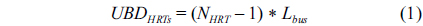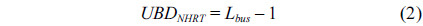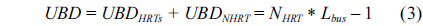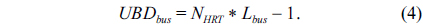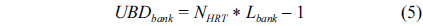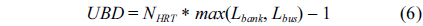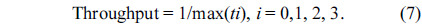Nowadays, multicore processors have reached the mainstream of chip design. However, for real-time systems, especially hard real-time systems, it is very challenging to accurately estimate worst-case execution time (WCET) on a multicore processor. This is because in addition to the complexity of WCET analysis for uniprocessors, the execution time of a thread can be significantly affected by other concurrent threads in a multicore platform due to inter-thread interference in accessing shared resources, such as shared buses and shared caches. This problem can significantly aggravate the complexity of multicore timing analysis, especially if there are a large number of cores, making WCET analysis for multicore chips extremely difficult, if not impossible.
To solve this problem, it is desirable to design a timepredictable multicore architecture that can adequately simplify the complexity of multicore timing analysis. The goal of designing this kind of system is to eliminate or easily bind the timing unpredictability caused by interthread interferences in accessing shared resources, while limiting the impact on performance and/or energy dissipation. Recently, Paolieri et al. [1] proposed a time-predictable architecture to provide hardware support for WCET analysis of hard real-time multicore systems. They developed a statically-partitioned, shared L2 cache and an arbiter mechanism to access the bus and the cache to either avoid or maximally bind the interference due to accessing shared resources, and from this, the WCET of real-time threads running on this multicore architecture can be derived. The work of Paolieri et al. [1] was one of the earliest to design time-predictable multicore architectures for hard real-time systems by considering both cache and bus interferences. However, their work did not explore multicore architectures with separate L1 and L2 caches, which, based on our study presented in this paper, can also achieve time predictability and actually have better performance and energy efficiency.
We quantitatively compare the partitioned-cache architecture, which had been studied by Paolieri et al. [1], with separate-cache architectures and separate buses using extensive simulations. Our experiments quantitatively indicate that the separate-cache architecture, although simple in design, actually results in superior performance and energy efficiency for all real-time and Standard Performance Evaluation Corporation (SPEC) 2006 benchmarks we employed. Considering that both separate and partitioned- cache architectures are suitable for complexityeffective timing analysis for hard real-time systems, our research reveals that instead of primarily focusing on developing elegant partitioned schemes of shared caches for hard real-time multicore systems, it is perhaps more meaningful to revisit multicore chips with separate caches in order to achieve time predictability with improved performance and energy efficiency.
>
A. Prior Works on WCET Analysis
WCET analysis has become an area of intense interest in the field of real-time systems in the last two or three decades. A recent survey provides an extensive review of the state-of-the-art techniques [2]. Most of the prior efforts, however, focus on WCET analysis for uniprocessors [3-5]. Recently, a number of efforts have been made to analyze WCET for multicore processors [6-13]. However, these studies are already very complex for multicore processors with a small number of cores (e.
>
B. Prior Works on Time-Predictable Architectures
The design of real-time systems with time predictability has been gaining increased attention. Reineke et al. [14] first studied the predictability of common cache replacement policies. They introduced three metrics to capture the behaviors of caches and gave quantitative, analytical results for the predictability of cache replacement policies. Edwards and Lee [15] developed an architecture named precision timed (PRET) machine which improved time predictability by fixing instruction execution times and balancing program paths to deal with repeatable concurrent behaviors. Hansson et al. [16] proposed proposed an approach named CoMPSoC to provide templates for the composition of predictable stream-processing architectures. Recently, Paolieri et al. [1] developed a partitioned shared L2 cache and a bus arbiter mechanism to reasonably bind the interference of shared resources and WCET for multicore processors. While the work of Paolieri et al. [1] was one of the earliest efforts to design time-predictable multicore architectures for hard realtime systems, their work did not explore the full cache design space to derive the best architecture to ensure time predictability while providing excellent performance and/ or energy consumption. Specifically, Paolieri et al. [1] did not consider a multicore architecture with separate L2 caches, which can also achieve time predictability. Our study demonstrates that a multicore architecture with separate L2 caches achieves better performance and energy efficiency than an equivalent multicore processor with a statically-partitioned L2 cache. While both separate and statically-partitioned caches are not new to the best of our knowledge, this is the first work to comparatively evaluate both the performance and energy efficiency of these two cache architectures for real-time multicore processors.
