정보기술과 인터넷의 발달로 학술정보가 폭발적으로 증가하고 있다. 정보 과잉으로 인해 연구자들은 필요한 정보를 찾거나 필터링하는데 더 많은 시간과 노력을 투입하고 있다. 이용자들이 원하는 정보를 예측하여 관심 가질만한 정보를 선별하여 추천하는 시스템을 전문가시스템, 데이터마이닝, 정보검색 등 다양한 분야에서 오래 전부터 연구하여 왔다. 최근에는 콘텐츠기반추천시스템과 협업필터링을 결합하거나 다른 분야 모델을 접목한 하이브리드 추천시스템으로 발전하고 있다. 본 연구에서는 기존 추천시스템 문제를 해결하고 대규모 정보센터나 도서관에서 학술논문을 효율적이고 지능적으로 추천하기 위해 협업필터링과 나이브베이즈모델을 결합한 새로운 방식의 추천시스템을 제시하였다. 즉, 협업필터링 방식으로 과도한 특성화(Over-specialization) 문제를 해결하고, 나이브베이즈모델을 통해 평가정보나 이용정보가 부족한 신규콘텐츠 추천문제를 해소하였다. 본 모델을 검증하기 위해 한국과학기술정보연구원 NDSL에서 제공하는 식품과 전기 분야 학술논문에 적용하여 실험하였다. 현재 NDSL이용자 4명에게 피드백을 받은 결과 추천논문에 상당히 만족하는 것으로 나타났다.
다양한 저작도구(authoring tool)의 발달과 인터넷 확산에 따른 정보과잉(information overflow)으로 인해 연구자들은 원하는 정보를 찾기 위해 점점 더 많은 시간을 소비하고노력을 기울이고 있다. 특히 대규모 학술정보를 서비스하는 정보센터나 도서관에서는 이런현상이 더욱 심하다. 정보검색 분야에서는 오래전부터 키워드 출현빈도에 기반 한 적합문서 선별 및 랭킹, 이용로그 및 이용 상황에 근간한 정보 필터링, 검색결과 클러스터링 및 분석, 페이지 랭크 등 다양한 연구를 통해 이런문제에 대응해 왔다. 정보센터나 도서관에서도 검색 질문식이나 즐겨 찾는 저널을 등록한후 새로운 정보가 입수되면 자동으로 관련 정보를 제공하는 SDI(Selective Dissemination of Information) 서비스를 제공하고 있다. 하지만 SDI의 경우 등록 및 갱신절차가 번거롭고 정보량에 비례하여 불필요한 정보가 많이포함됨으로써 만족도가 떨어지고 있다. 연구자들은 연구 시 정보를 찾는데 많은 시간을 투입하고 있으며, 연구자들이 관심 가질 만한 학술논문을 지능적으로 선별하여 추천하면, 연구자들이 정보를 찾는데 드는 노력을 절감하고 만족도도 제고할 수 있다.
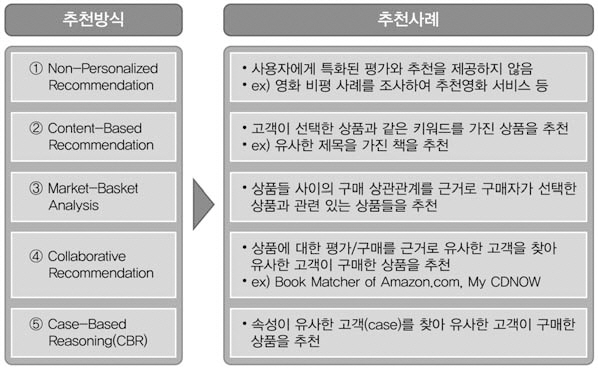
최근 고객들이 원하는 정보를 필터링하여제공하는 개인화서비스와 이용자들이 선호할만한 정보를 예측하여 제공하는 추천시스템에대한 연구가 활발하다. 콘텐츠 부문의 추천시스템은 이용자 프로파일, 이용로그, 관심사항,콘텐츠 유사도 등을 토대로 적합문서를 지능적으로 추천하는 시스템이다. 추천방식으로는콘텐츠 유사도에 근간한 콘텐츠기반추천시스템과 같은 분야를 연구하는 동료 연구자들이 이용한 정보를 토대로 추천하는 협업필터링이있으며, 최근 이들을 결합한 새로운 방식의 하이브리드 추천모델이 등장하고 있다.
본 연구에서는 기존 추천시스템 문제점을해결하고 대규모 정보센터나 도서관에서 학술논문을 효율적, 지능적으로 추천하기 위해 협업필터링과 나이브베이즈모델을 결합한 새로운 방식의 추천시스템을 제시하였다. 기존 추천시스템들의 경우 평가정보나 이용정보 부족, 과도한 특성화(Over-specialization) 문제, 비효율성 등 여러 가지 문제가 있다. 본연구에서는 협업필터링 방식을 통해 과도한특성화 문제를 개선하였으며, 나이브베이즈모델을 결합하여 이용로그 등이 축적될 때까지 기다려야하는 문제를 해결하였다. 특히, 협업필터링을 통해 문서학습 및 자질선정을 자동화함으로써 연구자들이 별도로 프로파일을 갱신하거나 관리할 필요가 없도록 하였다.
본 모델을 검증하기 위해 한국과학기술정보 연구원 NDSL 학술논문을 대상으로 실험모형을 개발한 후 추천품질을 검증하였다. 실험대상은 최근 3년간 NDSL 이용로그를 토대로 이용 빈도가 높은 학술논문 약 3천 5백 건을 추출하고 이를 많이 이용한 식품과 전기 분야 연구자 상위 5명을 선정하여 추천논문에 대한 품질을 조사하였다. 이들에게 본 모델을 통해추천한 논문을 이메일로 발송한 후 5점 척도로 만족도를 조사한 결과 대체로 만족하는 것으로 나타났다.
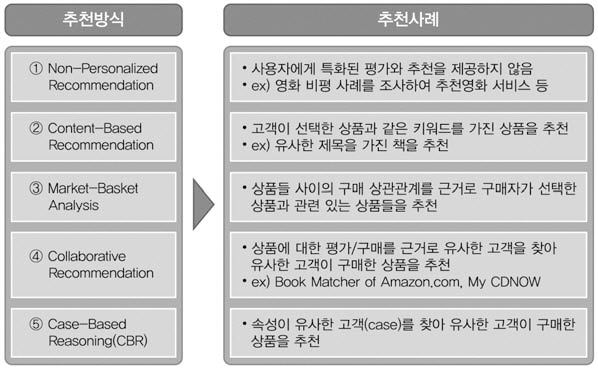
학술논문 등을 지능적으로 추천하기 위해 콘텐츠기반추천시스템(Content-Based Recommendation)과 협업필터링(Collaborative Filtering)방식이 동시에 발전하여 왔으나, 현재는 후자에 관한 연구에 집중하고 있다. 추천시스템은 어떤 이용자와 특정 아이템이 주어졌을때, 이 아이템에 대한 이용자의 선호도(preference)를 예측(prediction)하여 예상 선호도가 높은 아이템을 추천(recommendation)하거나(안신현 2007), 정보를 필터링(Informa-
tion Filtering)하여 이용자가 흥미를 가질 만한 정보 아이템을 제공하는 시스템이다(한성희 2009).
추천방식은 <그림 1>과 같이 다양하며 대부분 콘텐츠나 사람 간 유사도에 기반하여 추천한다. 대표적인 추천시스템은 Amazon.com의 북매처(BookMatcher)다. 아마존닷컴에서는 개인별 특성이나 성향이 비슷한 이용자 집단을 분석하여 추천하는 방법 대신 상품 대 상품(Item-to-Item)에 기반한 추천방식을 사용하고 있다.
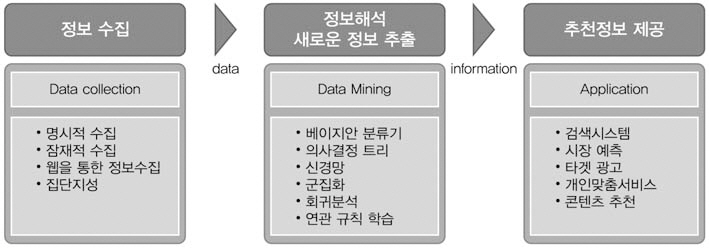
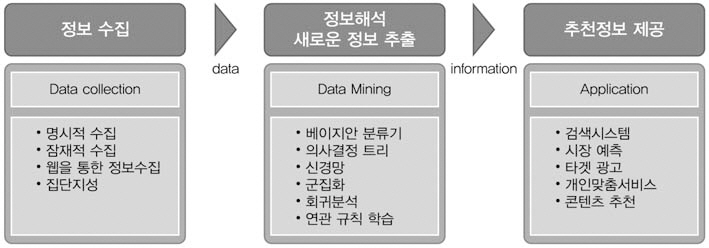
추천프로세스는 <그림 2>와 같이 정보를수집하여 다양한 모델을 이용해 연관성을 분석하고 가장 적합한 문서를 계산 및 선별하여추천한다. 추천정보는 검색시스템, 개인맞춤서비스, 타겟광고, 시장예측 등 다양한 분야에 활용된다.
