에 출현한 서지레코드 집합 S 내에서 위의 (a), (b)의가능성은 거의 찾기 힘들 것이다. 즉 S는 수많은 동명이인 홍길동(혹은 김철수)들 중 특정한한 사람 홍길동(혹은 김철수)의 논문들로만 구성되었을 가능성이 극히 높을 것이다. 위에서 학문 분야 분류는 학술문헌이 출판되는 저널, 학술대회발표논문집 등 게재지들을 분류함으로써 가능하다.
R1의 홍길동을 지칭하기 위해 2인의 공저자(예: 김철수, 이영희)를 사용하는 것은(다른 동명이인 홍길동 들이 아닌) R1의 홍길동만이 작성한 서지레코드를 수집하기 위해 ‘홍길동’,‘김철수’, ‘이영희’가 동시에 출현한 서지레코드를 찾아야 하므로 R1의 홍길동 이 작성한 학술문헌의 전체 집합을, 1인의 공저자를 사용한 경우에 비해, 더 정확하게 인식할 수는 있겠으나 그 크기를 지나치게 제한할 수 있다.
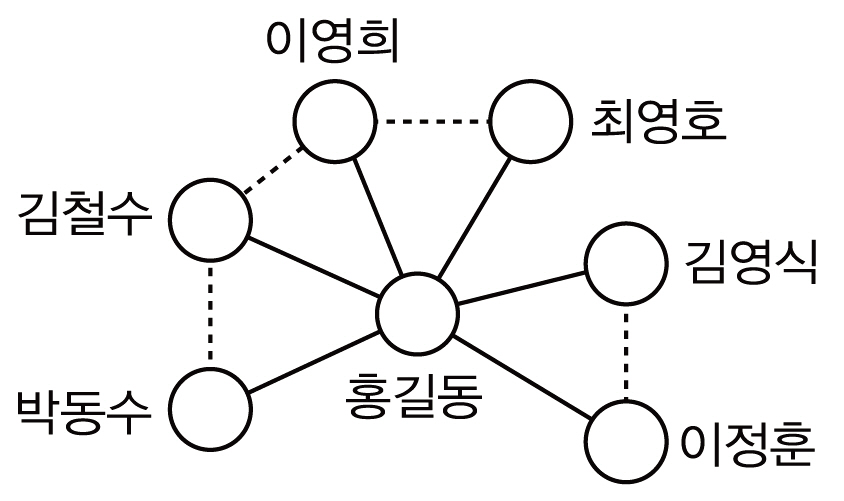
다음 서지레코드 R1~R6에 대해 저자명 그래프와 저자 그래프를 생성하는 것을 고려해보자.
R1: 홍길동, 김철수, 이영희. (2009). 스마트 폰 운영체제 특성 비교. JCSE, 10(5):34-45.
R2: 박동수, 홍길동, 김철수. (2008). 아이폰 운영체제의 문제점. OS, 7(4):14-21.
R3: 홍길동, 김영식. (2007). 위키피디아로부터의 정보추출. IE, 26(1):1-10.