Ⅲ. SEPARATE VS. STATICALLY-PARTITIONED CACHE ARCHITECTURES
>
A. Multicore Processors with Separate L2 Caches
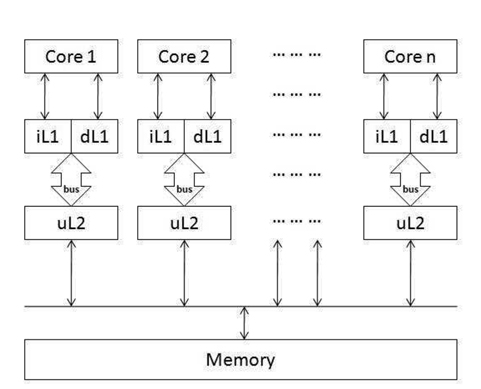
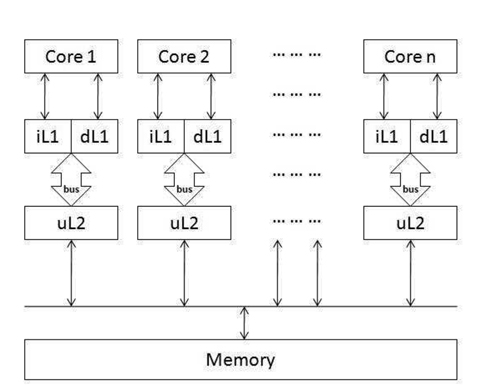
The first model that we study to achieve time predictability is a multicore processor with a separate L2 cache and bus system. Fig. 1 gives an overview of this architecture in which each core has its own L1 instruction and data caches as well as a private L2 cache. The L1 caches can access their own L2 cache through the private bus. All the L2 caches share access to the same memory.
In this separate-cache architecture, since there is no shared L2 cache, there is absolutely no inter-thread cache interference. As a result, the timing analysis for the cache subsystem is much easier and can be done by extending prior work on cache timing analysis for uniprocessors [5, 17].
Nevertheless, for the shared bus between the L2 cache and the memory, it may happen that two or more hard real-time tasks (HRTs) running on different cores attempt to access the bus at the same time. In this case, the
While an HRT bus request can be prioritized over an NHRT bus request if they are issued in the same cycle, it may happen that the HRT request arrives just one cycle after the request coming from the NHRT had been already granted access to the bus. In this case, the maximum delay an HRT can suffer from the NHRT (denoted as
Overall, the maximum delay of an HRT bus request depends on the combination of the effects of the bus requests from both HRTs and NHRTs, which can be calculated with Eq. (3).
In a manner similar to the work of Paolieri et al. [1], this paper focuses on addressing time unpredictability caused by shared caches and buses in a multicore platform, and we assume the shared memory is time-predictable. Therefore, based on the discussion above, the WCET of HRTs running on multicore processors with separate L2 caches can be predicted without incurring prohibitive complexity for timing analysis.