가질만한 정보를 선별하여 추천하는 시스템을전문가시스템, 데이터마이닝, 정보검색 등 여러 분야에서 오래전부터 연구해 왔다. 특히,정보검색의 경우 이용자 질의에 가장 적합한문서를 상위에 추천하기 위해 키워드 출현빈도에 따라 가중치를 부여하거나 개인프로파일이나 이용로그를 토대로 검색결과를 필터링하고 있다.
최근 연구가 활발한 협업필터링 방식의 경우 성향이 비슷한 이용자들이 선호하는 정보를 추천하는 시스템으로 과도한 특성화(Over-specialization) 문제도 없고 추천 성능도우수하다. 하지만 대다수 학술논문 서비스 사이트의 경우 콘텐츠를 평가하는 기능이 없으며 설사 기능이 있더라도 이용자들이 평가에소극적이기 때문에 정보 희소성 문제에 봉착하게 된다. 게다가 신규 콘텐츠의 경우 일정한시간이 경과되기 전까진 평가정보와 이용내역이 없어 추천할 수 없는 맹점이 있다. 이는 학술논문과 같이 시급성과 적시성이 중요한 부문에서는 이슈가 된다. 한편 콘텐츠기반추천 시스템은 문서 유사도에 기반하기 때문에 과도한 특성화 문제가 발생하며, 시간에 따라 바뀌는 이용자들의 관심사항을 적시에 반영할수 없는 한계가 있다.
본 연구에서는 이와 같은 문제를 해결하고대규모 정보센터나 도서관에서 지능적으로 학술논문을 추천할 수 있도록 상호 보완적인 모델을 결합하여 이를 해결하였다. 즉, 과도한특성화 문제와 시시각각 바뀌는 이용자들의관심사항을 자동으로 갱신할 수 있는 협업필터링모델에 신규 콘텐츠를 효율적으로 추천할수 있도록 나이브베이즈모델을 접목하였다.
문서분류 방식에는 나이브베이즈모델 뿐만아니라 다양한 모델이 있지만 Support Vector Machine(SVM)의 경우 두 개의 카테고리로 문서를 분류하는데 최적인 모델이므로 학술논문 추천시스템과 같이 다수의 이용자에게분류하는 본 연구에는 적합하지 않다고 판단되어 제외하였으며, K-Nearest Neighbor(K-NN)의 경우 K 변수 선정문제로 고려하지않았다.
추천시스템은 고객이 관심을 가지는 상품에 관한 정보나 인구통계학적 정보, 과거 구매한행동분석을 토대로 고객의 요구에 맞는 상품을 추천해 주는 시스템이다(Sarwar 2001).또한 고객들이 구매하고자 하는 상품을 쉽게찾을 수 있도록 도와주는 정보필터링 기술이다(Schafer 1999). 추천시스템은 인터넷을기반으로 고객별 일대일 마케팅을 가능하게하는 e-CRM의 한 분야로서 Amazon, CDnow등 해외 유수 전자상거래 사이트에서 활용되고 있으며, Ringo 음악추천이나 Bellcore비디오 추천 등에 이용되고 있다.
Sarwar(2001)는 데이터 희박성(sparsity)과 규모의 문제를 지닌 이용자기반 협업필터링을 보완하기 위해 아이템기반 협업필터링 추천알고리즘을 제시하였다. 또한, 박지선(2002)은 아이템기반 협업필터링의 문제점을 보완하고자 유사 고객군을 찾은 다음 그들이 평가한상품 간 유사도를 계산해서 추천하는 2-way협업필터링을 제시하였다. 아울러 Kim(2002)은 K-means 클러스터링 기법을 추천알고리즘에 적용하였고, Li and Kim(2003)은 클러스터링기법을 아이템기반 협업필터링에 응용하였다. 이외에도 Roh(2003)의 연구에서는 클러스터링을 위하여 SOM을 사용하고 유사도를 찾기 위하여 최근접이웃법을 이용하여 기존의 협업필터링방식과 비교분석하여 예측 성능의 우수함을 설명하였다. 아울러 김재경(2003)은전자상거래 쇼핑몰에 웹데이터마이닝과 클러스터링에 기반한 협업필터링 방안을 제시하였다. Weng(2004)은 고객이 새로운 제품을 아직 구매하지 않았기 때문에 기존의 장바구니분석과 협업필터링 분석을 통해서는 새로운제품을 추천할 수 없다고 보고 제품의 특징에기반한 추천을 제안하였다. 끝으로 이충무(2009)는 같은 논문을 열람한 이용자를 유사한 분야를 연구하는 동료연구자로 간주하고이들이 이용한 논문을 상호추천하고 정보를공유하는 온라인 지식네트워크인 연구자연결망을 연구하였다.
가. 콘텐츠기반추천시스템
콘텐츠기반추천시스템(Content-Based Recommendation)은 정보검색기술에 바탕을둔 시스템으로, 아이템의 콘텐츠를 직접 분석하여 아이템과 아이템, 아이템과 이용자 선호도간 유사성을 분석하여, 이를 토대로 새로운 아이템을 추천해주는 시스템이다(안신현 2007).본 방식은 분석의 용이함 때문에 주로 텍스트 기반의 뉴스나 인터넷 기사, 책 등을 추천하는 시스템에서 많이 사용하였으며(Krulwich 1995),아이템의 메타데이터를 통해서도 내용을 분석할 수 있기 때문에 영화, 음악, 도서 등 다양한 문화 콘텐츠 추천시스템에서도 사용했다.이용자 선호도에 관계없이 특정 아이템에 대한 유사 아이템 리스트를 제공하는 서비스가 가능한데, 음악 사이트에서 제공하는 유사 앨범이나 유사 아티스트가 여기에 해당한다.
Baumann(2005)은 2005년 아티스트에 관한 리뷰를 웹검색을 통해 수집하여 벡터 간 유사성 계산법으로 유사 아티스트를 찾아내는연구를 하였다. 하지만 이용자의 취향은 개개인에 따라 다르기 때문에 특정 이용자에게 개인화된(Personalized) 추천리스트를 제공하기위해, 이용자 선호도 프로파일(User Preference Profile)을 사용하였다. 즉, 이용자의 선호도를 각 아이템의 내용과 비교하여 선호도가 높을 것으로 예상되는 아이템을 추천하는 것이다. 이용자 선호도 프로파일은 주로 이용자가과거에 이용했던 아이템에서 추출한다. 예를들어 과거에 구매했던 도서나 영화, 음악, 읽었던 기사 또는 방문했던 URL 등이 이용자프로파일이 되기도 하고, 직접적으로 특정 아이템에 대한 이용자 평가를 물어보기도 한다.
콘텐츠기반추천시스템은 이해하기 쉽고 계산과정이 간단한 반면 여러 가지 단점이 있다.먼저, 다룰 수 있는 분야가 대부분 텍스트로그 범위가 매우 한정적이다. 즉, 영화, 음악,레스토랑과 같은 아이템에 포함된 영상, 음향,맛 등은 적용하기 어렵다. 인터넷 텍스트 문서도 내용 파악은 가능하나, 웹페이지의 미적 감각이나 멀티미디어 정보, 로딩시간 등은 파악하기 어렵다. 둘째, 추천 아이템이 지나치게특성화되기 싶다. 이용자 선호도와 유사한 아이템만 찾다 보면, 과거에 접했던 아이템과 다른 새로운 아이템을 접할 기회가 없게 된다(Balabanovic 1997). 이러한 문제를 해결하기 위해 추천에서 무작위 요소를 추가하거나돌연변이 방식을 사용하기도 한다(Sheth, B.1993). 셋째, 이용자 선호도 프로파일이 있어야 아이템을 추천할 수 있는데, 이용자 프로파일을 구축하기 위해서는 아이템에 대한 이용자의 평점(ratings)을 수집해야 한다. 이를 위해 이용자 참여를 유도하는 것이 쉽지 않다.이는 비단 콘텐츠기반추천시스템뿐만 아니라이용자 평점을 필요로 하는 대부분의 추천시스템에서 공통적으로 겪는 문제다.