R4: 김영식, 홍길동, 이정훈. (2008). 온톨로지 기반 정보검색. IR, 15(2):21-29.
R5: 이영희, 홍길동, 최영호. (2007). 임베디드 S/W 산업 동향. JES, 18(4):13-27.
R6: 홍길동. (2009). 안드로이드 vs. 아이폰 S/W 호환성 이슈. JOS, 8(1):34-41.
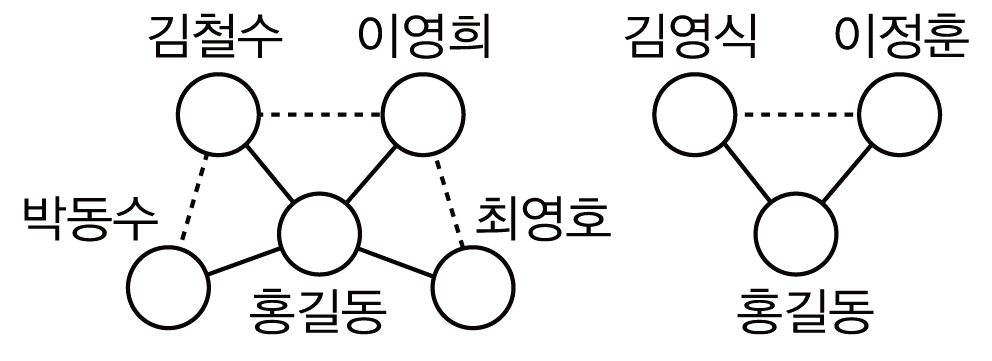
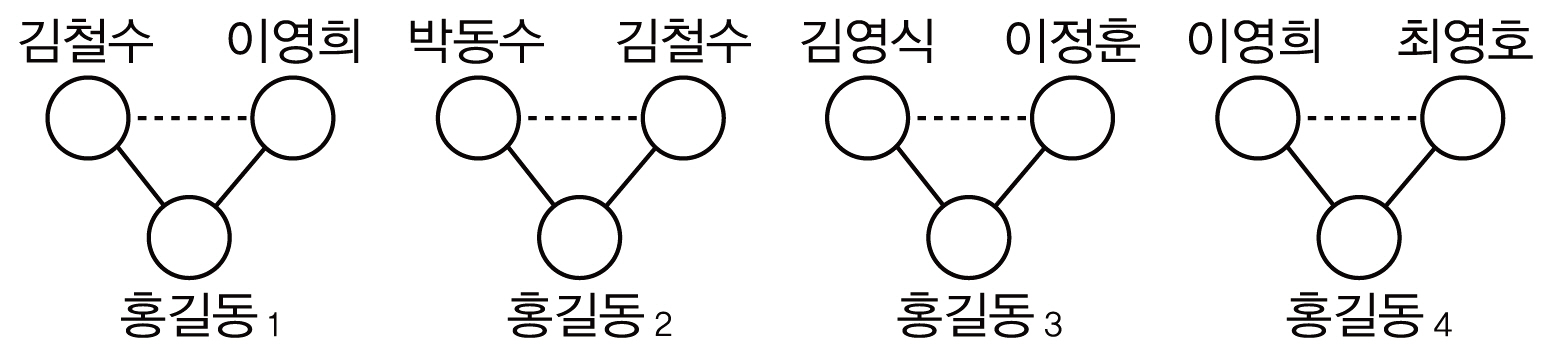
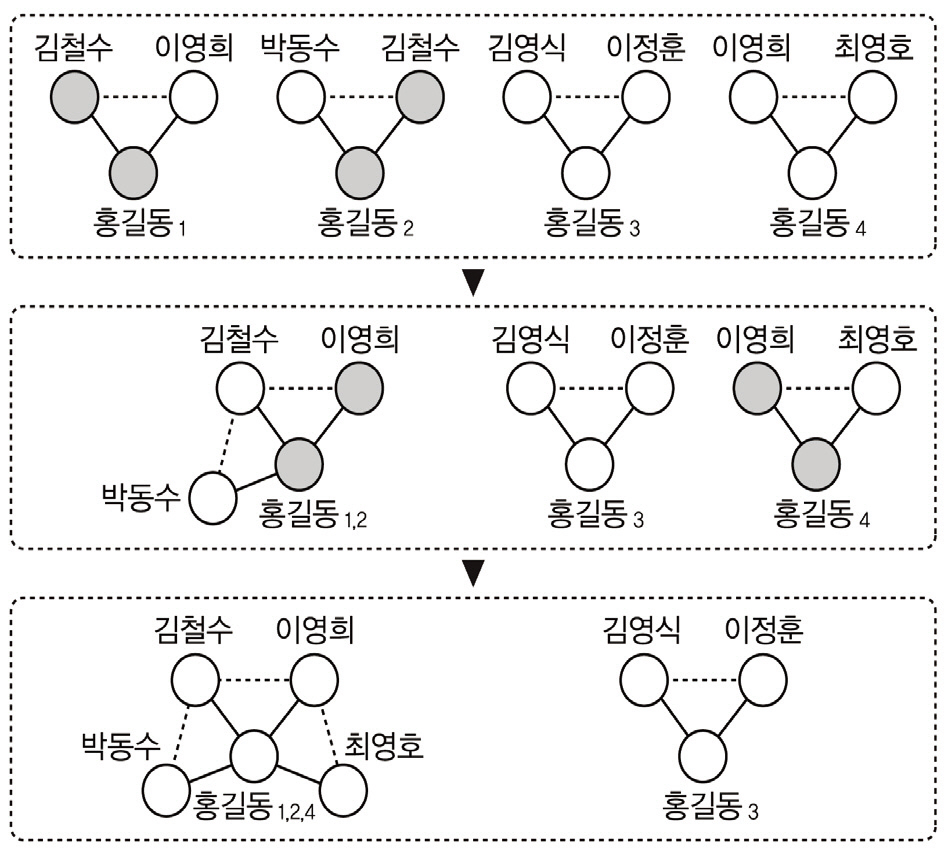
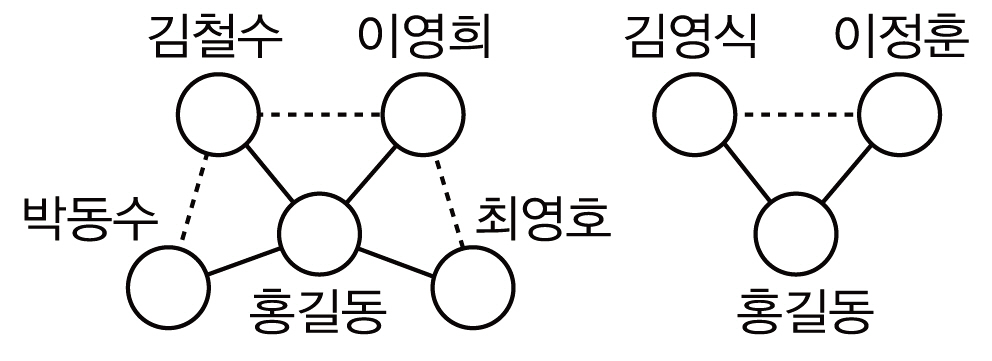
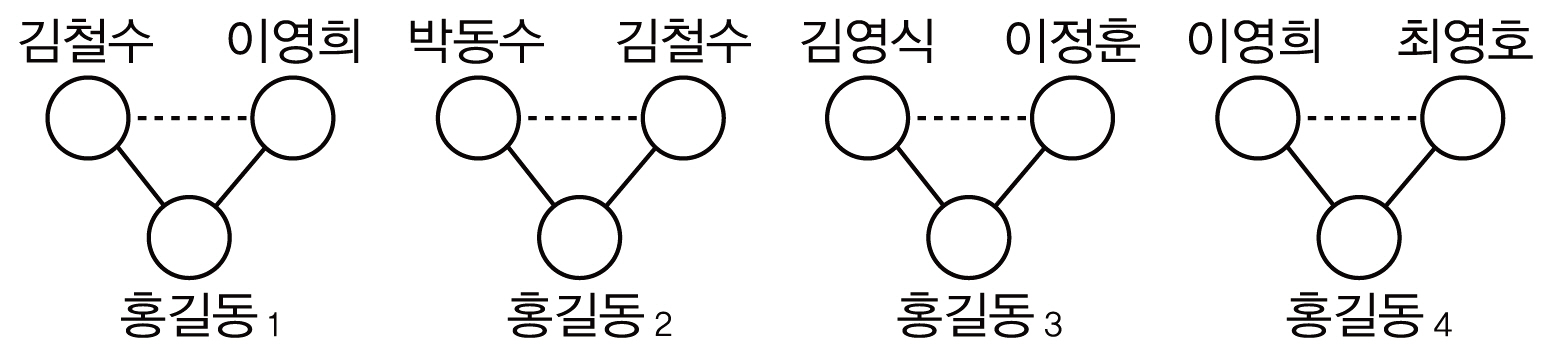
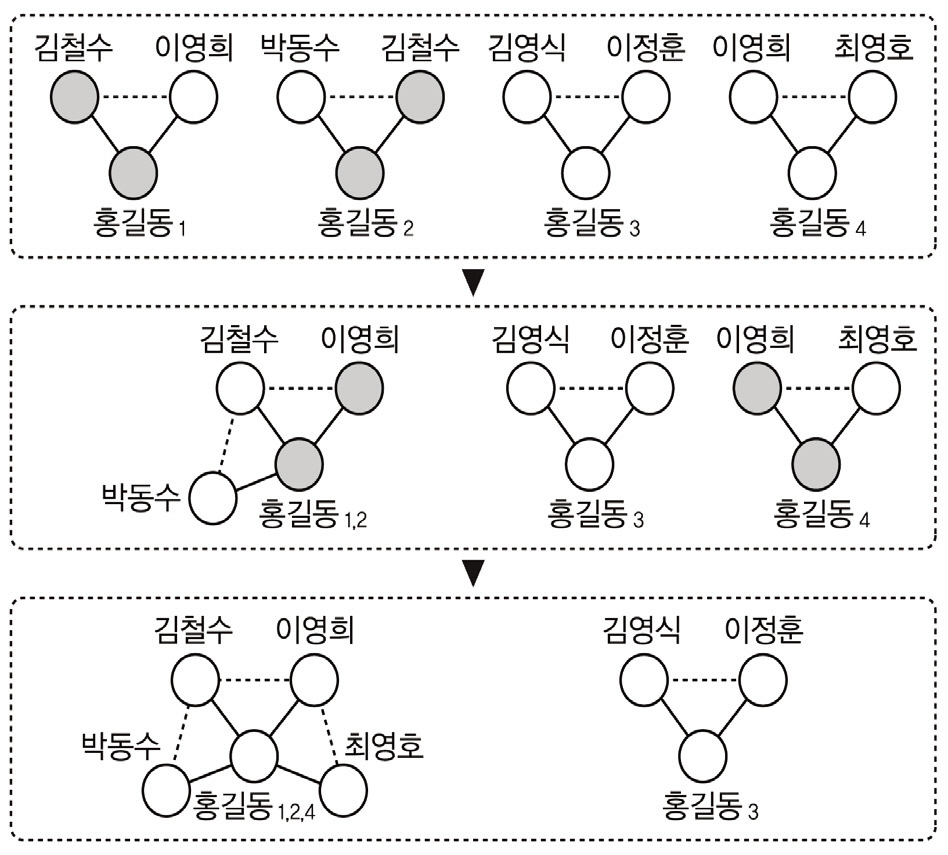
<그림 1>~<그림 3>은 서지레코드 R1~R6에 대해 저자명 그래프와 1인 및 2인의 공저자에 기반한 저자 노드 표현을 사용한 저자 그래프를 생성한 것이다. 1인 공저자 기반 저자노드 표현의 경우 최소 1인의 공저자가 요구되므로 R6이 대상에서 제외되고, 비슷한 이유로 2인 공저자 기반 저자 노드 표현의 경우 R3이 제외된다. <그림 2>, <그림 3>에서는 공저자 1인(2인)의 집합이 서로 다른 2개(4개) 저자명(홍길동)들을 각각 다른 사람으로 표현한 것이다. <그림 4>는 저자 표현의 제약을 공저자 2인에서 1인으로 완화시켜 나가는 과정을 보인 것이다. 