>
B. A Multicore Processor with a Statically- Partitioned L2 Cache
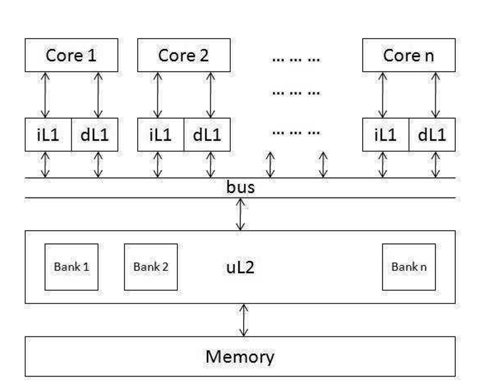
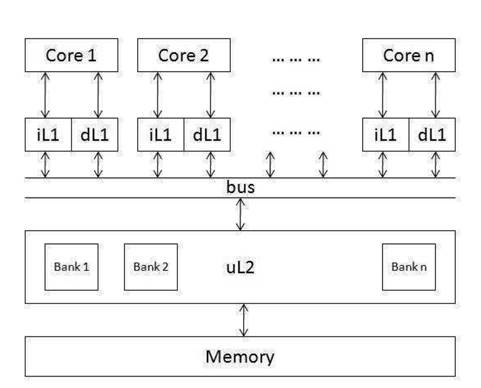
Another time-predictable architecture we comparatively evaluate is that of a multicore processor with a shared L2 cache and bus system. It is derived from the system designed by Paolieri et al. [1], and Fig. 2 gives an overview of this architecture. In this architecture, each core also has its own L1 instruction cache and L1 data cache. However, they share an L2 cache through a shared bus. To avoid inter-thread cache interference, the L2 cache is partitioned, and each core can only access a predefined set of cache banks. Just like in the separate-cache architecture, all the cores share access to the same memory as well.
[Fig. 2.] Model II: a multicore processor with a shared (and partitioned) L2 cache and a shared bus.
For the partitioned L2 cache architecture with a shared bus, the execution time of an application running on one of the cores must consider the interference from both the shared bus accesses and shared L2 cache accesses. According to Paoleri et al. [1], the
The
Since bank access typically takes a longer time than bus access, the bus latency can overlap while accessing the bank. However, if bank access takes less time than bus access, then the bank conflict effect can be hidden because the time to access the bank can be overlapped by the bus latency. Thus in general, the total
Paolieri et al. [1] have discussed two cache partitioning techniques, i.e., c
>
C. Comparison between Separate and Statically-Partitioned Caches
In this paper, we conduct extensive experiments to quantitatively compare the performance and energy consumption of the two aforementioned time-predictable multicore cache architectures to find out which one is better for real-time multicore computers. Relative to a statically-partitioned cache, a separate cache has the following advantages. First, a separate L2 cache is smaller than a centralized (yet partitioned) cache, thus a separate cache can have shorter access latency and lower power consumption per access. Second, in a separate-cache can lead to better performance and energy efficiency for the separate-cache architecture, a fact which is confirmed through our detailed simulations incorporating the cache and bus access latencies into a cycle-accurate multicore processor simulator. architecture, since each L1 cache can access the L2 cache through a private bus, the delay due to bus arbitration and interference per L1 miss is avoided. Both of these factors
On the other hand, a shared cache may use the aggregate cache space more efficiently since different threads may have different memory footprints and various memory access behaviors. However, this advantage does not hold in a statically-partitioned (though shared) cache, as each core can still only use a given set of cache banks (i.e., partitions) to avoid inter-thread cache interferences, unless the partition is performed through a dynamic and adaptive approach. The dynamic partitioning, however, would negatively affect the time predictability and hence may not be suitable for use in hard real-time systems.
To compare the performance and energy efficiency of these two cache architectures for use in hard real-time multicore processors, we made extensive experiments based on extended SimpleScalar 3.0 [18]. SimpleScalar is originally designed to simulate a superscalar uniprocessor. We extended this cycle-accurate simulator to simulate the two architectural models described in Section III. We used CACTI [19] to get the latencies of the L1 and L2 caches and energy consumption per access, and these values were incorporated into the simulator to derive the final execution time and energy dissipation.
In our experiments, we simulate two four-core processors, one with the partitioned L2 cache and another with the separate L2 caches. The L1 instruction and data caches are private to each core in both processors. To make a fair comparison, we evaluate multicores with partitioned caches and separate caches that have the same aggregate cache size, block size, set associativity, and replacement policy.
Generally, there are two different cache partition techniques controlled via software: columnization and bankization. While columnization partitions the cache into columns, bankization partitions the cache into banks. As discussed by Paoleri et al. [1], in columnization, different threads can still access the same bank, leading to bank access conflicts. In contrast, bankization can successfully avoid the bank access conflicts and lead to tighter WCET estimation. Therefore, in this work, we only implement the bankization technique in our simulator to evaluate the partitioned-cache architecture. We also assume that the bus access time without any interference takes two CPU cycles and the bus arbitrator takes one CPU cycle.