나. 협업필터링
협업필터링(Collaborative Filtering)은 Collaborative Recommendation, Social Filtering등 여러 가지 명칭으로 불리며, 한 이용자의 취향과 유사한 다른 이용자의 취향을취합하여 아이템에 대한 선호도를 예측하는시스템이다. 협업필터링은 사람들의 취향은무작위로 분포하는 것이 아니라 일반적인 경향과 패턴이 있다는 가정에서 시작한다. 실제로 사람들은 주위 친구들이나 인터넷을 통해다른 이용자들과 커뮤니케이션하고 이를 통해아이템을 추천 받기도 한다. 협업필터링은 이러한 "입소문"(Shardanand 1995)의 개념을자동화 한 것이라 할 수 있으며 일반적인 절차는 다음과 같다. ① 이용자는 이전에 구매하거나 경험했던 아이템에 대해 평점(rating)을 매기고 이를 통해 이용자 프로파일을 구성한다.② 같은 아이템에 대해 평점을 내린 이용자들의 프로파일을 비교하여 유사도에 따라 가중치를 매긴다. 이중 취향이 비슷한 이용자 그룹을 Nearest-Neighborhood라 한다. ③ 마지막으로 어떤 새로운 아이템에 대한 이용자 예상 선호도를 그 아이템을 이미 경험한 Nearest-Neighborhood의 기존 평가를 토대로예측한다. 협업필터링의 초기 연구 중 하나인Ringo(Shardanand 1995)는 위의 절차를 통해 아티스트에 대한 이용자 평가를 비교하여새로운 아티스트들을 추천했다.
협업필터링은 콘텐츠기반추천시스템이 갖고있는 문제점을 해결해준다. 먼저, 자동으로 분석하기 어려웠던 아이템의 속성들 즉, 영상,음향, 아이디어, 감정 같은 것을 이용자 평점으로 계산할 수 있기 때문에, 콘텐츠기반추천시스템이 다루지 못했던 아이템 추천이 가능하다. 또한 이용자의 취향이나 아이템의 질에기반한 추천이 가능하다. 그리고 다른 이용자의 경험을 바탕으로 하기 때문에 평소 선호했던 아이템과는 다르지만, 높이 평가할 수 있는아이템에 대한 추천도 가능하다. 그러나 협업필터링도 몇 가지 한계점을 가지고 있다. 먼저새로운 아이템이 추가되었을 때, 이에 대한 이용자 평점이 쌓이기 전에는 이 아이템을 추천할 수 없다. 아울러 아이템 수에 비해 이용자수가 적을 경우 평점이 존재하지 않는 아이템이 많을 수 있으며, 게다가 이용자가 적으면공통된 아이템에 대해 평점을 내린 이용자가작기 때문에 Nearest-Neighborhood를 찾기어렵다. 특히, 독특한 취향을 가진 이용자의경우, 유사 취향의 이용자가 드물다면 이 이용자에게 좋은 추천 서비스를 할 수 없다(안신현2007). 하지만 협업필터링은 추천시스템 분야에서 가장 성공적인 기법으로 전자상거래 기업에서 가장 널리 이용되고 있다(Konstan 1997).
다. Hybrid Recommendation
콘텐츠기반추천시스템과 협업필터링은 서로상반되는 개념이 아니라 오히려 서로의 단점을 보완함으로써 추천시스템의 성능을 높일수 있다. Balabanovic(1997)은 웹페이지 추천시스템으로 콘텐츠기반추천시스템과 협업필터링을 접목하여 이용자마다 프로파일을 구축하고 프로파일과 비슷한 아이템을 추천하거나이웃 이용자가 높게 평가한 아이템을 추천하는 모델을 제시하였다. 콘텐츠기반추천시스템의 특성 때문에 아직 어떤 이용자도 평가하지않은 아이템을 추천하는 것이 가능하고, 협업필터링의 특성으로 새로운 아이템을 접할 수있는 기회를 제공할 수 있다.
문서분류란 많은 양의 서로 다른 문서들을미리 정의된 여러 가지 카테고리 중 하나에 속하도록 분류하는 것을 말한다. 문서분류 과정은 기존에 분류된 다양한 카테고리에 문서들을 학습시킨 다음 그 학습정보를 기반으로 아직 분류되지 않은 입력문서를 분류한다. 이러한 문서분류의 과정에서 필수적인 과정이 문서를 수치로 표현하는 것이다. 일반적으로 문서 수치화는 문서에 포함된 단어를 기준으로하며, 단어 출현빈도를 기반으로 벡터를 만들어 문서를 분류한다. 학습기반 문서분류 방법에는 Naive Bayes Classifier, Support Vector Machine(SVM), K-Nearest Neighbor(K-NN), Decision Tree, 신경망 등 여러 가지가 있다.
가. 나이브베이즈모델 개관
나이브베이즈모델(Naive Bayesian Classifier)은 문서분류에서 가장 보편적으로 사용하는 방식이다. 베이즈 정리를 이용하여 개발된이 알고리즘은 텍스트 분류에서 신경망이나결정트리 학습과 비슷한 성능을 보여주며 자료량이 많아질수록 정확도가 높다. 기본적인아이디어는 주어진 문서를 입력 받은 뒤 그것이 각 카테고리에 할당될 확률을 계산하는 방법이다. 문서가 특정 카테고리에 속하는 확률을 계산하기 위하여 식 (1)과 (2)와 같이 베이즈 정리를 이용한다.
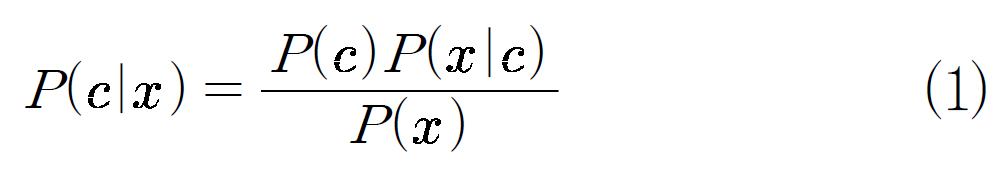
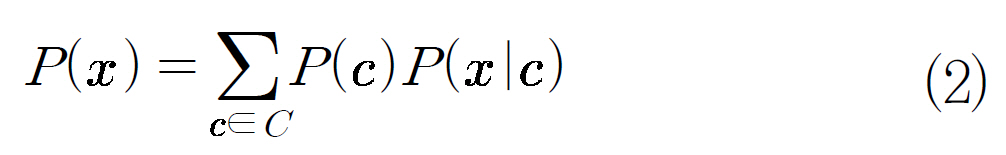
여기서 x는 임의의 문서이며 c는 임의의 카테고리를 의미한다. 식(1)의 P(x)는 전확률공식(total probability formula)에 의해 식 (2)와 같이 재정의된다. 그런데 P(x)는 모든 카테고리에 대하여 같은 값을 가지므로 확률을 계산하는데 고려하지 않아도 된다. 따라서 식 (1)의 분자에 위치한 P(c)와 P(x'c)만 추정하면문서 x가 카테고리 c에 할당될 확률을 계산할수 있다. P(c)는 모든 카테고리 중 카테고리 c가 뽑힐 확률이다. 나이브베이즈모델은 스팸메일처리에서 많이 활용하고 있다. 스팸으로처리한 메일을 기준으로 앞으로 들어오는 문서가 스팸인지 아닌지를 판단하는 방식이다.알고리즘 앞에 naive라는 이름이 붙은 이유는문서 A에 a, b, c라는 단어가 있다고 할 때 b가 나타날 확률은 a나 c와 무관한 즉 독립적이라 가정하여 베이즈 정리를 대폭 단순화한것이다. 나이브베이즈모델은 일반적으로 문서분류 도메인에서 다른 알고리즘(의사결정 트리, k-nearest neighbor, 신경망 등)에 비해성능이 우수하다고 알려져 있다(Pedro Domingos 1996). 또한 문서 분류함수를 만드는 것이 간단하고 문서분류 속도도 상대적으로빨라 문서분류시스템에 많이 이용하고 있다(김명찬 2003).
나. 나이브베이즈모델 활용
정영미와 이용구(2005)는 문헌 내 단어에서 중의성 문제를 해소하여 검색 성능을 향상시키기 위해 나이브베이즈 분류기를 적용한실험을 수행하였다. 실험 결과 나이브베이즈분류기를 적용한 실험에서 92%의 정확률을나타내며 중의성 문제를 해소하였다. 또한 중의성 해소를 통한 의미기반 검색 성능은 실험알고리즘을 적용하지 않은 경우보다 상대적인정확률에서 7.4% 향상을 보였다.
정확률에서 7.4% 향상을 보였다.김판준과 이재윤(2007)은 미분류 문헌에 대한분류 성능을 향상시키기 위해 문헌 유사도를 자질로 사용하고 나이브베이즈 분류기와 지지벡터기계(Support Vector Machine, SVM)를 이용한 실험을 수행했다. 이 실험은 미분류 문헌을이용한 자동분류 성능 향상을 평가하는 것이 주된 목적으로 두 가지 분류 모델 모두에서 성능향상이 나타났다. 이 경우에 SVM이 나이브베이즈 분류기보다 성능 향상 폭이 크게 나타났다.