즉 공저자 2인에 기반한 저자 그래프에서 {김철수, 이영희}에 의해 식별되는 홍길동1과 {박동수, 김철수}에 의해 식별되는 홍길동2는 공저자 1인에 기반한 저자 식별을 할 경우 동일한 공저자 {김철수}에 의해 식별되는 같은 사람으로 고려되어 홍길동1,2노드로 병합되고, 이후 홍길동1,2 노드와 홍길동4 노드들은 공저자 {이영희}에 의해 식별되는 같은 사람으로 고려되므로 홍길동1,2,4노드로 추가 병합이 발생한 것이다.
이 장에서는 1인 공저자 기반 저자 그래프생성 알고리즘(Algorithm-I) <표 1>을 제시한다. 알고리즘의 입력은 저자 그래프를 생성할 저자명 t이며 출력은 저자명 t에 대한 저자 그래프이다. 저자 그래프 G=(V, E)는 저자 노드(node, vertex)들의 집합 V와 저자 노드들 사이의 관계7)를 표현하는 링크(link, edge)들의 집합 E로 구성된다. 알고리즘은 저자 그래프를 생성할 대상이 되는 대용량 서지레코드 집합 S가 존재한다고 가정하고 있으며 sBR(t)는 S 내에서 저자명 t가 출현하면서 저자명의 수가 2인이상인 논문 서지레코드들의 집합(S의 부분집합)이다. 저자명 수 2인 이상의 논문으로 제한한 것은 1인 공저자 기반 저자 노드 표현을 위해 최소 1인의 공저자명이 필요하기 때문이다.