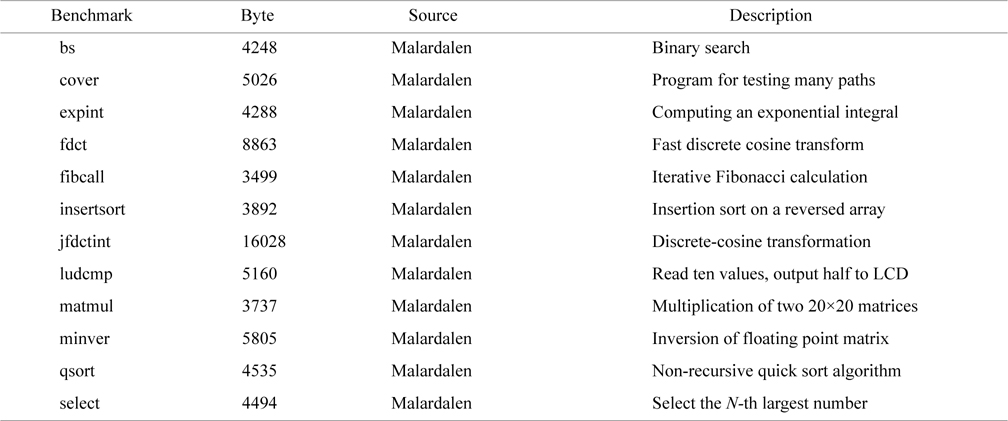
For HRTs, we use real-time benchmarks from Malardalen WCET benchmarks [2], listed in Table 1. The cache configuration for these benchmarks is shown in Table 2. The latency and energy in the table is calculated using CACTI [19].
[Table 1.] Real-time benchmark characteristics and description
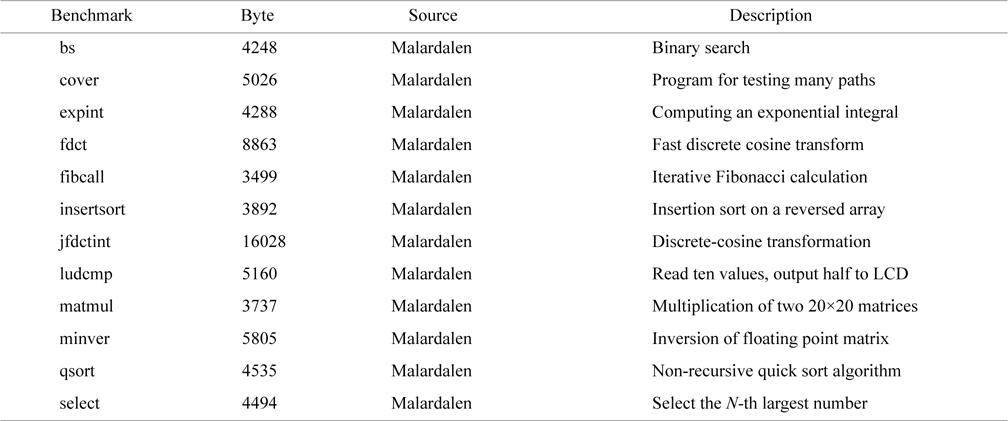
Real-time benchmark characteristics and description

Configuration I for separate and statically partitioned-cache architectures of the four-core processor used to evaluate Malardalen real-time benchmarks
To ensure the generality of our comparative evaluation, we also randomly select some benchmarks from SPEC CPU2006 [20], which is an industry standardized CPUintensive benchmark suite. The selected SPEC CPU2006 benchmarks are used to represent typical non-real-time applications, listed in Table 3. Since the SPEC 2006 benchmarks are much larger than the real-time benchmarks, we use the cache configuration (i.e., configuration Ⅱ) shown in Table 4 for SPEC 2006 benchmarks.