최근 웹 2.0 환경에서 나이브베이즈 분류모델을 사용하여 검색 성능 향상과 방법론적으로 상대적인 비교 우위를 검증한 연구들이있었다. 웹에서 몇 년간 많은 양의 콘텐츠가축적된 질문-답변 문서에 대한 검색 성능을향상시키는 연구에서 나이브베이즈 분류 모델이 사용되어 검색 성능 향상을 검증했다(연종흠, 심준호, 이상구 2010). 다음으로 소셜 북마킹 시스템에서 사용자가 입력한 태그에 대한 데이터를 추출하여 사용자가 스패머인지 아닌지를 예측하는 모델에 나이브베이즈 분류기가 사용되어 다른 방법보다 상대적으로 높은 성능을 보였다. 비교를 하기 위해 사용된방법들은 결정테이블(decision table, DT), 결정트리(decision tree, ID3), TAN(tree-augmented naive Bayes) 분류기, 인공신경망(Artificial Neutral Network) 등이었다. 나이브베이즈 분류기를 사용한 모델이 모델 생성시간과 AUC(Area Under the ROC Curve)에서 가장 높은 성능을 보였다(김찬주, 황규백2009).
다. 나이브베이즈모델을 적용한 협업 필터링
협업 필터링에 나이브 베이즈 분류기를 적용한 비교적 초기 연구에서 기존 상관관계 기반 협업 필터링 모델과 비교하여 더 높은 성능을 발휘하는 것을 검증하였다(Koji Miyahara, Michael J. Pazzani 2000). 여기에서는 협업 필터링을이용자 유사성에 기반한 모델과 아이템 유사성에 기반한 모델 두 가지에 걸쳐 적용하였다. 실험 결과 나이브베이즈 분류기를 적용한 각 협업필터링 모델이 기존에 상관관계를 이용한 협업필터링보다 높은 정확률을 나타냈으며 또한 이용자 기반 모델과 아이템 기반 모델을 혼합하였을 경우 더 높은 정확률을 나타냈다.
나이브베이즈 분류기를 적용한 협업 필터링을 향상시키기 위한 연구로는 구간 추정을 이용한 연구가 수행된 바 있다(Robles et al.2003). 이 연구에서는 UCI 저장소에 있는 마이크로소프트 익명 웹 데이터를 이용하여 기존 모델보다 성능이 향상됨을 증명했다.
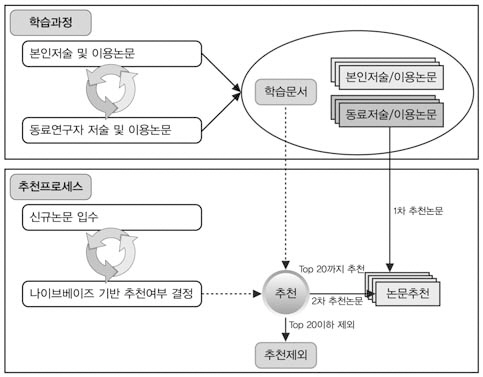
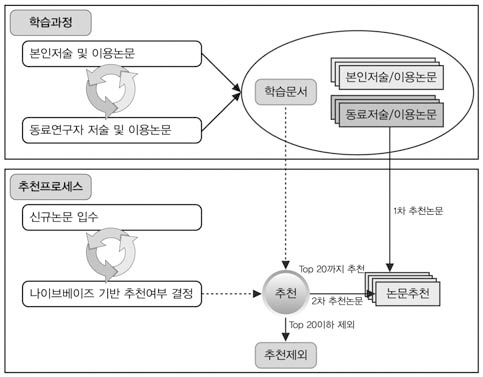
연구에서는 대규모 정보센터나 도서관에서 학술논문을 지능적으로 추천하기 위해 협업필터링 방식에 나이브베이즈모델을 결합한하이브리드 추천시스템을 제시하였으며, 학습과정과 추천프로세스는 <그림 3>과 같다. 먼저 학습과정은 본인이 저술한 논문이나 열람한 논문을 학술논문 DB와 로그파일을 통해 주기적으로 수집하여 초기 학습문서를 구축한다. 그리고 같은 논문을 열람한 관련분야 동료연구자나 공저자 관계에 있는 연구자들이 저술한 논문 또는 열람한 논문을 수집하여 학습문서에 추가한다. 이때 동료 연구자들이 저술한 논문이나 열람한 논문은 협업필터링 방식에 의거 추천대상 논문이 된다. 같은 문서를열람한 횟수가 많은 동료 연구자나 공저자 빈도에 따라 가중치를 달리 부여하고 이를 토대로 추천문서 우선순위를 산정하였다.
학술논문의 경우 최신성 및 적시성이 매우중요하고 대규모 정보센터나 도서관의 경우
정보량이 방대하기 때문에 전략적인 접근이필요하다. 본 연구에서는 효율성을 고려하여이전에 입수한 학술논문은 문서학습이나 협업필터링 추천에 활용하고 나이브베이즈모델은신규논문 추천에만 적용하였다. 신규논문이입수되면 협업필터링에 의해 이미 학습된 연구자 클래스의 자질을 나이브베이즈모델을 이용하여 유사확률을 계산한 후 상위 20편의 논문을 추천하도록 설계하였다. 추천논문은 학습문서에 즉시 추가되는 것은 아니며 추천한논문을 해당 연구자가 열람할 때 비로소 학습문서에 추가된다. 이용자별 학습문서(클래스)는 본인이 저술하거나 열람한 논문, 공저자 관계에 있거나 같은 논문을 열람한 동료 연구자가 저술 또는 열람한 논문으로 자동구축하고,자질(feature)은 학습논문의 키워드 항목에서추출하였다.
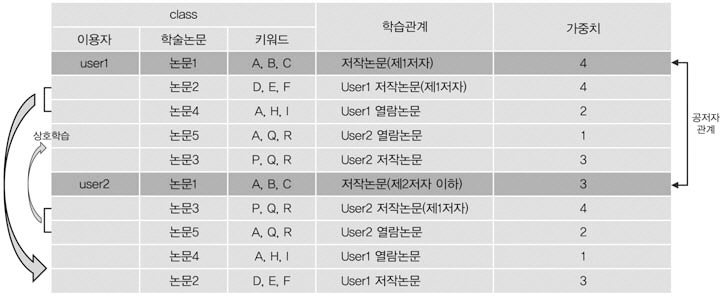
본인이 저술하거나 열람한 논문과 동료 연구자들이 저술하거나 열람한 학습논문을 같은 비중으로 다루지 않고 중요도에 따라 가중치를 달리 부여하였다. 즉, 본인이 제1저자인 학술논문에 최고점수인 4점, 공저자 또는 동료 연구자들의 저술 논문에 3점, 본인이 열람한 논문에 2점, 동료 연구자가 열람한 논문에 1점을 부여하였다. 아울러 동료 연구자라도 여러 개의 논문을 같이 열람했거나 공저자 빈도가 높을수록 가중치를 달리하였다. 즉, User1과 User2의 공저자 회수가 2회인 경우 x2를 하여 가중치를배가하였다. 이렇게 부여한 가중치는 협업필터링에 의한 추천논문 순위결정이나 나이브베이즈모델의 자질선정에 큰 영향을 미친다.
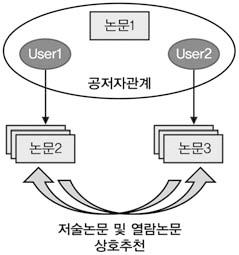
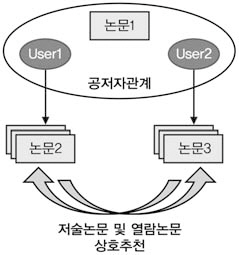
가. 공저자에 의한 논문추천 및 학습과정
공저자에 의한 추천과정은 <그림 4>와 같이 User1과 User2가 논문1을 공동으로 저술
한 경우 User1과 User2는 공저자 관계에 있으며, 이들이 저술한 논문이나 이후 열람한 논문은 상호추천 대상이 된다.
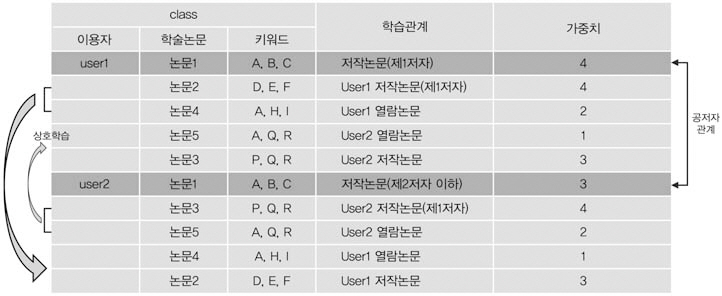
학습과정은 <그림 5>와 같이 User1은 공저자 관계에 있는 User2가 저술한 논문3과 열람한 논문5를 학습하고, 반대로 User2는 User1이 저술한 논문2와 열람한 논문4를 학습한다.이들 논문은 동시에 추천논문이 되며, 추천품질 및 우선순위를 고려하여 중요도에 따라 가중치를 달리하였다. 즉, User1이 제1저자인논문1에는 가중치 4를 부여했으며, 같은 논문
이지만 User2의 경우 제2저자인 관계로 가중치 3을 주었다. 또한 본인이 열람한 논문인User1의 논문4와 User2의 논문5는 가중치가2인 반면, 상대방이 열람한 논문은 최저 수준인 1을 부여하였다.