서지레코드 R1~R6에 대해 저자명 t=‘홍길동’을 입력으로 하여 위 알고리즘을 적용하면 다음과 같다. Line 3에서 sBR(홍길동)={R1,R2, R3, R4, R5}, Line 6에서 t(1)=‘홍길동1’로 두면 V={홍길동1}이 된다. sC1P는 최종적으로 t=‘홍길동’이 출현하면서 공저자 1인을 공유하는 논문들에 출현한 공저자들을 원소로 갖는 집합인데 Line 8~10에서rt=R1인경우 sC1P=sC1Pnew={김철수, 이영희}, sBR(홍길동)={R2, R3, R4, R5}이다. Line 11~22의 루프는 sC1Pnew의 각 공저자 c에 대
[표 1] Algorithm-I Author-Graph Generation

Algorithm-I Author-Graph Generation
c와 t가 동시에 출현한 논문들(즉, 공저자 c를공유하는 논문들) 내의 새로운 공저자들을 sC2P에 수집하여 sC1P에 추가하는 과정을 수행한다. Line 13, 14에서 c=‘김철수’인 경우 sBR(홍길동,김철수)={R2}, Line 16에서sC2P={박동수}, Line 18에서 sBR(홍길동)={R3, R4, R5}가 된다. 이후 반복되는 Line 13, 14에서 c=‘이영희’인 경우 sBR(홍길동,이영희)={R5}, Line 16에서 sC2P={박동수,최영호}, Line 18에서 sBR(홍길동)={R3, R4}가 된다. sC2P={박동수, 최영호}는 R1에 출현한 ‘홍길동’의 공저자 집합 sC1Pnew={김철수, 이영희}에 대해 이들 공저자를 공유하는 논문 R2, R5로부터 수집된 ‘홍길동’의 새로운 공저자들을 담고 있다. 따라서 Line 21에서는 sC1P={김철수, 이영희, 박동수, 최영희}가 되며 이는 t(1)=‘홍길동1’의 공저자들에 해당하므로 Line 24, 25에서 <그림 2>의 좌측과 같은 저자 그래프의 부분을 생성한다.
이후 sBR(홍길동)={R3, R4}이 공집합이아니므로 Line 4로부터 루프의 반복을 재개하여 Line 6에서 t(2)=‘홍길동2’로 두고 ‘홍길동2’의 공저자 집합을 수집한다. Line 8~10에서 rt=R3인 경우 sC1P=sC1Pnew={김영식}, sBR(홍길동)={R4}이다. Line 13, 14에서 c=‘김영식’인 경우 sBR(홍길동,김영식)={R4}, Line 16에서 sC2P={이정훈}, Line 18에서sBR(홍길동)={}가 된다. 이후 Line 21에서sC1P={김영식, 이정훈}이 되며 이는 t(2)=‘홍길동2’의 공저자들에 해당하므로 Line 24, 25에서 <그림 2>의 우측과 같은 저자 그래프의 부분을 생성한다.
<표 1> Algorithm-I은, 저자명 t를 포함하는 크기 n의 서지레코드집합 sBR(t)에 대해, sBR(t)가 공집합이 될 때까지 sBR(t)로부터 하나의 서지레코드 r을 O(1)의 시간 내에 제거하여, r로부터 O(1)의 시간 내에 저자 그래프 V에 추가할 저자 노드와 공저자 관계를 수집해 나가므로, 전체적으로 O(n)의 시간복잡도만을 요구한다. 이를 위한 sBR(t)={r1, r2, …, rn}의 색인구조로 Line 4의 WHILE 루프이전에 i번째 서지레코드 ri의 레코드번호를N(ri)이라 할 때,
7) 이 연구에서는 저자관계 중 공동저자 관계만을 고려한다.
제안된 저자 그래프 생성 알고리즘은 저자식별 관점에서 시간복잡도를 개선하는 시도이므로 저자식별의 성능에 대한 기존 연구와의 비교는 다루지 않았다. 다만 제안된 알고리즘의 식별 자질이 공저자임을 감안하여 기존 연구(강인수 등 2008; Kang et al. 2009)의 실험 결과를 참조할 때 저자식별의 성능은 한글의 경우 83%(F1지표) 이상일 것으로 추정할수 있다.
저자 그래프 생성 알고리즘의 동작을 평가하는 실험으로 선택된 한글논문집합을 대상으로 특정 저자명에 대한 저자 그래프를 생성하는 절차를 수행하였다. 이를 위해 DBPIA(www.dbpia.co.kr)에서 서비스되는 2000년 이후 출판된 한글 학술문헌들(저널/학술대회 논문, 연구보고서 등)을 대상으로 저자명 ‘이종혁’, ‘이근배’에 대한 저자 그래프를 생성하였다. 이저자명들은 본 논문의 저자가 활동하고 있는 연구 커뮤니티에 속한 대표적 연구자들의 이름들로, 이후 생성될 저자 그래프 평가의 편의를 위해 선택된 것이다. DBPIA의 저자명 검색 기능을 통해 2010년 7월 현재 저자명 ‘이종혁’, ‘이근배’가 포함된 각 146편, 78편의2000년 이후 출판논문들의 서지레코드를 검색하고, DBPIA의 서지반출 기능을 통해 Endnote형식으로다운로드한 다음, 아래 예와 같이 서지레코드번호, 공동저자명(들), 출판연도, 논문제목, 출판정보의 다섯 항목으로 구성된 서지레코드를 생성하였다.
위 서지레코드에 대해 t=‘이종혁’ 혹은 t=‘이근배’를 입력으로 저자 그래프 생성 알고리즘을 실행하였다. 알고리즘의 출력인 그래프를 2차원 화면에 표시하기 위해 사회망 비주얼화 도구 중 하나인 vizster8)를 사용하였다. Algorithm-I은 Perl로 구현하였으며 알고리즘의 출력 그래프 형식을 vizster의 입력 그래프 형식의 파일로 변환하는 모듈을 포함하고있다.