[Table 3.] SPEC CPU2006 benchmark description

SPEC CPU2006 benchmark description

Configuration II for separate and statically partitioned-cache architectures of the four-core processor evaluated with the SPEC CPU2006 benchmarks
>
A. Performance and Energy Consumption Comparison of Real-Time Benchmarks
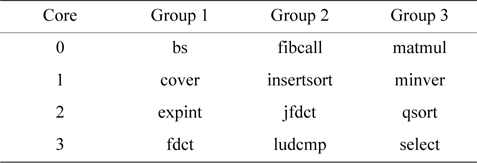
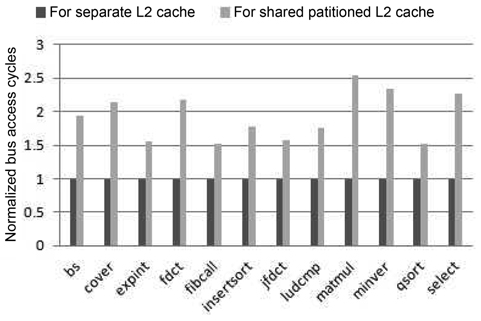
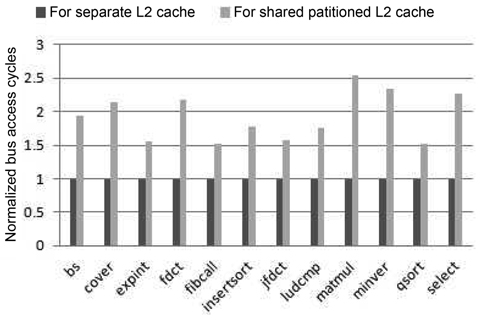
We divide the real-time benchmarks into three groups with four benchmarks per group. Each of the four benchmarks in a group runs on one of the four cores, and the assignment of a benchmark to a core is based on the order shown in Table 5. Fig. 3 compares the bus access cycles of every real-time benchmark between these two models of cache architectures. As we can see, the number of bus access cycles of the partitioned cache is at least 50% larger than that of the separate cache. This is because whenever there is an L1 miss, either it is an L1 instruction cache miss or an L1 data cache miss, and access to the L2 cache or even the main memory is then necessary. In the separate-cache architecture, the L2 cache can be directly accessed through the private bus of each core without any inter-thread interference. By comparison, in a partitioned-cache architecture, since the centralized L2 cache structure is shared by different cores through the shared bus, the bus access latency becomes much longer due to both arbitration and waiting delay. It should be noted that in a separate L2 cache architecture, different L2 caches need to compete for the bus to access shared memory. However, this only happens for each L2 miss, which occurs much less frequently than an L1 miss.
[Table 5.] Real-time benchmark test groups in our experiments
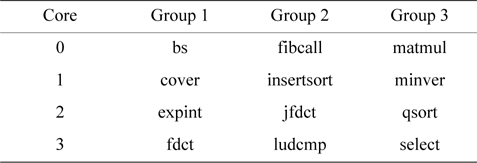
Real-time benchmark test groups in our experiments
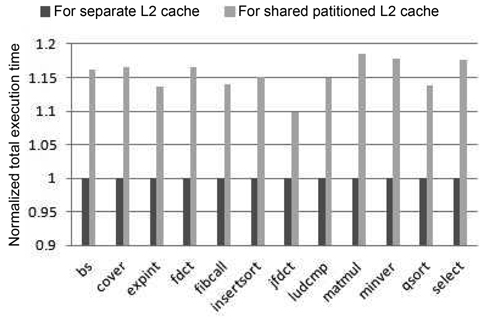
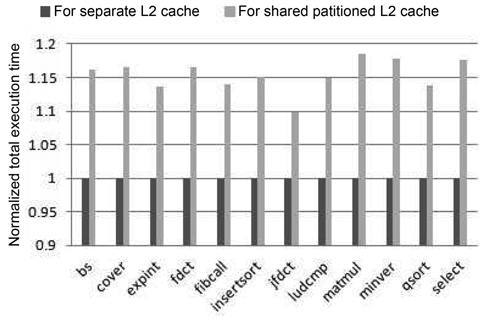
Fig. 4 compares the total execution time of the realtime benchmarks between these two cache architectures. We observe that the execution time of the partitioned-L2- cache model is at least 9.8% longer than that of the separate- cache architecture. This is mainly because the separate- cache architecture has lower latencies in both bus accesses and L2 accesses than the partitioned-cache architecture, leading to overall better performance.