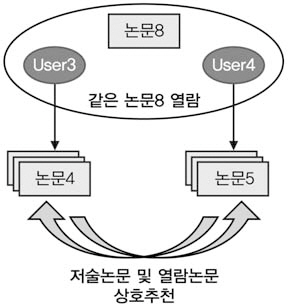
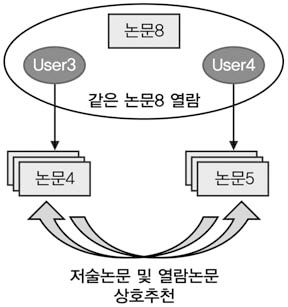
나. 동료 연구자에 의한 논문추천 및 학습과정
<그림 6>은 동료 연구자에 의한 논문추천 및학습과정을 도식화한 것이다. User3과 User4가 논문8을 같이 열람한 경우, User3과 User4
는 연구 분야가 유사한 동료 연구자로 볼 수있으므로 이들이 저술하거나 열람한 논문을상호 추천하였다.
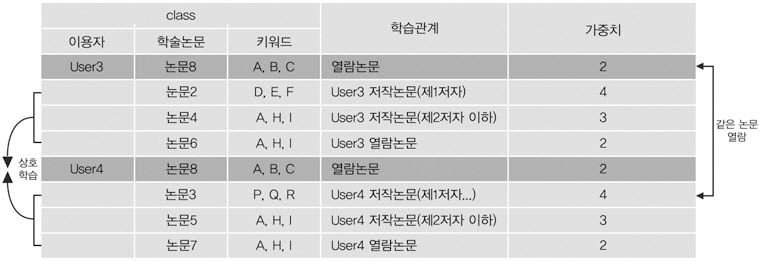
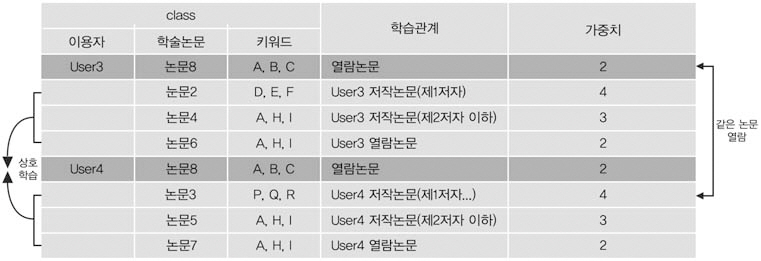
동료 연구자에 의한 학습과정은 <그림 7>과 같이 User3은 자신이 저술하거나 열람한논문2, 4, 6을 User4에게 학습하고, User4는자신이 저술하거나 열람한 논문3, 5, 7을User3에게 학습한다. 이들 논문은 이후 상호추천논문이 되며 공저자 관계에서와 마찬가지로 중요도에 따라 가중치를 달리하였다.
가. 나이브베이즈모델 유사확률 계산 알고리즘
본 연구에 적용한 나이브베이즈모델의 유사확률 계산 알고리즘은 다음과 같다. 나이브베이즈모델에서 문서 D가 C클래스일 확률은P(D) = P(t1, t2, …, tn), P(C'D) = P(C't1,t2, …, tn) = ( P(C)*(t1, t2, …, tn'C)) /P(t1, t2, …, tn)로 정리할 수 있다. 예를 들면 학습문서 4개가 있고 2개의 클래스로 구성되었다고 가정하면(A, B, …, F는 각 문서의키워드) 다음과 같이 나이브베이즈 확률을 계산할 수 있다.
(User1) 문서1 : A, B, A
(User1) 문서2 : A, A, C
(User1) 문서3 : A, D
(User2) 문서4 : F, E, A
각 키워드의 확률을 계산하면
P(A ' User1) = (User1에서 A의 출현횟
수 / User1의 전체 단어수) = 5/8
P(B ' User1) = 1/8
P(C ' User1) = 1/8
P(D ' User1) = 1/8
P(E ' User1) = 0/8
P(F ' User1) = 0/8
P(A ' User2) = (User2에서 A의 출현횟
수 / User2의 전체 단어수) = 1/3
P(B ' User2) = 0/3
P(C ' User2) = 0/3
P(D ' User2) = 0/3
P(E ' User2) = 1/3
P(F ' User2) = 1/3
P(User1) = 3/4
P(User2) = 1/4이다.
만약, 신규문서가 A, A, A, F, E라는 키워
드로 구성되었다고 가정하면
P(User1 ' 신규문서) = 3/4 * 5/8 * 5/8
* 5/8* 0/8 * 0/8
P(User2 ' 신규문서) = 1/4 * 1/3 * 1/3
* 1/3* 1/3 * 1/3이 된다.
그런데 위에서와 같이 빈도수가 0이면 이값으로 인해 모든 확률값이 0이 되므로 본 논문에서는 이를 방지하기 위해 분자에 +1을 하고 분모에 전체 학습문서 자질수를 +하였다.예를 들면 P(E ' 클래스1) = {(클래스1에서 E의 출현횟수 + 1) / (클래스1의 전체 키워드 +학습문서 자질 수)} = (0+1)/(8+6)로 보정하였다. 이를 적용하면 다음과 같다.
P(User1 ' 신규문서) = 3/4 * 5/14 *5/14 * 5/14 * 1/14 * 1/14 = 0.0001743 135
P(User2 ' 신규문서) = 1/4 * 1/9 * 1/9* 1/9 * 1/9 * 1/9 = 0.0000042338로 신규문서는 User2보다 User1에 훨씬 더 유사하다는 것을 알 수 있다.
나. 신규논문 추천 프로세스
대규모 정보센터나 도서관의 경우 정보량이방대하기 때문에 과거문서까지 소급하여 추천하는 것은 매우 비효율적이다. 본 논문에서는최신성과 적시성이 중요한 학술논문의 특성을고려하여 신규로 입수하는 학술논문에만 나이브베이즈모델을 적용하였으며, 학습문서 및자질은 협업필터링 방식을 통해 지속적으로자동 구축되도록 설계하였다.
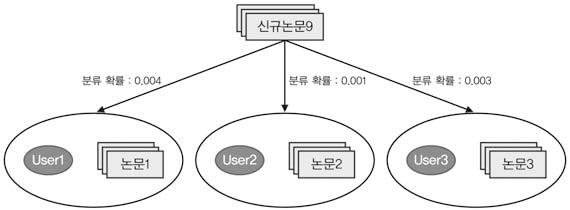
신규논문이 입수되면 나이브베이즈모델로확률값을 계산하고 각 이용자별 상위 20개 논문을 추천한다. 즉 <그림 8>에서와 같이 신규논문9가 입수되면 나이브베이즈모델로 확률값
을 계산하여 어떤 이용자에게 추천하는 것이적정한지를 판단하고, 추천한 논문을 이용자가 열람하면 그 시점에서 자동적으로 학습문서에 포함되도록 모델링하였다.
본 모델을 검증하기위해 한국과학기술정보연구원의 NDSL 학술논문과 이용로그를 활용

이용 빈도가 높은 학술논문 순위
하여 실험하였다. 한국과학기술정보연구원에는현재(2010.8) 5천만여 건의 해외학술논문과 1백만여 건의 국내학술논문이 구축되어 있으며,60만여 명의 회원이 이를 이용하고 있다. 실험에 사용된 데이터는 최근 3년간(2007~2009)의 NDSL 이용로그를 분석하여 이용 빈도가높은 학술논문 약 3천 5백 건을 먼저 추출하고, 이를 많이 이용한 식품과 전기 분야 연구자 상위 5명을 선정하였다.
<표 1>은 이용 빈도가 높은 상위 3천 5백편의 학술논문 목록이며, 본 논문의 연구자 식별에 이용하는 e-mail 등은 보안상 비공개 처리하였다.