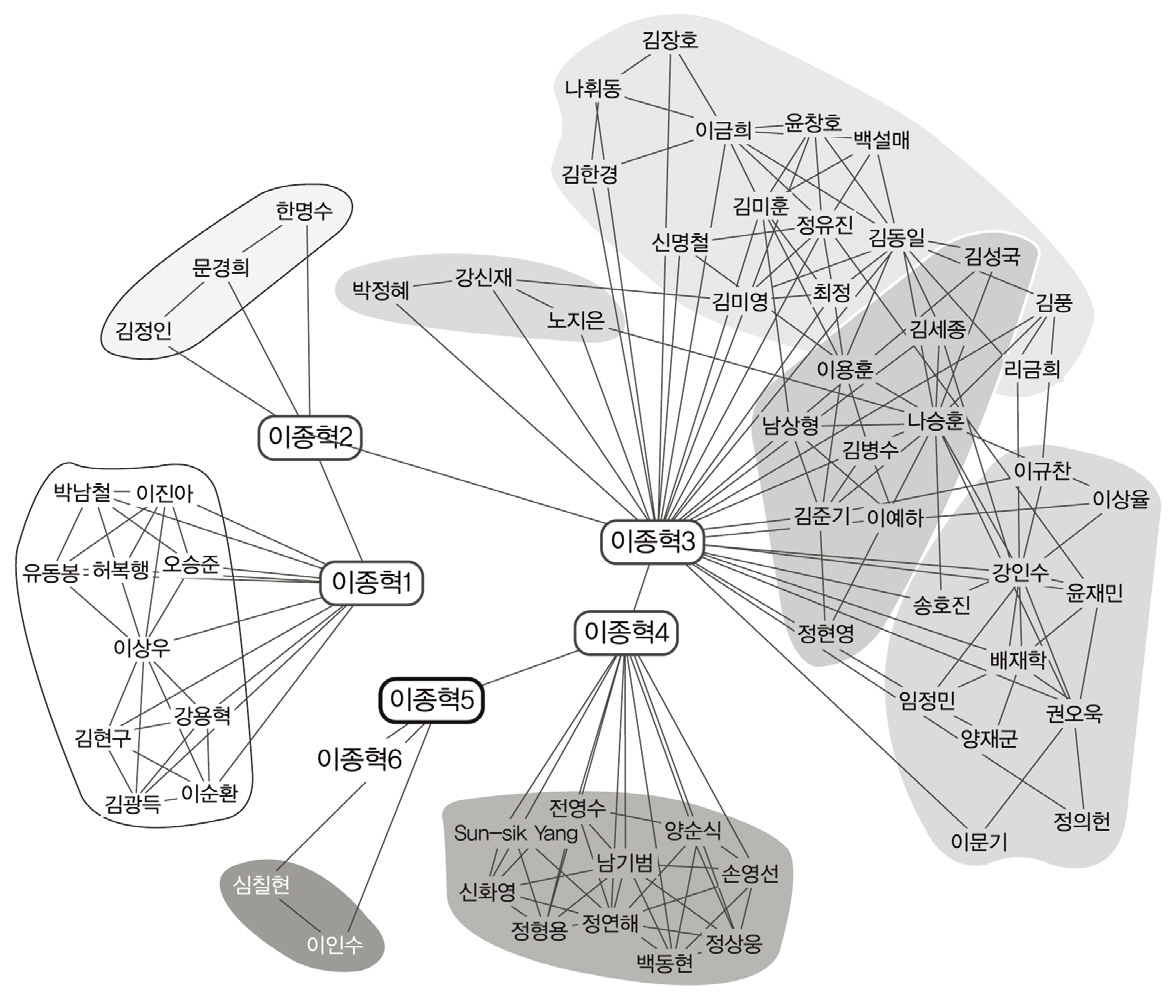
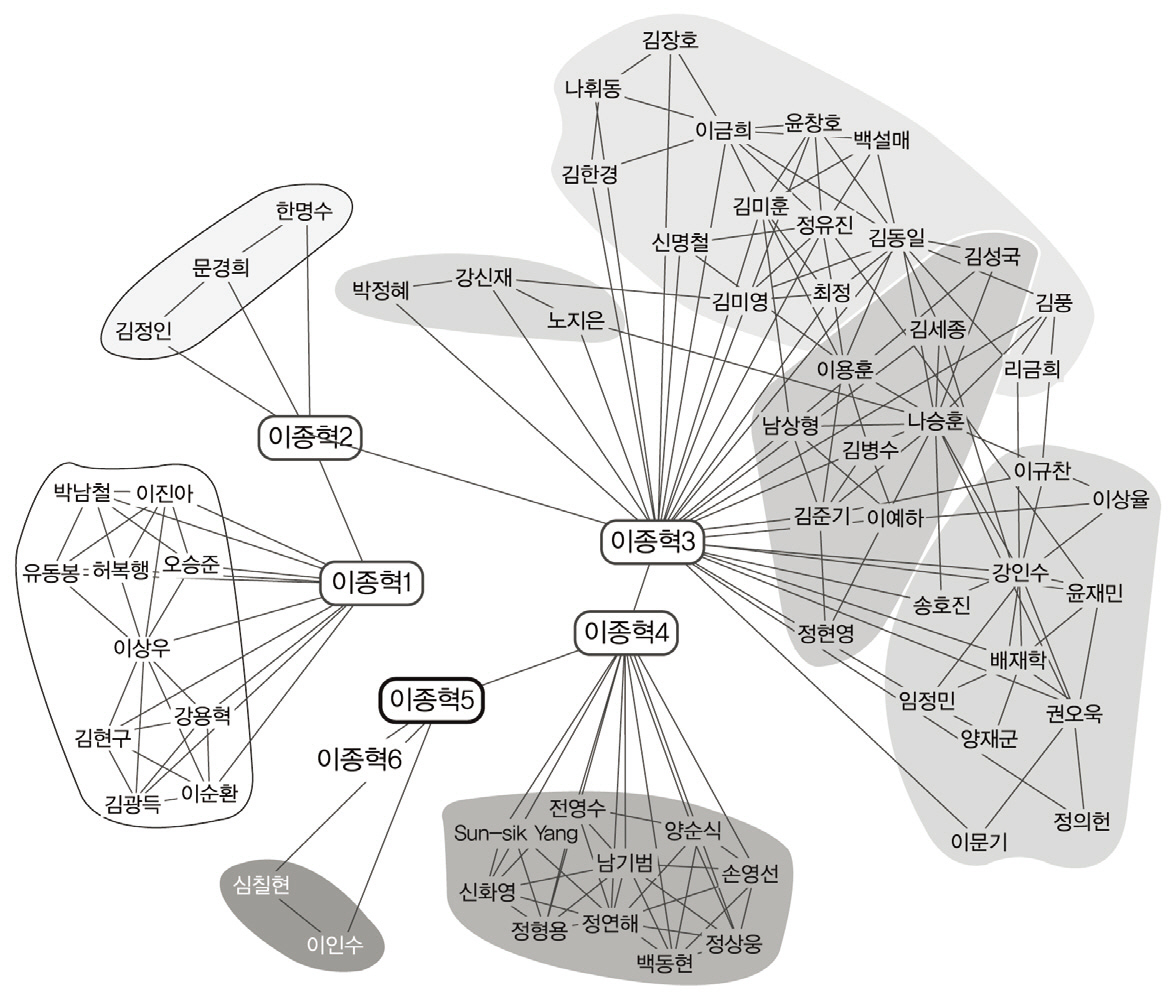
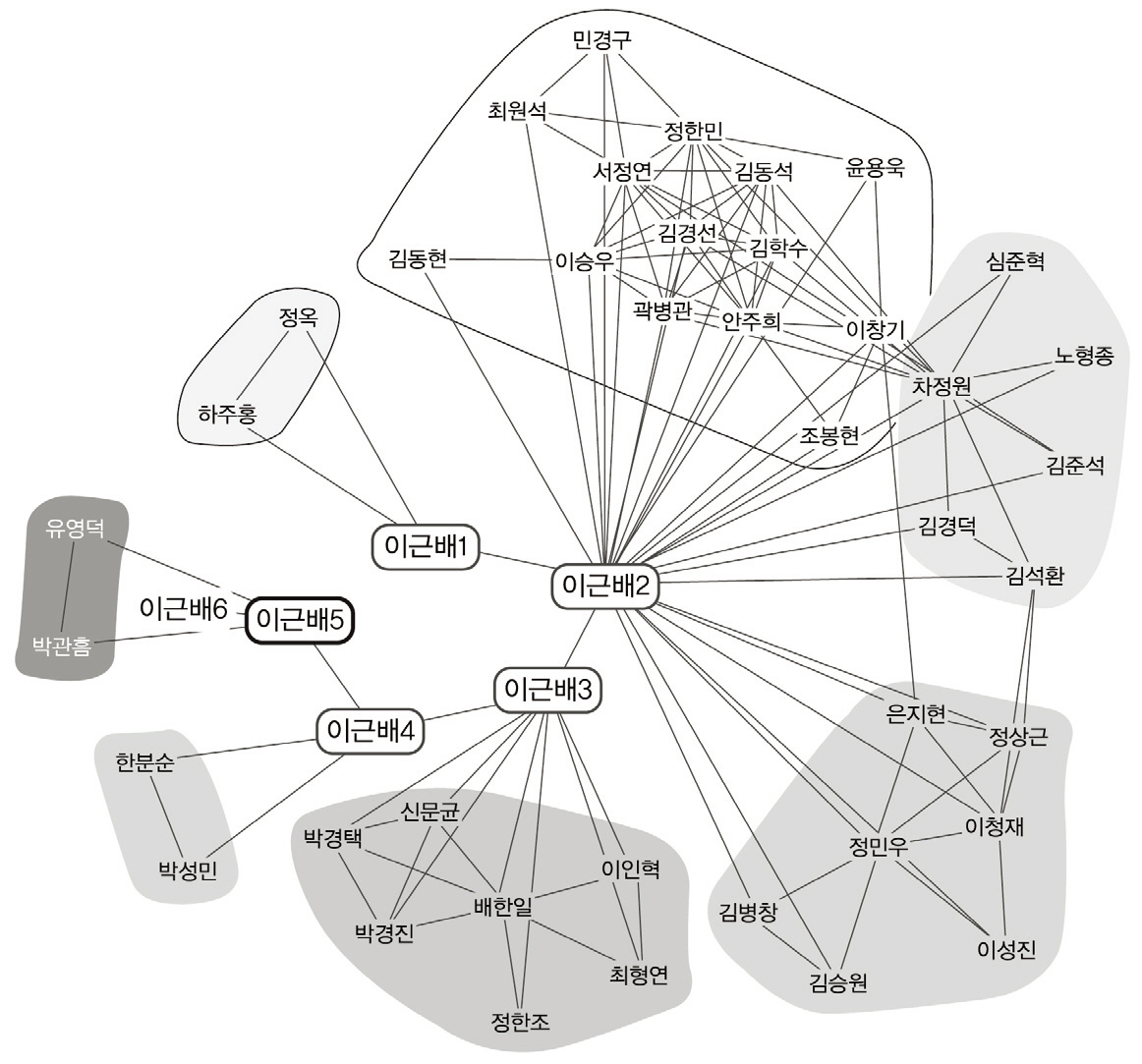
알고리즘의 수행 결과, 저자명 ‘이종혁’, ‘이근배’에 대해 각각 총 36명, 15명의 동명저자가 발견되었고, <그림 5>, <그림 6>에 vizster를 통해 얻어진 저자 그래프를 표시하였다. 또한 <그림 5>, <그림 6>에서는 지면 크기 제약과 독자들의 저자 노드 확인의 편의를 위해 저자명 ‘이종혁’, ‘이근배’의 동명저자들 중 5명까지의 저자 그래프 부분들만 표시하였다. 그림에서 노드 사이의 링크는 공동저자 관계를 나타낸다. <그림 5>, <그림 6>에서 동명 저자노드들 사이의 링크(예: 이종혁1, 이종혁2 사이의 연결선)는 공동저자 관계가 아니며, vizster툴 내에서 비연결 그래프(disconnected graph)를 표시하는 어려움을 피하면서 다수의 비연결형 동명 저자 그래프들을 한 화면에 동시에 표시하기 위해 인위적으로 추가한 연결선이다.