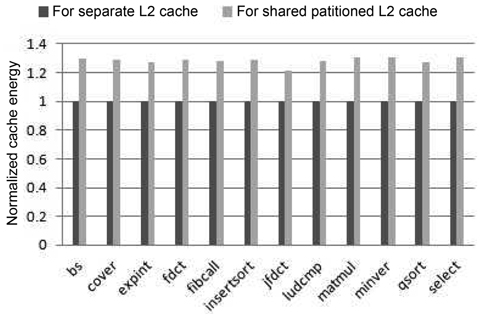
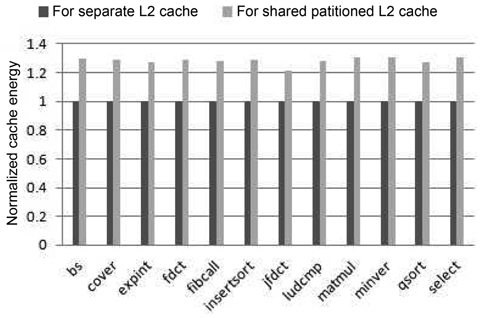
Fig. 5 shows the comparison of the total cache energy consumption of during real-time benchmarks between these two cache architectures. As can be seen in this figure, the energy dissipation for the partitioned-L2-cache model is at least 21% larger than the separate one. This is because the shared partitioned cache consumes both more dynamic energy per access and more leakage energy due to the longer execution time.
To compare the performance of the two architectures’ performance, we also calculated the throughput of the systems for the three benchmark groups by using Eq. (7), where it is the execution time of the benchmark running on the ith core of the system. In Fig. 6, we can see that the throughput of the shared partitioned-L2-cache model is 87% that of the separate one at most, which confirms the performance superiority of the separate-cache architecture.
In summary, from the above evaluation and analysis, we conclude that both the performance and energy efficiency of the separate-L2-cache architecture are much better than those of the statically partitioned-L2-cache architecture for the real-time benchmarks used in our simulation.
>
B. Performance and Energy Consumption Comparison of SPEC CPU2006 Benchmarks
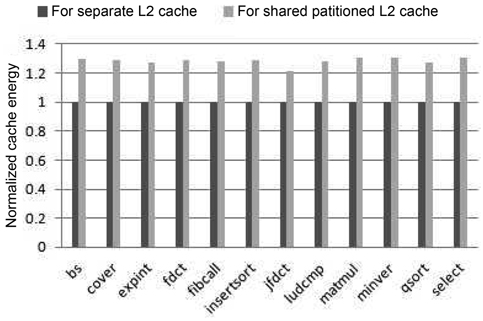
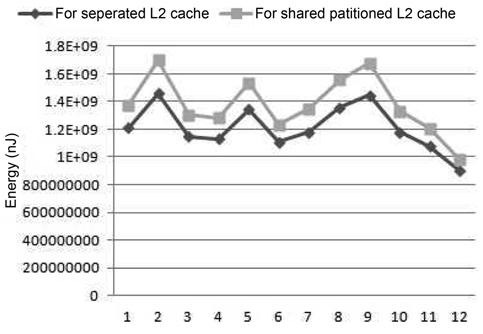
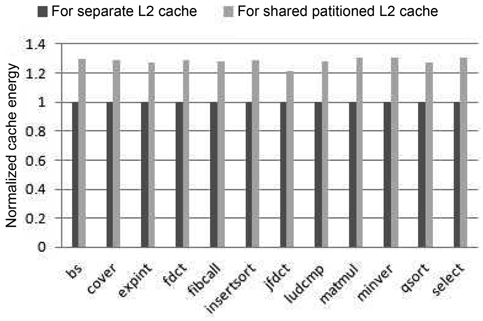
We have run 12 groups of SPEC CPU2006 benchmark combinations as shown in Table 6. Fig. 7 gives the total cache energy consumption of the four-core processor with both cache architectural models. As can be seen, the energy consumed by the partitioned-L2-cache architecture is higher than that of the separate-cache architecture for the SPEC 2006 benchmarks as well. Specifically, the cache energy consumed by the partitioned L2 cache is at least 9% larger than that of the separate cache.