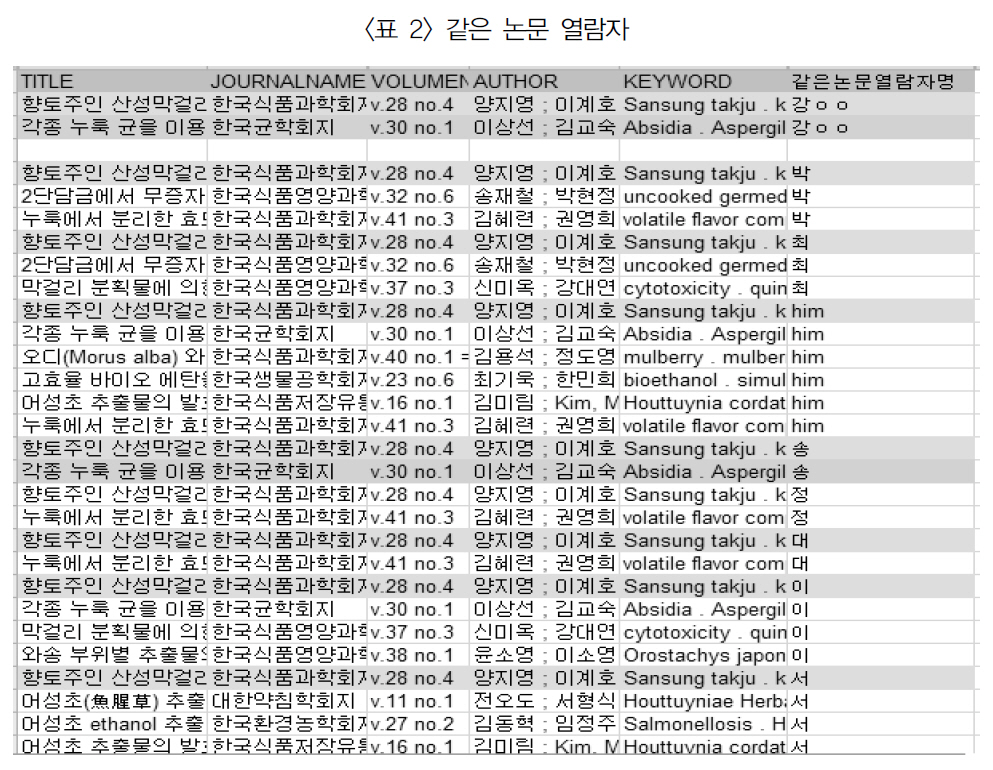
<표 2>와 같이 실험 대상자 5명 중 한명인강○○ 연구자는 식품분야 국내논문 2편, “향토주인 산성막걸리의 미생물학적 고찰과 저장성에 관한 연구”와 “각종 누룩 균을 이용한 실험실 조건에서의 막걸리 제조”를 열람하였으며, 같은 논문을 열람한 동료 연구자는 각각15명과 16명으로 나타났다.
동일한 논문을 열람한 연구자들은 연구 분야가 유사한 동료 연구자일 확률이 높으므로
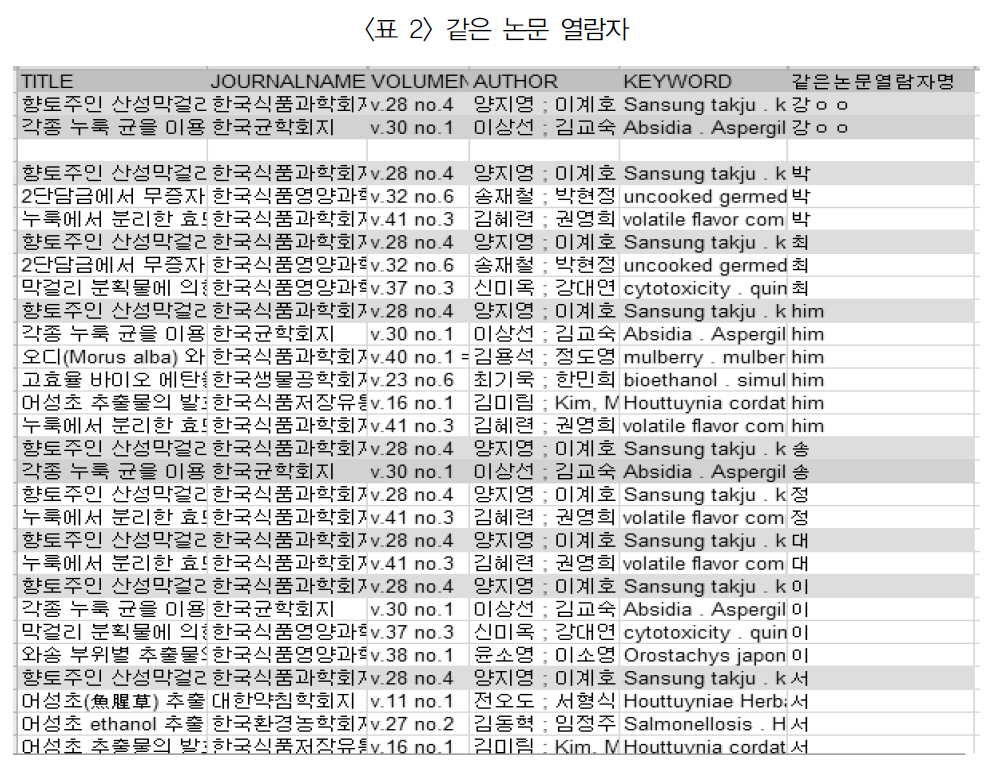
같은 논문 열람자
이들이 저술하거나 열람한 논문을 상호 추천하였다. 즉 박○○ 연구자의 경우 총3편의 논문을 열람하였으며 강○ 연구자와 같이 열람한 “향토주인 산성막걸리의 미생물학적 고찰과 저장성에 관한 연구”를 제외하고 박○○연구자만 열람한 2편의 논문, “2단 담금에서무증자 발아현미를 이용한 막걸리 제조”와“누룩에서 분리한 효모를 이용한 찹쌀발효주의 이화학적 특성 및 휘발성 향기성분”을 강○○ 연구자에게 추천하였다.
이에 비해 송○○ 연구자의 경우 강○○ 연구자와 2편의 같은 논문을 열람하여, 박○○에 비해 훨씬 연구 분야가 밀접하므로 <표 4>에서와 같이 가중치를 달리 부여하여 송○○연구자가 저술하거나 열람한 논문의 추천 우선순위를 산정하였다.
<표 3>은 가중치를 전혀 고려하지 않고 강○○에게 추천한 논문 우선순위로, 강○○가열람하거나 저술한 논문을 동료 연구자들이얼마나 많이 열람했는지? 열람 횟수를 토대로추천한 논문 우선순위이며, <표 4>는 가중치를 적용한 추천논문 우선순위이다. <표 3>과<표 4>의 추천논문 우선순위를 비교해 보면,

가중치 미적용 추천논문 순위

가중치 적용 추천논문 순위
가중치를 적용한 경우와 적용하지 않은 경우추천논문 우선순위에 많은 변화가 있는 것을알 수 있다. 추천시스템 목적이 대량의 정보자원 중에서 연구자에게 적합한 논문을 예측하여 제공하는 것이므로 우선순위는 매우 중요한 요소이다.
가중치를 적용한 추천논문과 그렇지 않은추천논문을 실험대상자 5명에게 이메일로 발송하고 조사한 결과, 참여자 모두 가중치를 적용하지 않은 것보다 가중치를 적용한 추천논문을 더 선호하는 것으로 나타났다.