<그림 5>에서 저자 노드 ‘이종혁1’과 그 공저자들은 한국기상학회, 한국대기환경학회 학술대회에 논문을 실은 저자들에 해당한다. 저자 노드 ‘이종혁2’, ‘이종혁3’은 모두 POSTECH 컴퓨터공학과 이종혁 교수에 해당하며 연결된 공저자들은 모두 이종혁 교수와 자연어처리 분야의 공동연구를 수행한 연구자들이다. 저자 노드 ‘이종혁4’와 그 공저자들은 대한전기학회 학술대회에 논문을 출판한 저자들에 해당한다. 저자 노드 ‘이종혁5’와 그 공저자들은 한국정보기술학회논문지에 논문을 실은 저자들이다. <그림 5>의 ‘이종혁2’, ‘이종혁3’처럼 실 세계 동일인이 서로 다른 저자 노드로 표현된 것은 현재 실험에 사용된 DBPIA로부터의 146편 한글 논문집합 내에 ‘이종혁
2’, ‘이종혁3’의 공저자 그룹들 사이의 공동연구 기록이 발견되지 않았기 때문이다. DBPIA에서 검색되는 2000년 이후 논문이라는 제약을 제거하여 보다 큰 서지레코드에 대해 저자그래프를 생성할 경우 아래 논문의 공저자 관계를 통해 ‘이종혁2’, ‘이종혁3’은 하나의 저자 노드로 병합되었을 것이다.
허남원, 정유진, 문경희, 이종혁.(1998). 한일양국어 연결어미 비교연구.....
그러나 서지레코드의 전체 집합을 대상으로 하더라도 <표 1> Algorithm-I이 실 세계의 동일인에 대해 항상 하나의 저자 노드를 생성하는 것은 아니다. 그것은 한 사람의 여러 공저자 그룹들이 서로 간에 공동 연구를 수행하지 않을 수 있기 때문이다.
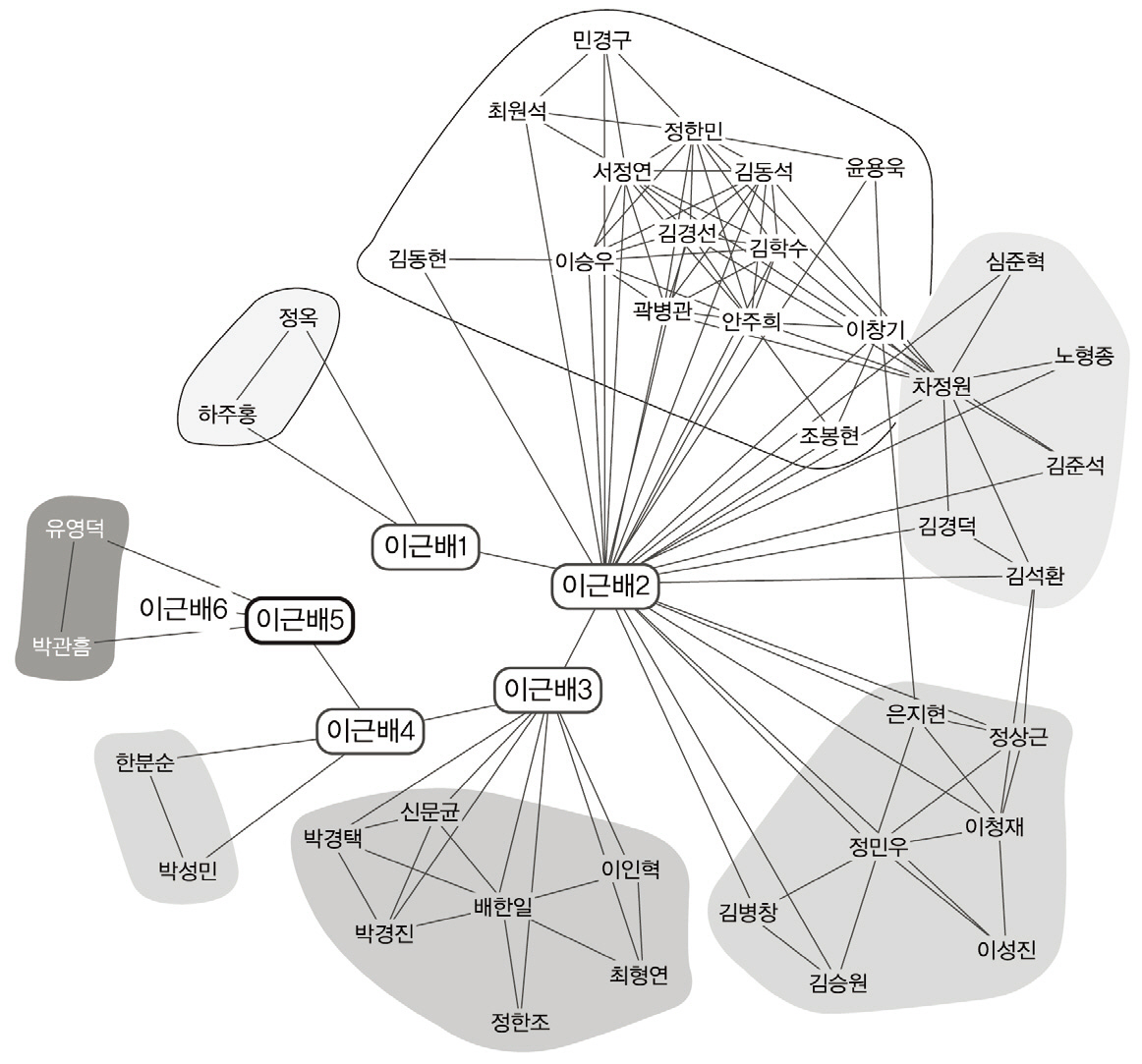
<그림 6>의 경우 저자 노드 ‘이근배1’, ‘이근배2’는 POSTECH 컴퓨터공학과 이근배 교수에 해당하며 연결된 공저자들은 모두 이근배 교수와 자연어처리 분야의 공동연구를 수행한 연구자들이다. 저자 노드 ‘이근배3’과 그 공저자들은 한국자동차공학회 학술대회에 논문을 출판한 저자들에 해당한다. 저자 노드‘이근배4’와 그 공저자들은 2009년 서울신문신춘문예 시조시학의 공저자들이다. 저자 노드 ‘이근배5’와 그 공저자들은 한국자동차공학회 학술대회 논문을 실은 저자들로 ‘이근배3’과 동일인일 가능성이 높으나 DBPIA로부터의 78편 서지레코드 내에서는 공유되는 공저자가 발견되지 않아 분리된 저자 노드로 존재한다.