[Table 6.] SPEC CPU2006 benchmark test groups in this experiment

SPEC CPU2006 benchmark test groups in this experiment
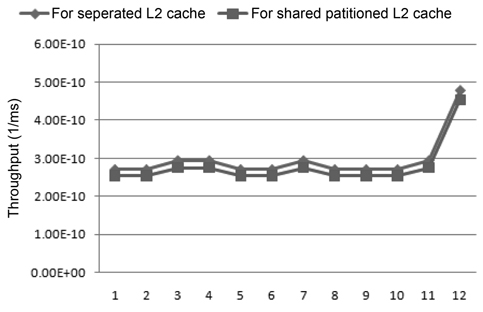
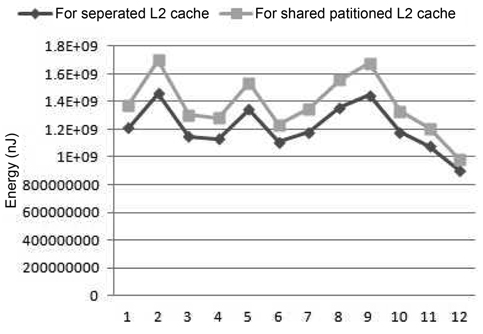
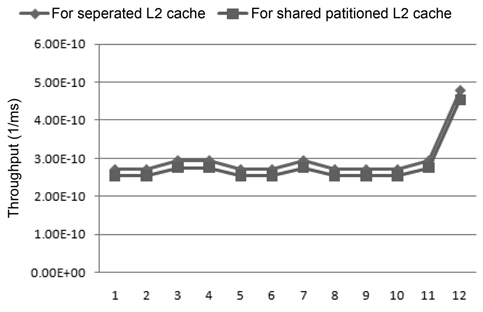
In addition to the energy results, we also compared the throughput between these two cache architectures using the SPEC 2006 benchmarks, seen in Fig. 8. We observe that for those SPEC 2006 benchmarks, the throughput of the shared partitioned-cache architecture is about 93% that of the throughput of the separate-cache architecture. Therefore, the same conclusion can be made as a result of both real-time and SPEC 2006 benchmarks which is that the separate-cache architecture is superior to the statically partitioned-cache architecture in terms of both performance and energy efficiency
This paper quantitatively compares two types of timepredictable multicore cache architectures. One involves a multicore processor with separate L2 caches, and the other is that of a multicore processor with a shared but statically-partitioned L2 cache, both of which are suitable for worst-case timing analysis. This paper focuses on comparatively evaluating the performance and energy efficiency of both cache architectures, and our experimental results indicate that due to faster bus access and shorter L2 access latency, the separate-cache architecture is superior in both performance and energy consumption in real-time and SPEC 2006 benchmarks, and thus is preferable for a multicore-based hard real-time systems.
It should be noted that this work only compares separate L2 caches with a statically, evenly-partitioned L2 cache on a four-core processor. Generally, shared L2 cache can be partitioned in different ways, which may improve the efficiency of the cache space utilization when the partition matches the cache access behavior of the concurrent programs. However, due to the timing and energy efficiency per access to a smaller separate cache in conjunction with the scalability of the separate cache design, we believe the separate-cache architecture have significant advantages over statically-partitioned caches in achieving time predictability as well as good performance and energy efficiency during real-time multicore computing.
In future work, we would like to measure the execution time and energy dissipation on real, multicore processors with different cache architectures to further the comparative evaluation. Also, we would like to vary the number of cores to study the performance trends of these two cache architectures with respect to an increased number of cores.