나이브베이즈모델을 이용한 신규논문 추천품질도 협업필터링과 동일하게 식품과 전기분야 연구자 5명을 대상으로 실시하였다. 식품과 전기 분야 연구자로 나누어 선정한 이유는 연구영역이 확연히 구분되는 두 개 도메인
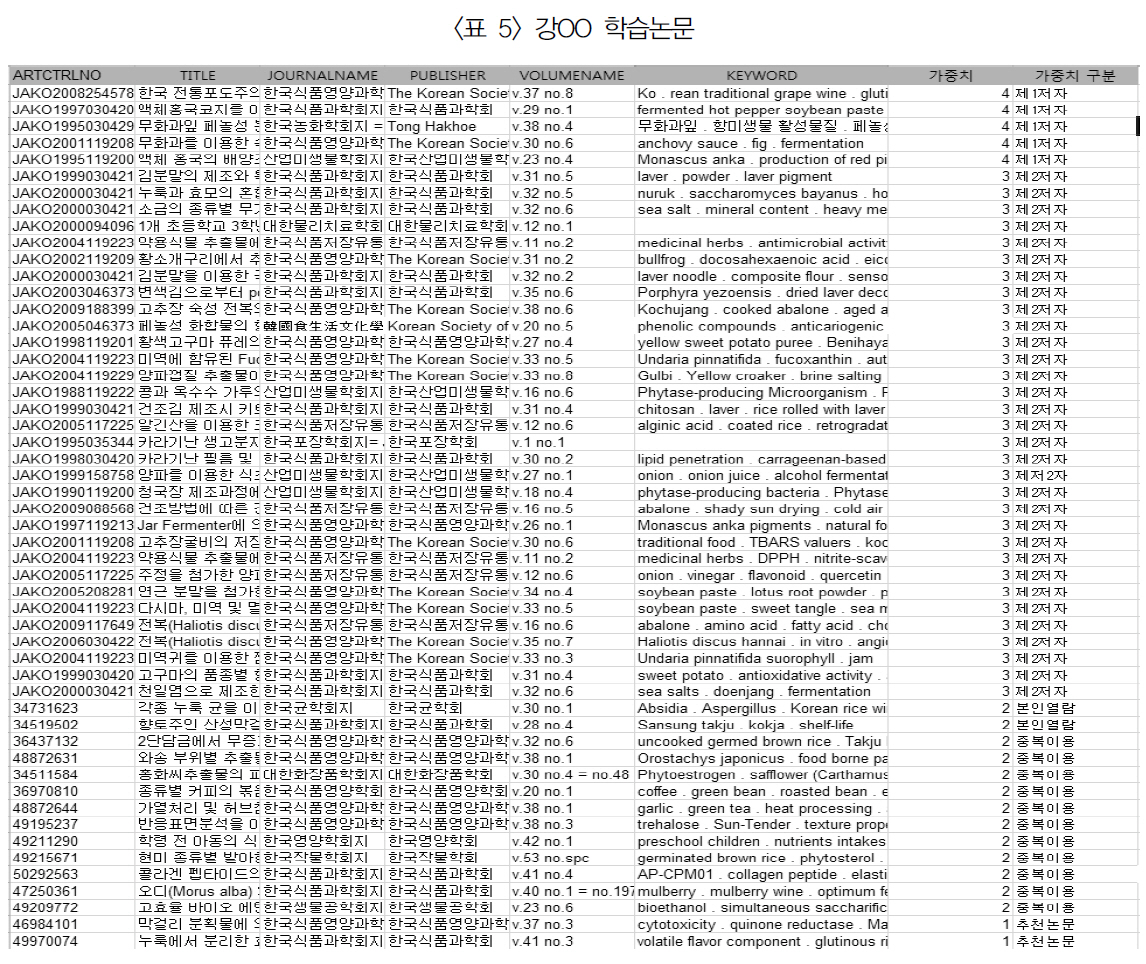
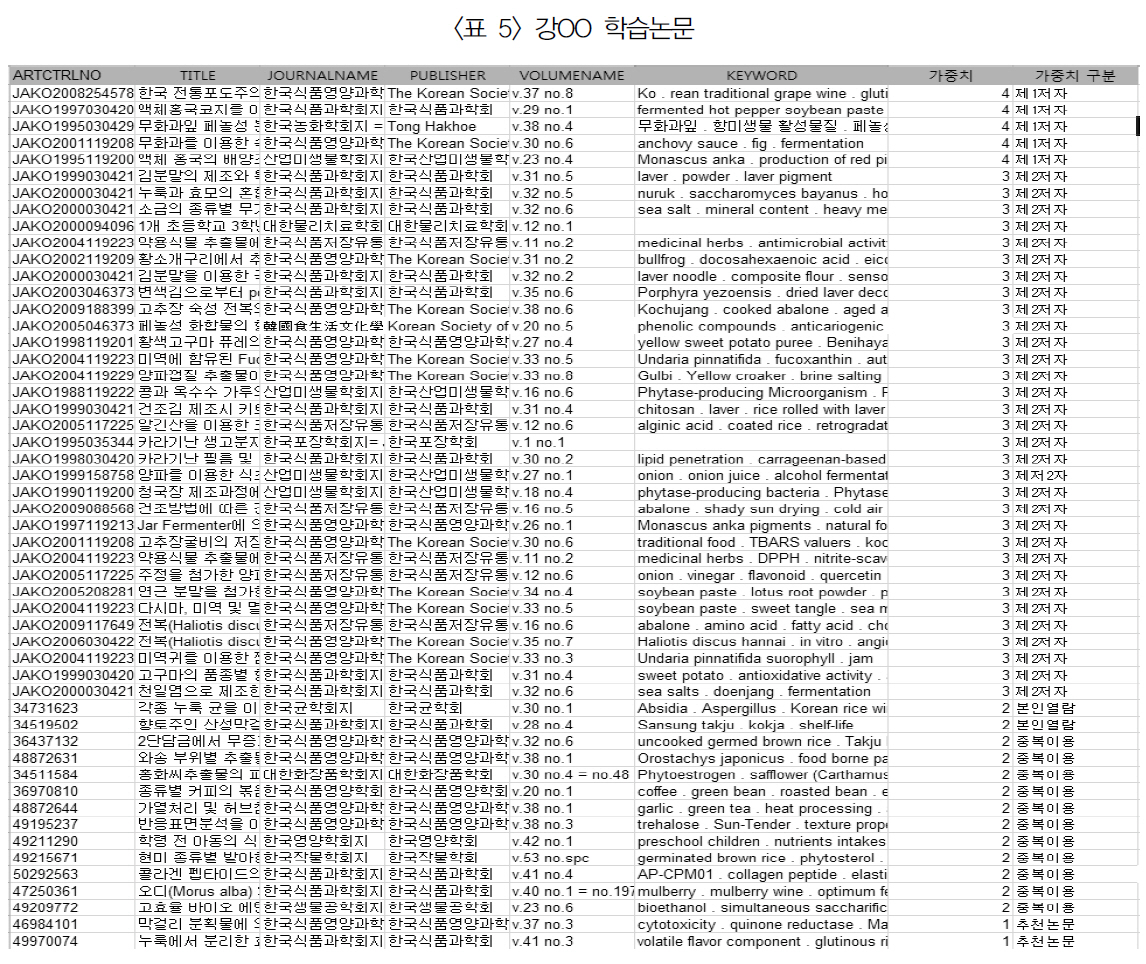
강OO 학습논문
을 비교하기 위해서다. 실험에 이용한 논문은금년도(2010) 6월까지 NDSL에서 신규 구축한 국내학술논문 중 5명의 실험 대상자와 관련성이 높은 11개 학술지(한국식품영양과학회지, 한국식품과학회지, 한국식품저장유통학회지, 대한화장품학회지, 한국조리과학회지, 한국전기화학회, 대한전자공학회, 한국자동차공학회, 대한기계학회, 한국전기화학회, 한국전기전자재료학회)에 수록된 980건의 논문을 대상으로 실시하였다.
<표 5>는 연구 분야가 식품인 강○○의 학습 클래스로 총71편의 논문을 학습하였다.
즉, 본인이 저술한 논문 4편, 공저자 논문 32편, 본인열람 2편, 동료 추천논문 33편이다.
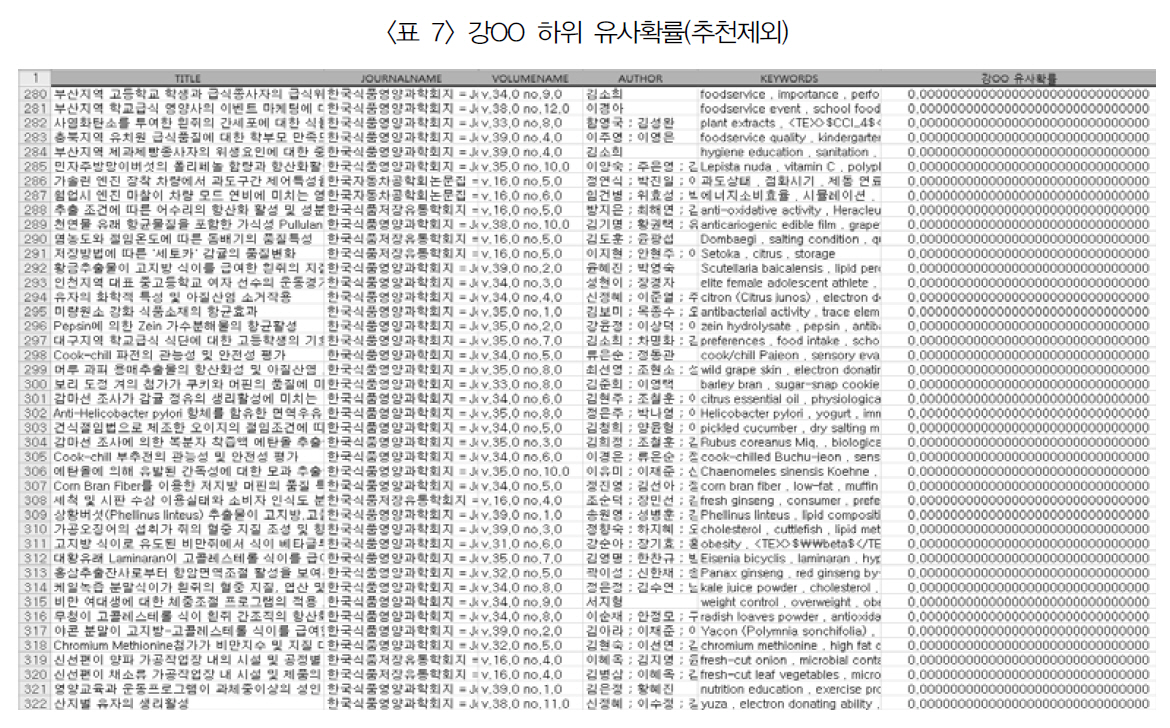
강○○ 학습논문 71편의 키워드를 추출하여 자질을 구성한 다음 나이브베이즈모델로신규논문 980편과 유사확률을 계산한 결과,<표 6>과 같이 한국식품영양과학회지 논문이대부분 상위에 랭크되었으며, <표 7>에서와

강OO 상위 유사확률(추천대상)
강OO 하위 유사확률(추천제외)
같이 같은 저널의 논문이라도 연구 분야와 동떨어지거나 전혀 관련이 없는 한국자동차공학회 논문은 하위에 랭크된 것을 볼 수 있다.