<표 1> Algorithm-I을 통해 생성된 <그림5>, <그림 6>은 ‘이종혁’, ‘이근배’의 협업 연구자들을 ‘이종혁’, ‘이근배’의 추측되는 동명이인 각각에 대해 분리하여 제시하고 있다. 만약 Algorithm-I을 적용하지 않았다면 <그림5>, <그림 6>은 각각 하나의 저자명 노드에 연결된 단일 공저자망이 되었을 것이다. 저자 그래프 생성은 저자식별의 저자명 군집화(clustering)에 해당한다. 부정확한 군집화의 원인을 과소군집오류와 과다군집오류로 분류할때9), Algorithm-I은 과소군집오류의 발생을 희생하면서 과다군집오류를 최소화하는 접근을 취하고 있다. <표 1> Algorithm-I에서 과다군집오류가 발생하는 유일한 경우는 공유공저자가 동명이인일 때이나 그 발생은 드문사건에 해당한다.
8) http://hci.stanford.edu/jheer/projects/vizster/ 9) 과소군집오류(under-clustering error)는 같은 군집에 속하는 개체들을 서로 다른 군집으로 생성하는 것이며 과다군집오류(over-clustering error)는 서로 다른 군집에 속하는 개체를 같은 군집으로 묶는 것이다.
저자에 대한 현재의 학술정보서비스에서는 동일 저자명을 갖는 모든 저자들(혹은 그들의 논문들)을 하나의 군집으로 묶어 사용자에게 제시함으로 인해 저자식별의 부담을 사용자에게 전가시키고 있다. 이 문제를 다루기 위해 제안된 기존의 저자식별 기법들은 과소/과다군집오류 및 시간복잡도 측면에서 실질적 적용의 어려움을 다소간 포함하고 있다. 이 연구에서는 추가적 정보 획득의 부담 없이 서지레코드에 출현하는 공저자 자질을 사용함으로써 과다군집오류를 최소화시키면서 선형시간 내에 저자식별을 수행하는 알고리즘을 제시하였다.
제안된 기법은 저자 식별을 위해 공저자만을 사용하므로 한 연구자의 공동 연구자들이 실제 그렇지 않음에도 불구하고 저자 그래프내에서 분리되어 표시되는 한계를 안고 있다. 이는 저자 그래프 생성을 위한 입력 서지레코드 집합 내에 특정 연구자의 모든 서지정보가 포함되어 있지 않은 경우에 해당한다. 그러나 전술한 한계는 한 연구자가 시간의 차를 두고 수행한 서로 다른 연구에 참여한 연구자들을 분리하여 표시해야 하는 경우 유용한 기능으로 쓰일 수도 있을 것이다. 한편 현재 제시된 방법에서는 단독저자 논문의 저자는 저자 그래프 생성에서 배제하였다. 이들을 저자 그래프 생성에 포함할 경우 과소군집오류가 증가하게 된다. 이 문제는 향후 논문 원문 내의 소속, 전자메일, 참고문헌이나 웹 상의 저자 홈페이지 내 출판문헌 리스트를 통한 저자식별을 통해 일부 해결될 수 있으나 역으로 과다군집오류가 증가될 수 있다. 따라서 제안된 기법및 그 변형은 과소/과다군집오류 통제에 대한 원칙을 미리 설정하고 학술정보서비스에 활용되어야 할 것이다.
본 논문의 방법은 실험에 예시된 것처럼 사용자가 입력한 특정 저자명에 대한 협업 연구자망을, 예측된 실 세계 저자별로 분리하여, 그래프 형식으로 제시하는 응용에 유용하게 활용될 수 있을 것이다. 또한 저자명 노드 표현에 기반한 기존 저자망에 저자식별을 적용할 경우 동일한 실 세계 저자들이 단일 노드로 병합된 오류를 해소함으로써 보다 정확한 사회망 특성 분석이 가능해질 것이다. 사회망에서의 커뮤니티 인식 기법과 저자식별 결과는 관련성이 있다. 향후 이의 상관 관계를 고찰하고 각 분야 기법들을 교차 적용하는 연구가 수행될 필요가 있다.