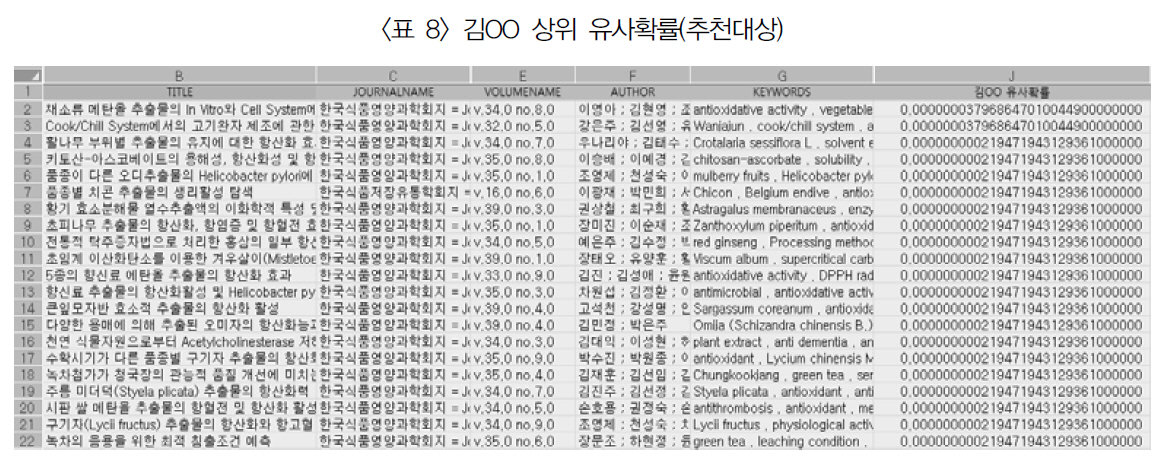
<표 8>은 식품분야의 또 다른 실험 대상자인 김○○ 연구자에 대한 나이브베이즈모델기반 신규 논문의 유사확률로 강○○ 연구자와는 확연히 다른 결과를 보여주고 있다. 이는
김OO 상위 유사확률(추천대상)
협업필터링을 통해 학습한 논문이 다르고 이를 통해 추출한 자질도 상이하기 때문에 발생하는 당연한 결과다.
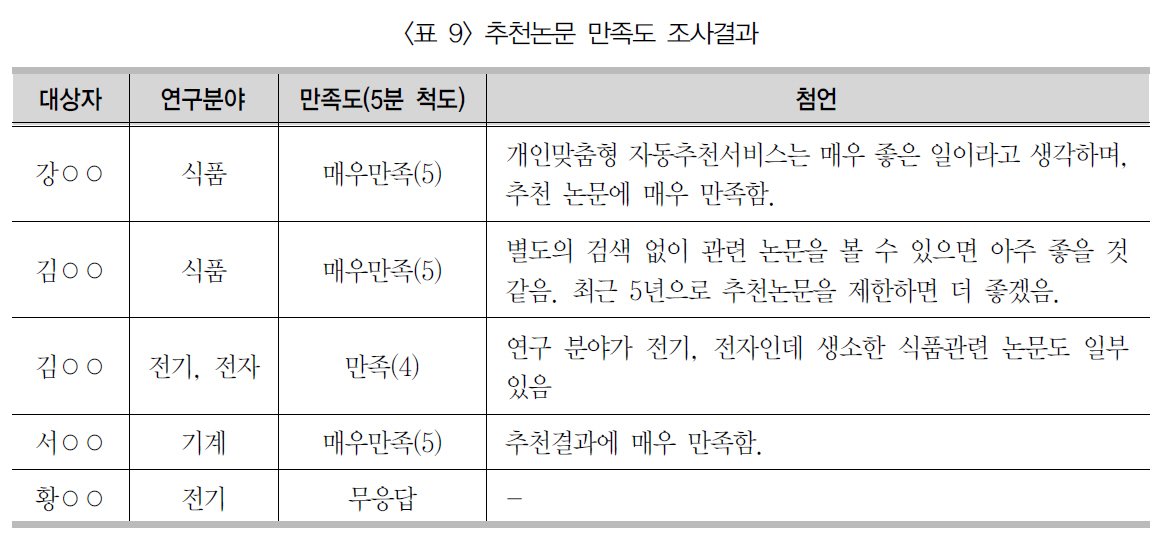
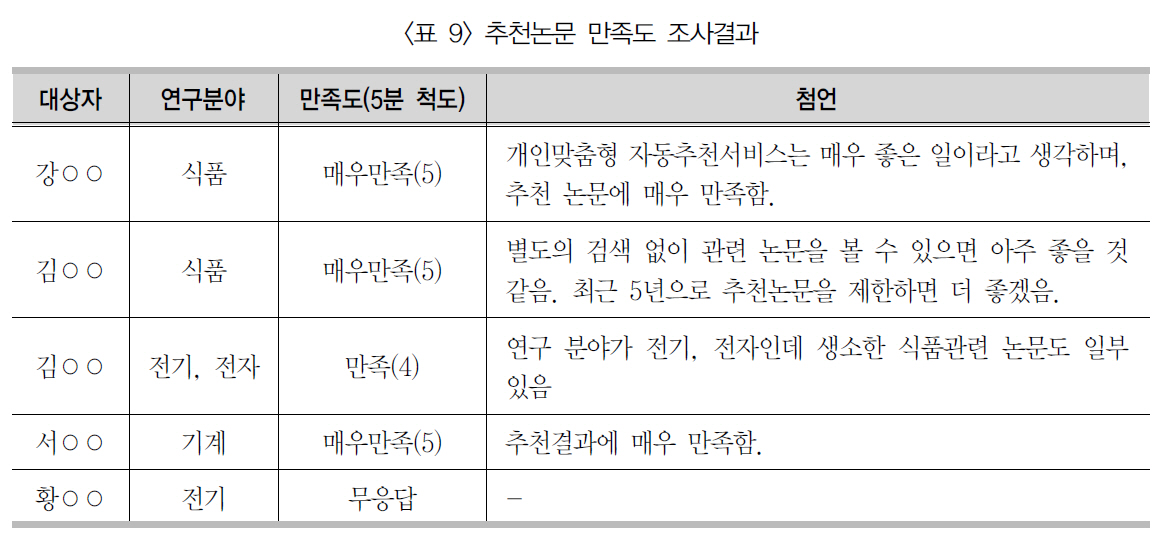
본 모델을 이용하여 실험대상자 5명 각각에대하여 상위 20편의 추천논문을 생성한 다음,추천논문 리스트를 이메일로 발송한 후 5점척도(매우만족 5, 만족 4, 보통 3, 불만족 2,
추천논문 만족도 조사결과
매우 불만족 1)로 만족도를 조사한 결과 <표9>와 같이 상당히 만족(4.75)하는 것으로 조사되었다. 특히, 식품분야 연구자들이 전기 분야 연구자들보다 만족도가 더 높게 나타났다.이것은 실험대상자에 포함된 식품분야 연구자들이 전기 분야 연구자들보다 더 많은 논문을저술하고 NDSL을 많이 이용함으로써, 협업필터링 방식에 의거 더 많은 논문 상호추천과 논문을 학습한 결과다.
이용자들이 원하는 정보를 예측하여 관심가질만한 정보를 자동으로 추천하는 시스템은전문가시스템, 데이터마이닝, 정보검색 등 다양한 분야에서 오래 전부터 연구하여 왔다. 최근에는 콘텐츠기반추천시스템과 협업필터링을결합하거나 다른 분야 모델을 접목한 하이브리드 추천시스템 연구에 치중하고 있다.
본 논문은 기존 추천시스템 문제점을 해결하고 대규모 정보센터나 도서관에서 효율적,지능적으로 학술논문을 추천할 수 있도록 협업필터링과 나이브베이즈모델을 결합한 새로운 방식의 추천모델을 제시하였다. 본 방식은관심사항이나 프로파일을 별도로 등록 관리하지 않더라도 협업필터링을 통해 동료 연구자들이 저술하거나 열람한 논문을 자동으로 추천 및 학습할 수 있다. 아울러 기존 콘텐츠기반추천시스템의 과도한 특성화(Over-specialization)문제와 이용로그나 평가정보가 축적되기 전까지 신규논문을 추천할 수 없었던 협업필터링 방식의 문제점을 동시에 해소하였다.
본 모델을 한국과학기술정보연구원 ‘NDSL학술논문’에 적용하여 실험하였다. 실험은 식품과 전기 분야 11개 국내 학술지를 대상으로하였으며 현재 NDSL을 이용하는 해당분야 연구자 4명에게 피드백을 받은 결과 추천논문에대체로 만족(4.75)하는 것으로 나타났다. 향후시스템 성능을 보다 객관화하기 위해 실험대상을 확장하고, 다양한 분야에서 활동하는 연구자들을 활용하여 추천모델 성능을 개선하는추가적인 연구가 필요하다.